本文主要是介绍ctfshow信息收集(web1-web20),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
web1
web2
web3
web4
web5
web6
web7
web9
web10
web11
web14
web15
web16
web17
web18
web19
web20
web1
根据提示的孩子开发的时候注释没有被及时删除


web2
js原因无法查看源代码
第一种方法 在url前加入 view-source: 会显示页面源代码,可以告诉浏览器直接显示网页的源代码 不受js限制
第二种方式 浏览器禁用js 浏览器中直接禁用js效果 (关闭后 要记得及时打开 js在网页中是相当重要的 会影响其他页面的显示)
可以查看源代码了
第三种方法 虽然f12无法使用
但是ctrl+shift+i 和f12有一样的效果
然后点击左上角的检查 放到 无法查看源代码这个文字的位置上
第四种方法网络的响应





web3
提示:抓个包
抓包后 获取响应包 发现http头存在flag字段


web4
提示 总有人把后台地址写入robots
robots是搜索引擎爬虫协议/机器人协议,也就是你网站和爬虫的协议。
简单的理解:robots是告诉搜索引擎,你可以爬取收录我的什么页面,你不可以爬取和收录我的那些页面。robots很好的控制网站那些页面可以被爬取,那些页面不可以被爬取。
Disallow是禁止爬取的意思。Disallow后面是不允许访问文件目录 也就证明这个目录下的文件很重要
访问flagishere.txt文件


web5
提示:phps源码泄露
phps文件就是php的源代码文件,通常用于提供给用户(访问者)直接通过Web浏览器查看php代码的内容
访问index.php就是当前页面 根据提示源码泄露也就是这个页面
访问index.phps 即可下载phps文件 从而访问获取该页面源码


web6
提示:解压源码到当前目录 。与压缩包有关
什么意思呢?
在网站的升级和维护过程中,通常需要对网站中的文件进行修改。此时就需要对网站整站或者其中某一页面进行备份。当备份文件或者修改过程中的缓存文件因为各种原因而被留在网站 web 目录下,而该目录又没有设置访问权限时,便有可能导致备份文件或者编辑器的缓存文件被下载,导致敏感信息泄露,给服务器的安全埋下隐患。该漏洞的成因主要有是管理员将备份文件放在到 web 服务器可以访问的目录下。
该漏洞往往会导致服务器整站源代码或者部分页面的源代码被下载,利用。源代码中所包含的各类敏感信息,如服务器数据库连接信息,服务器配置信息等会因此而泄露,造成巨大的损失。被泄露的源代码还可能会被用于代码审计,进一步利用而对整个系统的安全埋下隐患。常见的备份文件后缀有:.rar .zip .7z .tar.gz .bak .swp .txt首先使用dirsearch 进行目录扫描 发现当前目录下有一个/www.zip的文件 这大概率就是备份文件了
下载这个备份文件 发现有网站首页面的备份文件 并且有一个fl000g.txt提示 只是一个提示 当然打开看不到flag 使用浏览器访问fl000g.txt即可
!!为什么必须要浏览器访问才能获得敏感信息 解压缩后的文件里面没有敏感信息 那是因为 压缩包就相当于模版 里面的具体内容每个使用者会该为不同的内容



web7
提示:版本控制很重要 但不要部署到生产环境更重要
这个提示没懂 源码什么的都没有提示 直接目录扫描
扫描出了.git
访问.git
原理是什么呢(只解析原理 git的具体目前这关不需要)
Git是一个开源的分布式版本控制系统 简单的理解为Git 是一个内容寻址文件系统,也就是说Git 的核心部分是键值对数据库 当我们向 Git 仓库中插入任意类型的内容(开发者们在其中做的版本信息修改之类的操作),它会返回一个唯一的键,通过该键可以在任意时刻再次取回该内容Git是一个可以实现有效控制应用版本的系统,但是在一旦在代码发布的时候,存在不规范的操作及配置,就很可能将源代码泄露出去。那么,一旦攻击者或者黑客发现这个问题之后,就可能利用其获取网站的源码、数据库等重要资源信息,进而造成严重的危害。
正如简介所说,在配置不当的情况下,可能会将“.git”文件直接部署到线上环境,这就造成了git泄露问题。攻击者利用该漏洞下载.git文件夹中的所有内容。如果文件夹中存在敏感信息(数据库账号密码、源码等),通过白盒的审计等方式就可能直接获得控制服务器的权限和机会!
简单理解就是 git是一个键值对数据库系统 每一个键对应一个某版本源代码


web 8
提示 版本控制很重要,但不要部署到生产环境更重要
直接目录扫描进行扫
发现有一个.svn文件 访问.svn文件
原理是什么呢
SVN 是源代码管理软工具。 使用SVN管理本地代码过程中,将生成名为.svn的隐藏文件夹,包含非常重要的源码信息。 当网站管理员在发布代码时,没有使用导出功能,直接进行复制粘贴,导致出现SVN信息泄露漏洞
svn和git总结
版本控制:对软件开发过程中各种程序代码、配置文件及说明文档等文件变更的管理,是软件配置管理的核心思想之一,常见的控制版本工具:Git 、SVN、 CVS 、VSS 、TFS 等等


web9
提示 发现网页有个错别字?赶紧在生产环境vim改下,不好,死机了
看这个提示确定这是vim缓存泄露
在使用vim时会创建临时缓存文件,关闭vim时缓存文件则会被删除,当vim异常退出后,因为未处理缓存文件,导致可以通过缓存文件恢复原始文件内容
以 index.php 为例:第一次产生的交换文件名为
.index.php.swp再次意外退出后,将会产生名为
.index.php.swo的交换文件第三次产生的交换文件则为
.index.php.swn
举例 创建一个名为ss的文件 内容为qq vim时修改为qqqqq 这时异常退出
再次回到该目录查看文件后 发现了ss文件 和隐藏文件.ss.swp
查看两个文件内容 源文件是未被修改时的qq 隐藏文件是乱码
vim ss文件 提示存在交换文件
使用R就能恢复 异常退出一瞬间该文件的内容了 变成了五个q
这道题 通过目录扫描没有发现其它文件
那就是只存在当前页面index.php了 从此推出缓存文件应该为.index.php.swp
访问 该文件index.php.swp 成功下载后打开该文件即可(这里有个文件缓存文件不应该是隐藏文件.开头的嘛 为什么这里不是 有.访问还是原始页面,经过ai解释 我的理解是 各种原因导致服务器可能默认删除.开头的 不让你查看 然后作者没办法 只能放一个不是.开头的文件 充当一下,这是可能得原因之一吧)





web10
提示 cookie是一块饼干 不能存放隐私数据 由此可以得知他的cookie是存放了敏感信息
有cookie 查看一下cookie

web11
DNS解析 可能把隐私信息放在了DNS TXT记录下了 这个记录一般备注信息 可能会存在隐私信息
这道题我解析不成功估计是 群主买的域名的问题 以后再说
web12
提示 有时候网站上的公开信息 就是管理员常用密码
最下方有个电话号码
目录扫描一下 看看登录页面是哪一个 发现很多页面 学过网页的都知道 大部分都是网页必须要有的 js css images fonts 目录文件 admin和robots.txt 是重点
访问一下robots.txt 显示的也是admin 并且通过目录扫描的401状态码也能发现admin应该就是管理员登录入口
直接访问admin
得到flag
就像这种看着可能没用 但是在实战过程中有很多类似这种的漏洞 尤其是edu网站 每个院都有一个网站 管理员一般都是老师 安全意识薄弱 就会使用常用的密码 比如办公室电话





web 13
提示 技术文档里面不要出现敏感信息,部署到生产环境后及时修改默认密码
document就是技术文档
点击后发现 后台登录地址 为什么默认后台地址是your-domain并不是具体的靶场地址 因为这个技术文档包括开发的系统 都用来卖的 每个人买 每个人的域名都不一样
访问后 得到flag
注意:这道题也告诉我们 目录扫描只能扫描常见的目录名称 像这道题的目录名根本就扫描不到 除非字典足够大



web14
提示:某编辑器最新版默认配置下,如果目录不存在,则会遍历服务器根目录
提示:有时候源码里面就能不经意间泄露重要(editor)的信息,默认配置害死人
上传图片的时候,先会上传到他的文件库中,最后上传图片再去图片库中去选择(但是指定目录不存在 只能遍历服务器根目录,默认配置) 从而得到服务器所有内容 简单理解就是 不安全的编辑器 点击其中一个功能后 可以访问服务器的所有目录
通过提示访问一下
editor 这是一个编辑器 这种编辑器政府机关特别喜欢使用这种
上传图片时 他可以上传服务器内的内容 找到flag即可
访问这个路径即可
做完后看群主视频 才理解编辑器
编辑器就是内部人员使用的 举个例子如果一个政府网站的页面 上面是领导讲话的文件 下面是图片 这个图片就有可能来自编辑器的路径里面的图片 这个时候查看源码的时候 搜索editor 就发现了编辑器的具体路径 访问后就是编辑器页面
编辑器因为html5强大的原因 现在很少使用 但是也要记住 也是渗透的一个思路





web15
提醒;公开的信息比如邮箱,可能造成信息泄露,产生严重后果
有个一个邮箱
先目录扫描发现登录入口
点击忘记密码 密保是哪个城市
搜索邮箱qq号在西安
提交后重置密码
使用管理员账户密码登录即可
这道题前提 账户也必须是简单点的 比如这题是admin 如果账号难那破解就慢了






web16
提示:对于测试用的探针,使用完毕后要及时删除,可能会造成信息泄露
目录扫描没有什么可以用到的
根据提示
php探针是用来探测空间、服务器运行状况和PHP信息用的,探针可以实时查看服务器硬盘资源、内存占用、网卡流量、系统负载、服务器时间等信息 它可以通过向目标设备或网络发送特定的数据包来检测网络的延迟、丢包率、带宽等指标,并收集这些数据以便进行分析和优化
访问默认探针tz.php
点击phpinfo
得到flag



web17
提示:备份的sql文件会泄露敏感信息
直接目录扫描 发现backup.sql 这就是一个sql的备份文件
访问下载即可
这道题和.git .svn泄露差不多 不小心将重要的文件放到了网站目录下 从而导致敏感信息泄露


web18
提示 :不要着急,休息,休息一会儿,玩101分给你flag
点进去是一个游戏 正常玩肯定不行 查看页面源码 有个js的文件 看看里面的函数看看玩到100分会怎么样 给了unicode编码格式的字符串
解码一下 你赢了去110.php看一看
访问110.php 得出flag
unicode快速解码就用浏览器自带的控制台即可 把他作为一个字符串进行输出




web19
提示: 密钥不要放在前端
查看源码 js 以及注释 发现密码必须是给定的一个值才可以得到flag 这个给定的值是通过AES加密得到的 AES的密钥以及偏移量都给出了 从而求出密码原始值
第二种方法 源码中的js 是在前端中对输入的进行验证 使用抓包 在数据包中修改password的值为加密后的值也可以




web20
提示:mdb文件是早期asp+access构架的数据库文件,文件泄露相当于数据库被脱裤了
前几年比较多 数据库作为文件进行保存 大多数默认保存在db目录下
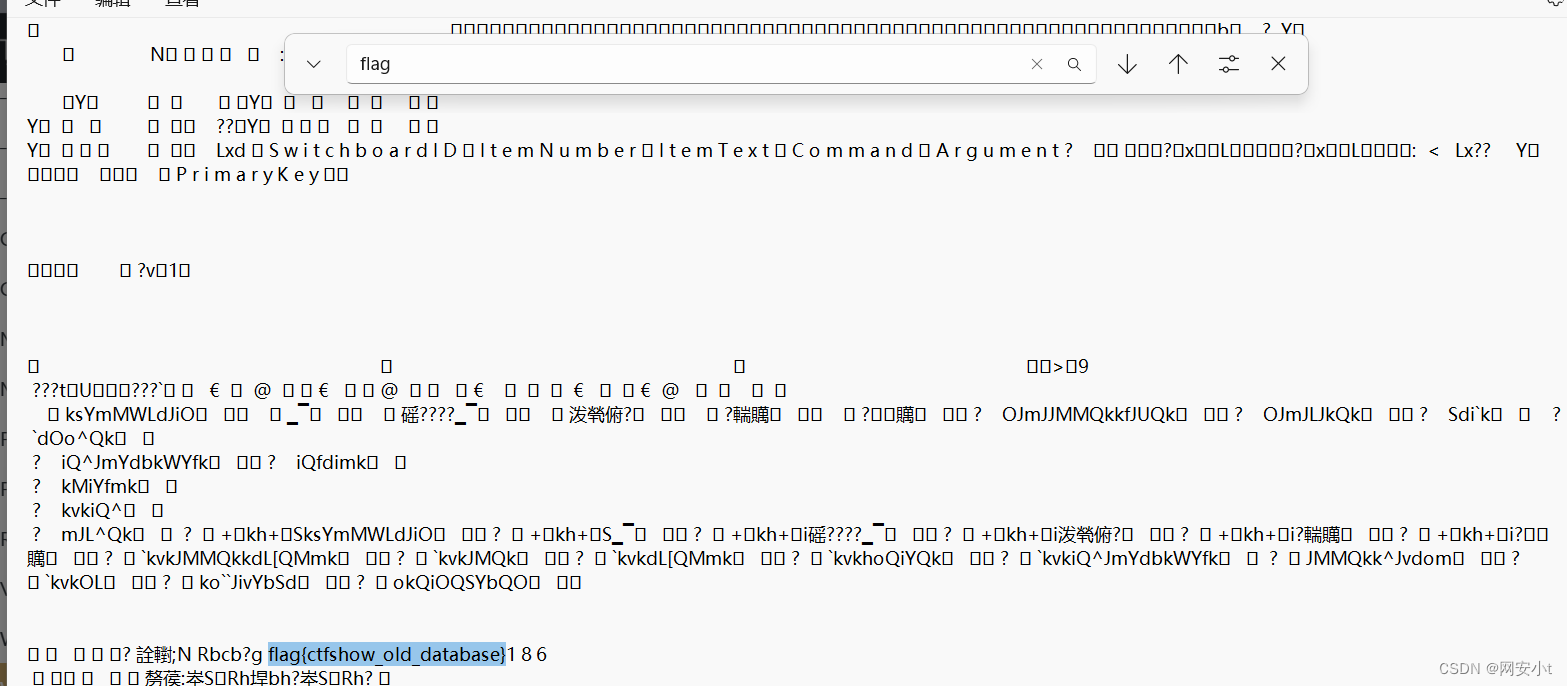
跟泄露有关 直接扫描 有个db目录下的db.mdb文件 一旦泄露 就是数据库被拖库了
访问下载后 就下载了一个 二进制的文件 这就达到了数据库拖库 直接记事本打开 搜索flag就行
这里说一句 大师傅说 以前为了防止数据库被下载 会修改数据库名前加上# 设置如果识别浏览器url如果存在#会自动舍弃#后的内容 导致无法下载 但是可以使用%23进行替换

这篇关于ctfshow信息收集(web1-web20)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






