本文主要是介绍R语言空气污染数据的地理空间可视化和分析:颗粒物2.5(PM2.5)和空气质量指数(AQI),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近我们被客户要求撰写关于空气污染数据的研究报告,包括一些图形和统计输出。
介绍
由于空气污染对公众健康的不利影响,人们一直非常关注。世界各国的环境部门都通过各种方法(例如地面观测网络)来监测和评估空气污染问题。全球的地面站及时测量了许多空气污染物,例如臭氧、一氧化碳、颗粒物。EPA(环境保护署)提供了空气污染数据,本文选择了颗粒物2.5(PM2.5)和空气质量指数(AQI)这两个关键变量,以可视化和分析空气污染的趋势和模式。PM2.5代表直径小于2.5微米的颗粒物浓度,AQI是综合考虑所有主要污染物的空气污染状况的整体指标。具体来说,此工作的数据源列出如下:
- 监测人员每天的PM 2.5浓度水平和AQI指数数据;
- 县一级的AQI年度摘要。
数据预处理
每日站点数据包含每个地面站与PM2.5相关的各种属性。有关站信息,污染物的关键变量通过以下代码从原始数据中过滤掉。重命名过滤后的数据框的列名,以方便以下分析。
#导入数据
aqi <- read_csv("aqi.csv")
daily<- read_csv("daily.csv")
names(data) <- c( "date", "pm25", "aqi", "long", "lat")统计摘要
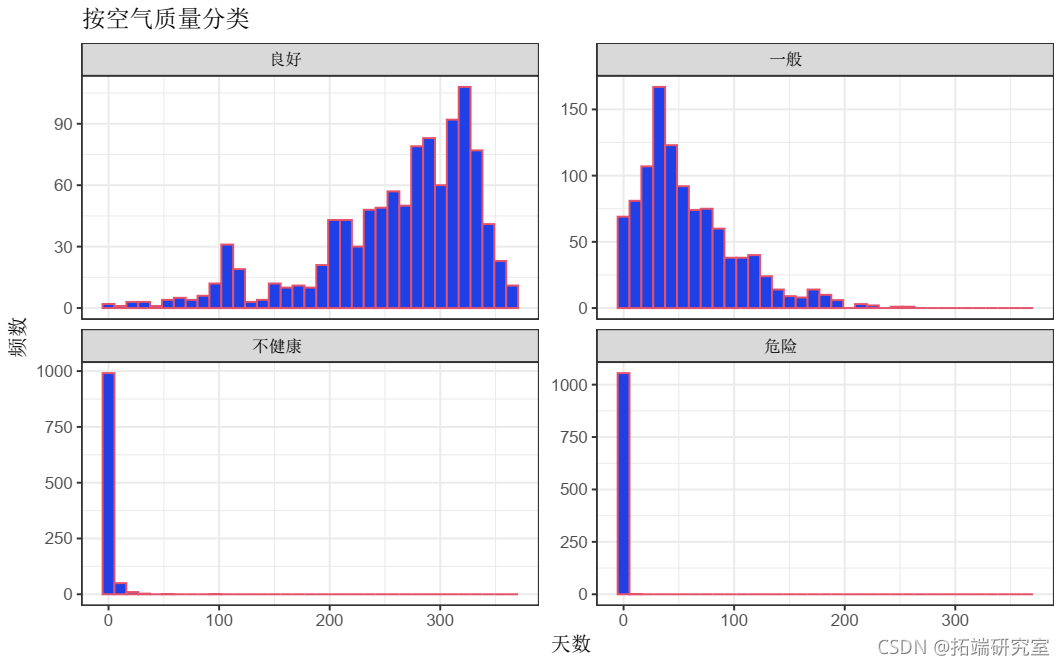
对点级PM2.5浓度和县级AQI指数的基本统计描述可以帮助更好地理解这两个变量。在这里,直方图和箱形图用于可视化PM2.5浓度和AQI的分布特征。每日AQI指数可衡量空气污染的严重程度,可用于根据AQI的值将天数分为不同的类别。就空气污染水平而言,通常可以将天气分为四类,包括良好,中度,不健康和危险。
本报告中使用的县级AQI数据包括四个类别变量,代表每个类别的天数。下面的代码直观地显示了四个类别变量的分布。根据直方图,大多数县在整年总体空气质量良好,这可以通过``良好''分布的偏斜来表示,``不健康''和``危险''的0天左右的分布间隔非常窄。此外,``良好''和``中等''的分布显示出相反的偏斜,这表明空气质量中等的日子在全年并不典型,因为``中等''的分布集中在50天以下,而``良好''的分布在250天以上。
## 县域内aqi的直方图
vi <-aqi %>% select(`好', `中等', `不健康', `危险') %>%ggplot(data = vi )
县级数据代表空气污染的平均水平。来自地面站的PM2.5和AQI的点级测量描述了空气污染的详细情况和当地情况。站级的PM2.5和AQI的分布如下所示。两种分布都显示出正偏度,AQI聚集在50附近,而PM2.5低于25。在这一年中,很少出现两个变量都具有高值的站点。
## ##AQI和PM2.5的直方图pmaqi %>%
ggplot(data) +geom_histogram(aes(x = value), bins = 35) +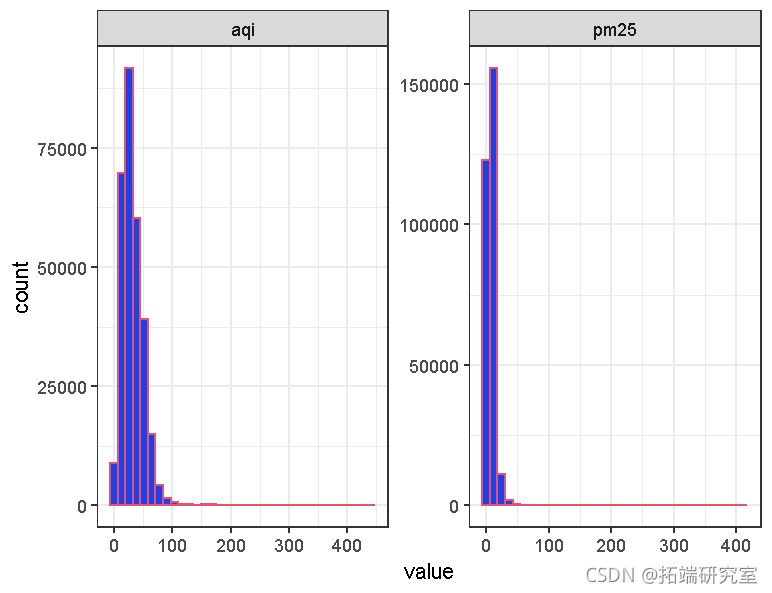
ggplot(data) +geom_boxplot(aes(x =class, y = value)) 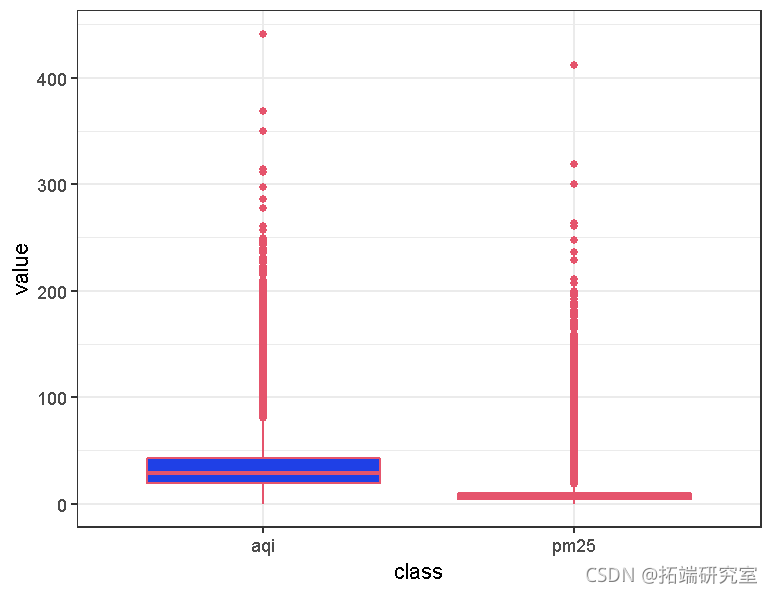
时间变化
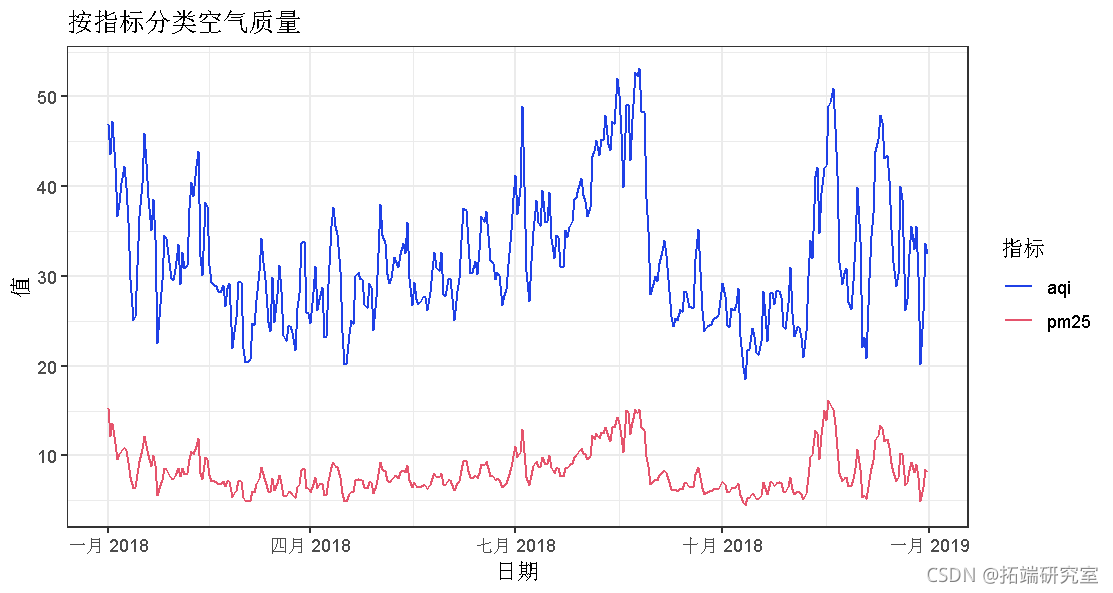
每日数据记录了2018年监测站点每天的观测时间序列,可用于探索PM2.5和AQI的趋势。首先,针对每种数据对每种状态下站点的测量值求平均。选择了七个州的时间序列以显示其一年中的变化,如下所示。从该图可以看出,南部和西部各州在年初就经历了严重的空气污染问题。趋势曲线的高峰表明,下半年的空气质量均较差。
##按州和日排列
vis <- select(state, date, pm25, aqi) %>%group_by(state, date) %>%summarise(pm25 = mean(pm25), aqi = mean(aqi)) %>%ggplot(data = vis) 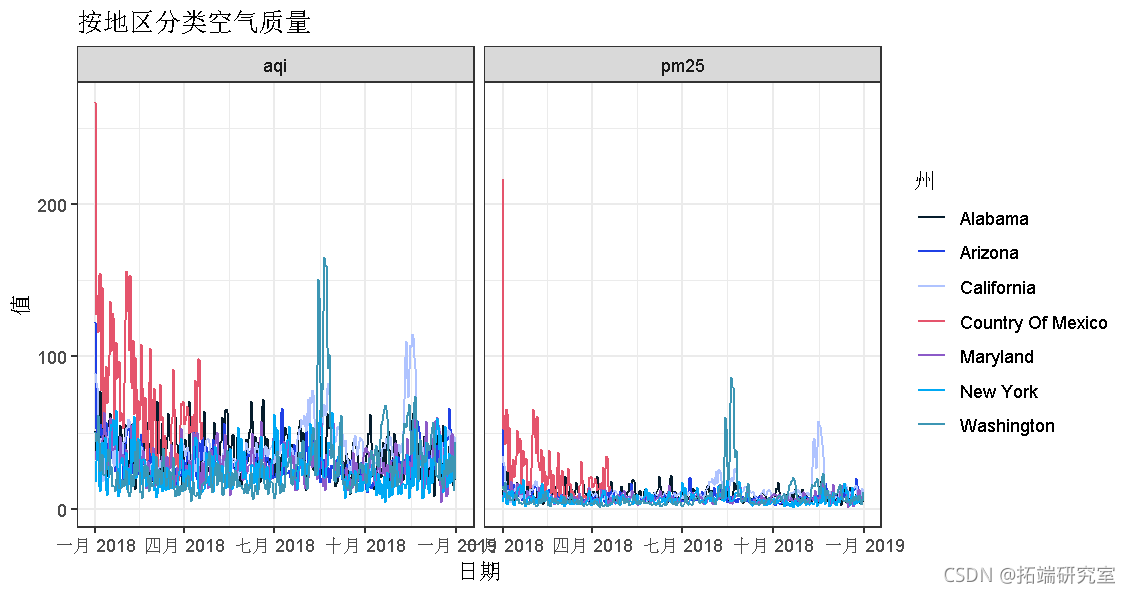
为了显示总体变化,每天汇总来自所有监视的测量值。一年中的总体变化绘制如下。我们可以看到,AQI和PM2.5的变化趋势显示出相似的模式,而夏季和冬季的空气污染更为严重。
##按天数计算select(date, pm25, aqi) %>%group_by(date) %>%summarise( mean(pm25), mean(aqi)) %>%
ggplot(data = vis) +
空间分布
汇总了针对不同州的县级AQI指数,以探索每个州的空气质量的空间变化。下图通过渐变颜色绘制了变量良好天气的不同平均值。该地图显示了各州空气质量良好的日子。从地图上可以看出,北部和东部地区的空气条件比其他州更好。
##按州汇总aqi(区域水平)。vis <- aqi %>%group_by(State) %>%ggplot() +geom_polygon(aes(x = long, y = lat, group = group, fill = good)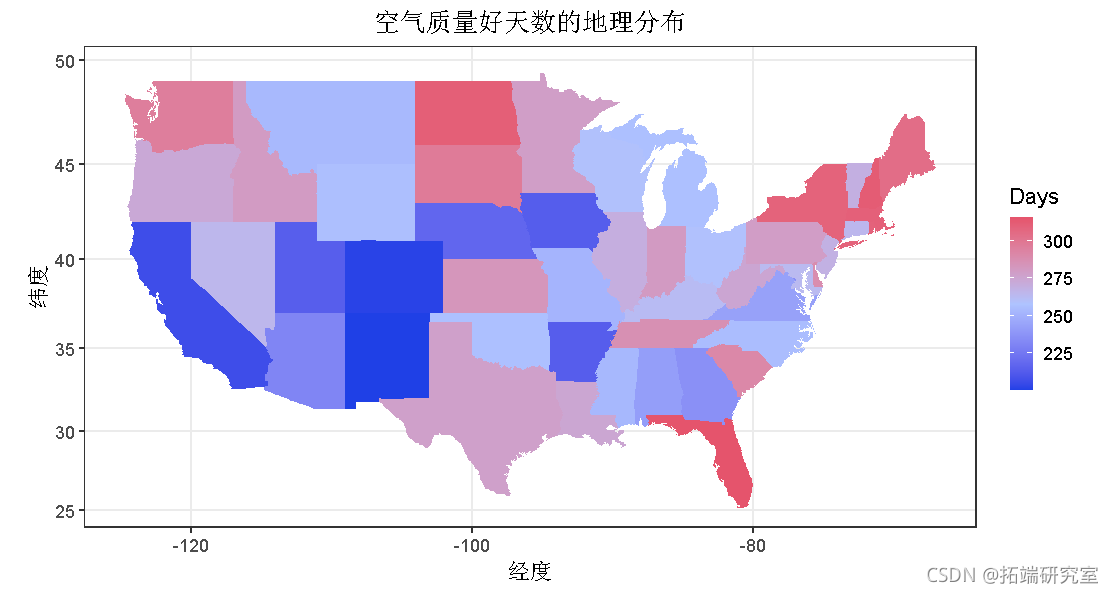
下面还绘制了不健康天数变量的平均值,这证实了以前的观察结果,即东部各州的空气条件较好。
ggplot() +geom_polygon(aes(x = long, y = lat, group , fill ), scale_fill_distiller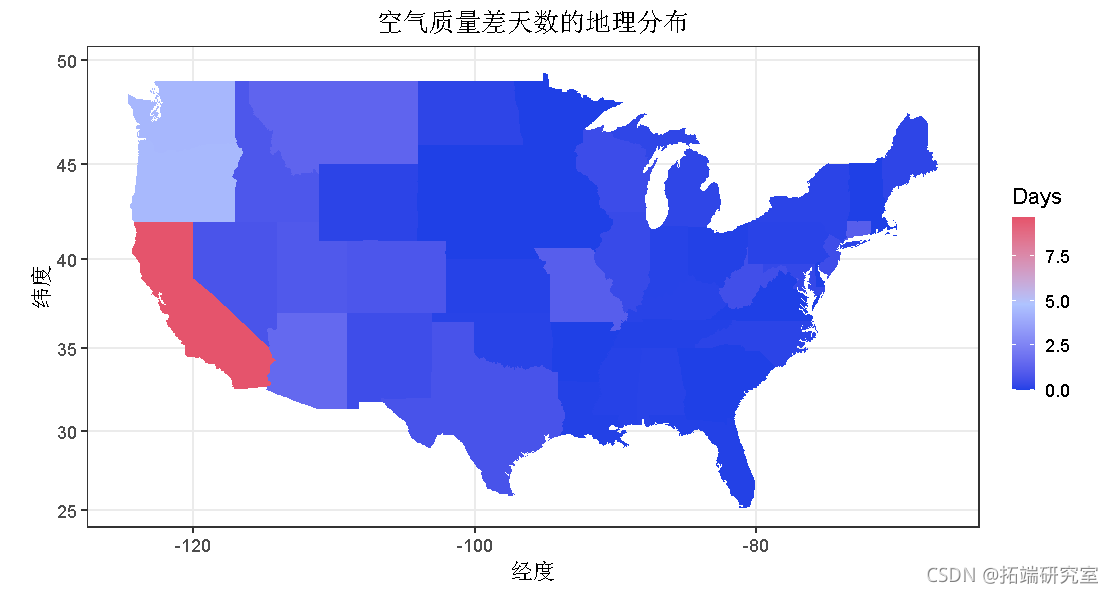
每个站点的站点级别测量值汇总为年平均值。下图显示了美国年平均PM2.5浓度的空间分布。绿色点表示较低的PM2.5浓度。西部的测站测得的PM2.5浓度较高。
## 数据的汇总
###用于pm2.5pmaqi %>%summarise(pm25 = mean(pm25), aqi = mean(aqi), long = mean(long), lat = mean(lat)) %>%
ggplot() +geom_polygon(aes(x = long, y = lat, group = group) 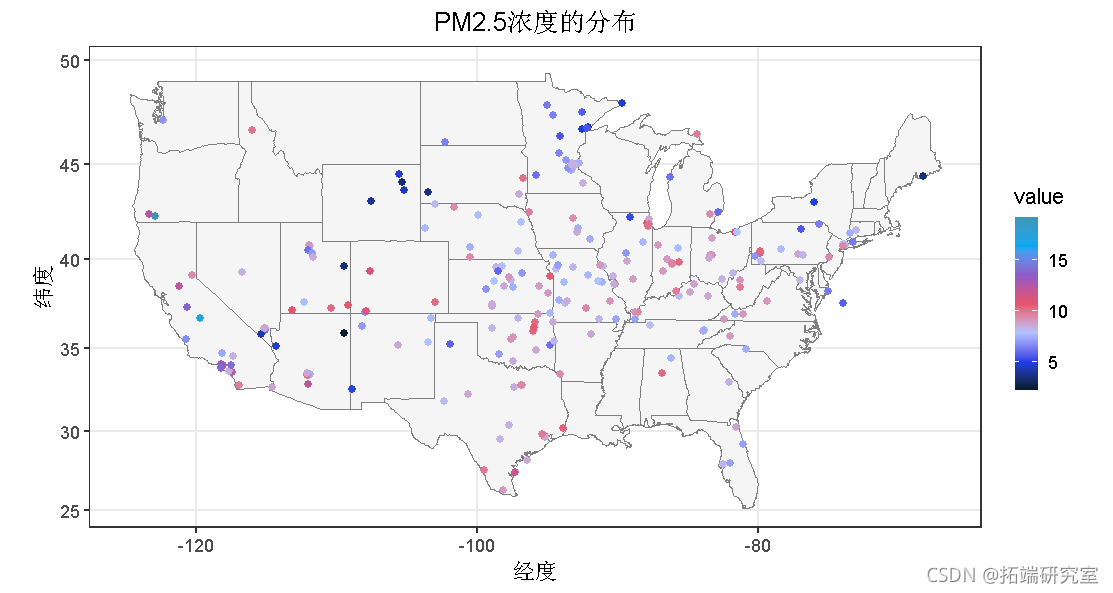
AQI可以提供更全面的空气状况度量。站点上的点级AQI映射如下。由于AQI考虑了许多典型污染物,因此与PM2.5的模式相比,AQI的分布显示出不同的模式。
###aqi指数
vi<- vi[class == "aqi", ]
ggplot(vi) +geom_polygon(aes(x = long, y = lat, group = group) 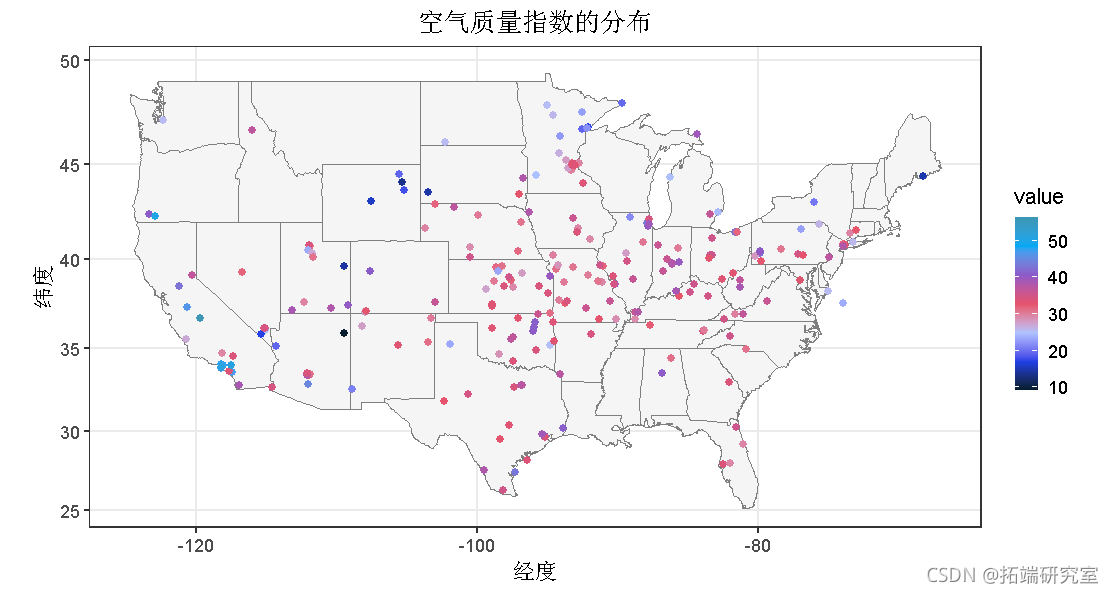
结论
本报告利用了空气污染数据和R的可视化,从时空维度探讨了空气污染的分布和格局。从数据中可以识别出PM2.5和AQI的时空变化。夏季和冬季均遇到空气污染问题。西部和南部的州比北部和东部的州更容易遭受空气污染问题。

这篇关于R语言空气污染数据的地理空间可视化和分析:颗粒物2.5(PM2.5)和空气质量指数(AQI)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






