本文主要是介绍mmdetection-虚拟环境的搭建与代码调试,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、mmdetection---虚拟环境配置
官方要求:

初始环境:
- python==3.6.8
- CUDA==9.0
- Pytorch==1.0.0
- GCC==4.8.4
- mmcv>=0.2.6
遇到的问题:
①、Segmentation fault(core dumped)-段错误
使用‘‘gdb’’追踪错误:

错误原因:gcc和系统版本太低,需要升级系统和gcc版本;
参考网址:https://github.com/open-mmlab/mmdetection/issues/24
②、Cuda版本与RTX2080有冲突:THCudaCheck FAIL:

错误原因:显卡使用RTX 2080Ti的时候,CUDA就要装10以上。还没有验证......
③、AttributeError: model 'torch.nn' has no attribute 'SyncBatchNorm';
![]()
解决方法:升级Pytorch版本至Pytorch==1.1.0。
(有关Pytorch安装较慢的问题解决,可参考:https://blog.csdn.net/songchunxiao1991/article/details/95192063)
最后,实现的实践环境:
- python==3.6.8
- CUDA==9.0+
- Pytorch==1.1.0(如果是Pytorch==1.0.0,会报错:SyncBatchNorm)
- GCC==5.4.0
- mmcv>=0.2.6
2、mmdetection---代码调试
调试的数据格式是采用VOC的格式进行的。
①、输入数据的修改:./mmdet/datasets:-voc.py(图片文件默认是*.jpg,如若不是,对应源码进行修改)
Note:CLASSES修改为:自己检测的LabelName
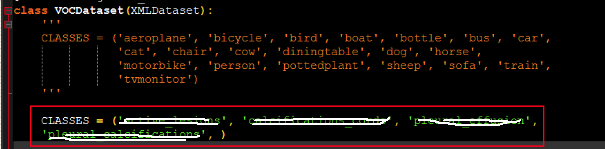
②、配置文件的修改:./configs/cascade_rcnn_r50_fpn_x1.py
Note:num_classes修改为目标检测LabelNum+1
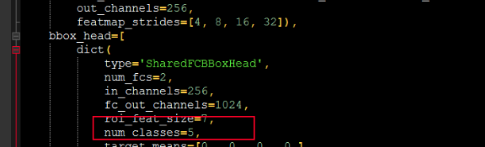
Note:batch_size/epochs/model_save/shape都在config配置文件中进行修改

Note:当gpu数量为8时,lr=0.02;当gpu数量为4时,lr=0.01;只要一个gpu,所以设置lr=0.0025

③、评估阶段的修改:./mmdet/core/evaluation/class_names.py
Note:修改cov_classes为自己的检测LabelNames(与第一步操作的LabelName一致)

3、训练与验证的代码操作
①、训练代码操作:
python tools/train.py configs/cascade_rcnn_r50_fpn_1x.pyNote:前提:训练、验证、测试数据已经提前写在模型的配置文件中(见2.2的配置文件的修改环节)
②、测试代码操作
- 首先,VOC格式数据需要先生成对应的结果*.pkl
python tools/test.py configs/cascade_rcnn_r50_fpn_1x.py work_dirs/cascade_rcnn_r50_fpn_1x/epoch_50.pth --out Result_file/Res_test.pkl- 然后,使用voc_eval.py评估指标
python tools/voc_eval.py Result_file/Res_test.pkl configs/TB_cascade_rcnn_r50_fpn_1x.py结果展示:
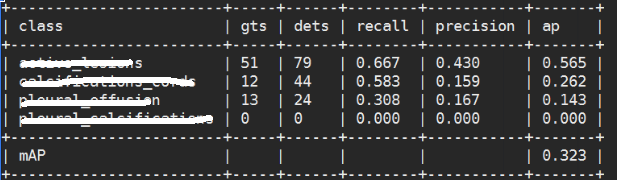
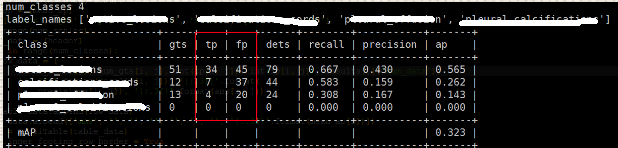
因为项目需要关注真阳和假阳的指标,因此在源码的基础上添加了tp和fp的指标:
这篇关于mmdetection-虚拟环境的搭建与代码调试的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






