本文主要是介绍小车PCB板视觉分拣软件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
小车PCB板视觉分拣软件
- 前言
- 赛题内容
- 视觉算法
- 算法选择
- 算法实现过程
- 读入Train并创建模板
- 读入Test数据
- 图像预处理与视觉分拣
- 实际效果
- 指定读入
- 顺序读入
- 其他
- UI界面设计
- 数据库
- DEMO分享
前言
智能制造赛是中国机械工程学会主办的中国大学生机械工程创新创意大赛的一项专业赛事,每年举办一届。本科生组别中,下设四个赛项:工业网络组网与网络安全、生产系统集成与调试、数字孪生与仿真和生产系统分析与优化。
其中,生产系统分析与优化赛题是对生产过程中产生的数据进行处理与分析,通过图像识别、机器学习、人工智能算法等,实现机器视觉质量检测、设备故障预测等分析与优化。
赛题内容
2020年第三届智能制造赛本科组的生产系统分析与优化赛题,是针对流水产线上不同小车PCB板,编写相应视觉分拣程序,对test数据集进行分拣。
已知三种PCB板如下图所示,可以看到0号PCB拥有LED小灯、霍尔传感器、LED数显;1号PCB仅保留霍尔传感器;2号PCB仅保留LED数显。以此为特征,进行视觉算法的撰写。
在软件设计中,为方便用户理解,将0号PCB视为1,1号PCB视为2,2号PCB视为3。
视觉算法
算法选择
考虑到3类PCB小车视觉特征均较为明显,而给定的Train每种PCB只有40张数据集,使用神经网络的效果可能不佳。故选用了模板匹配。

模板匹配指的是通过模板图像与测试图像之间的比较,找到测试图像上与模板图像相似的部分,这是通过计算模板图像与测试图像中目标的相似度来实现的,可以快速地在测试图像中定位出预定义的目标。匹配的主要思路是使用一个目标原型,根据它创建一个模板,在测试图像中搜索与该模板图像最相似的目标,并寻找与该模板的均值或方差最接近的区域。
算法实现过程
读入Train并创建模板
使用os模块读入train文件,并划定相应区域作为模板,不同种类的小车PCB模板区域需要手动给定值进行截取。
# 保存每一张训练和测试图片的完整路径
train_0 = 'DATA\\Train\\0\\'
train_1 = 'DATA\\Train\\1\\'
train_2 = 'DATA\\Train\\2\\'
train_t = 'DATA\\Test\\'# 定义列表
filenames_0 = []
filenames_1 = []
filenames_2 = []
filenames_t = []
abs_t = []
images = []
tests = []
templates = []
j = 0
# 读入Train中0号小车并提取模板
for (dirpath_0, dirnames_0, filenames_0) in os.walk(train_0):pass
for file in filenames_0: # 每次只处理一张图片file_path = train_0 + file # 这张图片的完整路径,file_path是一个str类型的数img = cv2.imread(file_path, flags=1)img = cv2.medianBlur(img, 5)images.append(img)template = img[320:500, 150:300]# cv2.imshow('a',cut) 此处是维护设计,主要为了查看读入图片是否正确及图像处理的结果# cv2.waitKey(0)cv2.imwrite('DATA\\Template\\0\\' + str(j) + '.jpg', template)templates.append(template)j += 1
# 读入Train中1号小车并提取模板
for (dirpath_1, dirnames_1, filenames_1) in os.walk(train_1):pass
for file in filenames_1:file_path = train_1 + fileimg = cv2.imread(file_path, flags=1)img = cv2.medianBlur(img, 5)images.append(img)template = img[140:320, 150:300]cv2.imwrite('DATA\\Template\\1\\' + str(j) + '.jpg', template)templates.append(template)j += 1
# 读入Train中2号小车并提取模板
for (dirpath_2, dirnames_2, filenames_2) in os.walk(train_2):pass
for file in filenames_2:file_path = train_2 + fileimg = cv2.imread(file_path, flags=1)img = cv2.medianBlur(img, 5)images.append(img)template = img[260:510, 500:650]# cv2.imshow('a',cut)# cv2.waitKey(0)cv2.imwrite('DATA\\Template\\2\\' + str(j) + '.jpg', template)templates.append(template)j += 1
读入Test数据
继续使用os模块读入test数据。
# 读入Test数据
for (dirpath_t, dirnames_t, filenames_t) in os.walk(train_t):pass
for file in filenames_t:file_path = train_t + fileabs = os.path.abspath(file_path)abs_t.append(abs)test = cv2.imread(file_path, flags=1)test = cv2.medianBlur(test, 5)tests.append(test)
# print(len(tests)) # 此处是维护设计,以证明test库中数据均读入程序
图像预处理与视觉分拣
对于目标检测图片使用中值模糊对其进行处理,以对椒盐噪声有很好的抑制作用。主要逻辑思路为:假定类型type为0,遍历先前读入的所有模板总计120张,进行模板匹配操作,采用的匹配方式cv2.TM_SQDIFF_NORMED,其特点为匹配值越接近0,匹配程度越高。经测试,设置匹配阈值为0.08。若相匹配,则检测模板下标位,以确定PCB板种类。
global j, type, min_valtarget = cv2.imread(path, flags=1)target = cv2.medianBlur(target, 5)j = 0type = 0for j in range(120):Template = templates[j]theight, twidth = Template.shape[:2]result = cv2.matchTemplate(target, Template, cv2.TM_SQDIFF_NORMED)min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result)if min_val <= 0.08:cy2qt2(self, Template)cv2.rectangle(target, min_loc, (min_loc[0] + twidth, min_loc[1] + theight), (255, 255, 225), 2)cy2qt1(self, target)if j <= 39:type = 1breakelif j <= 79:type = 2breakelse:type = 3breakif j == 120:self.label_3.setText("未找到模板,无法匹配")type = 0
实际效果
根据工业上的需要,将分拣功能划分为指定读入和顺序读入(自动和半自动)。
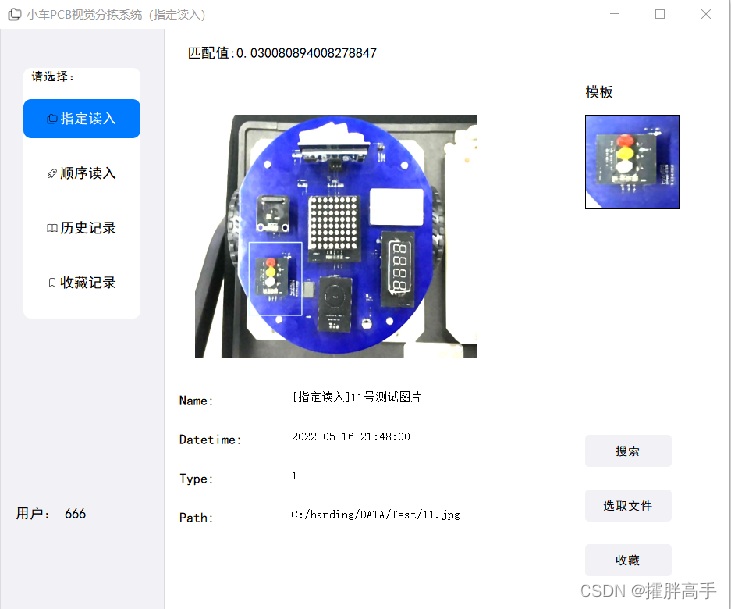
指定读入
在指定读入模式下,用户可以通过搜索,选定存储在test文件夹中的PCB板图片,也可通过选取文件,手动指定图片进行视觉分拣操作。软件后台会记录匹配值、适配模板、识别名、识别时间、识别类型及图像路径并反映至用户UI。
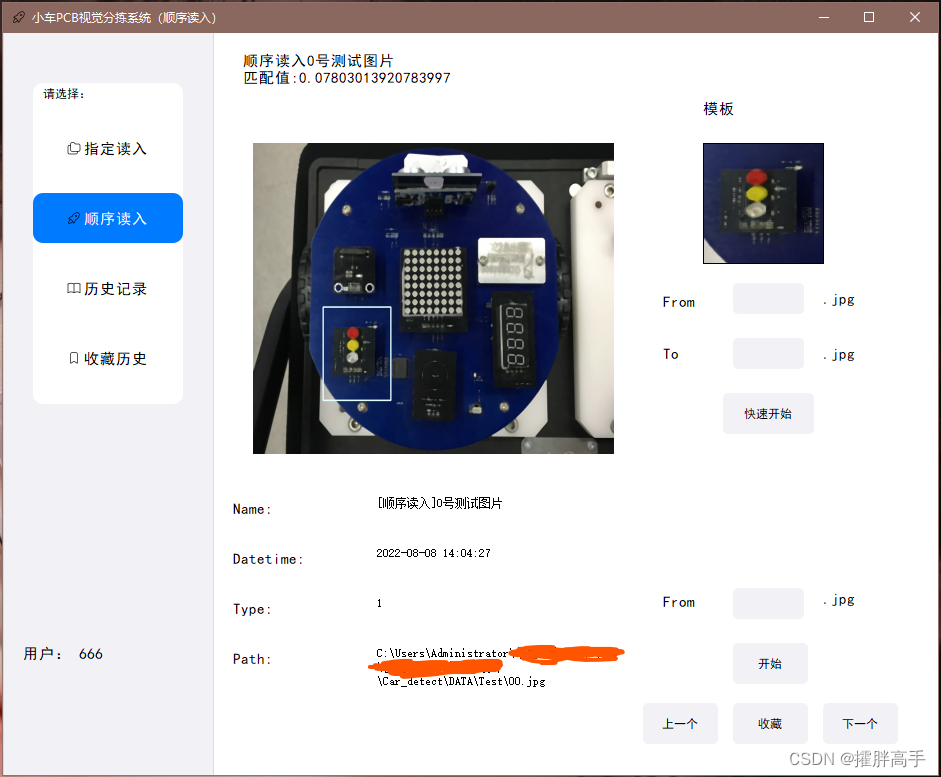
顺序读入
在顺序读入模式中,用户可以选择全自动模式,输入test中开始与终止图片号(默认全域),点选快速开始进行全自动分拣。
亦可以选择半自动模式,输入test中开始图片号(默认全域),点选开始进行半自动分拣,可以手动切换上一张、下一张,并对图片进行收藏操作。软件后台会记录匹配值、适配模板、识别名、识别时间、识别类型及图像路径并反映至用户UI。
其他
UI界面设计
使用pyqt5进行UI设计,可在pycharm中安装工具 QTdesigner进行辅助设计。
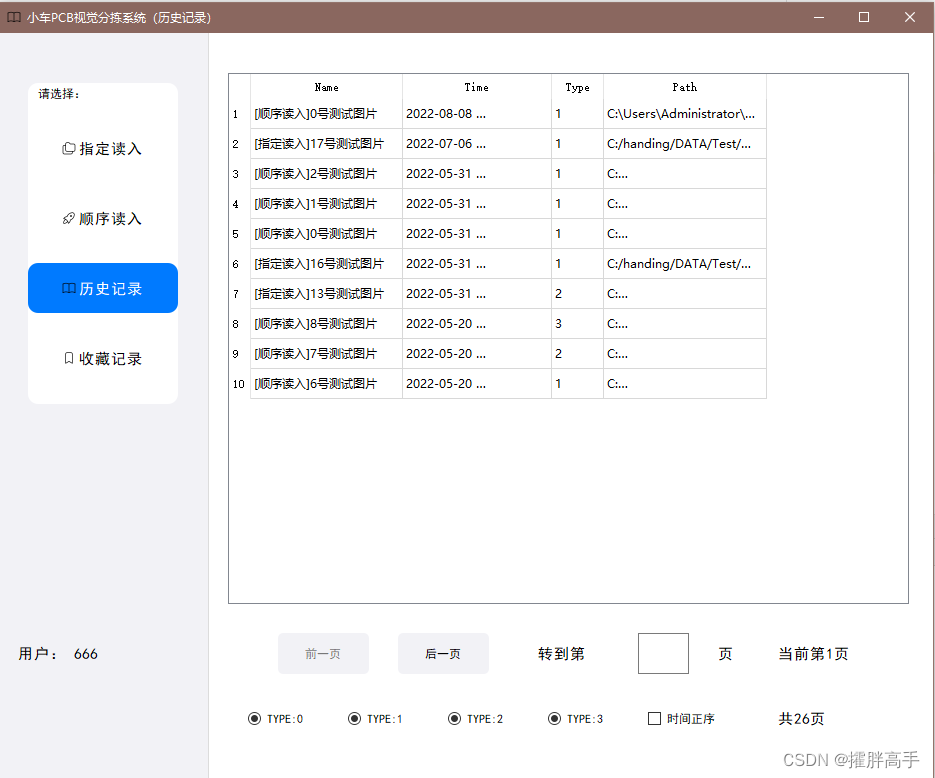
数据库
使用了sqlite数据库,创建DB文件后,在代码中对DB进行连接并修改,用以存储用户名、密码及软件识别分拣结果等内容。如图所示为软件UI中连接数据库,并查看过往识别分拣记录。
DEMO分享
资源上传了一个DEMO供大家学习交流,界面相较于完全版有简化,但保留视觉分拣的核心功能。
https://download.csdn.net/download/qq_47842513/86341714
这篇关于小车PCB板视觉分拣软件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!