本文主要是介绍虹科分享 | Redis与MySQL协同升级企业缓存,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章速览:
- MySQL为什么需要Redis Enterprise
- Redis Enterprise带来哪些优势
- Redis Enterprise与MySQL协同
传统的MySQL数据库在处理大规模应用时已经到了瓶颈,Redis Enterprise怎样助力突破这一瓶颈?Redis Enterprise与MYSQL共同用作企业级缓存或副本数据库,会产生什么样的火花?二者联合的解决方案,如何加速应用程序,提升效率,实现可拓展性?
一、MySQL为什么需要Redis Enterprise
在使用MYSQL时搭配使用Redis Enterprise,可以解决常见的应用难题。例如以下方面:
1、速度:MYSQL是基于磁盘的,在大规模应用中,它的速度会无法满足需求。
2、高速数据:高速数据要求准确实时的数值,数据要求不断更新且即时可用。MYSQL并不适用于耗费长时间的业务。
3、轻松扩展应用:大型MYSQL部署会将数据集分割到多个节点或实例(分片)。但当跨多个分片查询和访问数据时,就会失去集群所带来的性能提升。
4、快速数据搜索:MYSQL并不适合用于对海量数据进行二级索引查询,它在设计之初就未考虑这一问题。
5、分布式数据:MYSQL无法有效地分发分布统一的数据集,无法保证实时响应时间。
二、Redis Enterprise带来哪些优势
1、提供实时性能:Redis Enterprise提供亚毫秒级的实时性能。将Redis Enterprise与MYSQL一起配合使用,可以将读取或写入性能从几秒提升到个位数毫秒的水平。
2、提高数据速率:Redis Enterprise提供高效且高速的数据结构,帮助您读取数据并进行实时分析。
3、增加可扩展性:Redis Enterprise支持自动的线性扩展,优化服务器和DRAM的使用。
4、高效搜索:强大的搜索功能,让Redis Enterprise可以对海量数据集进行快速的二级索引。
5、全球部署:Redis Enterprise允许将统一的数据集分布在不同地理位置,跨地区为应用程序提供实时读写保障。
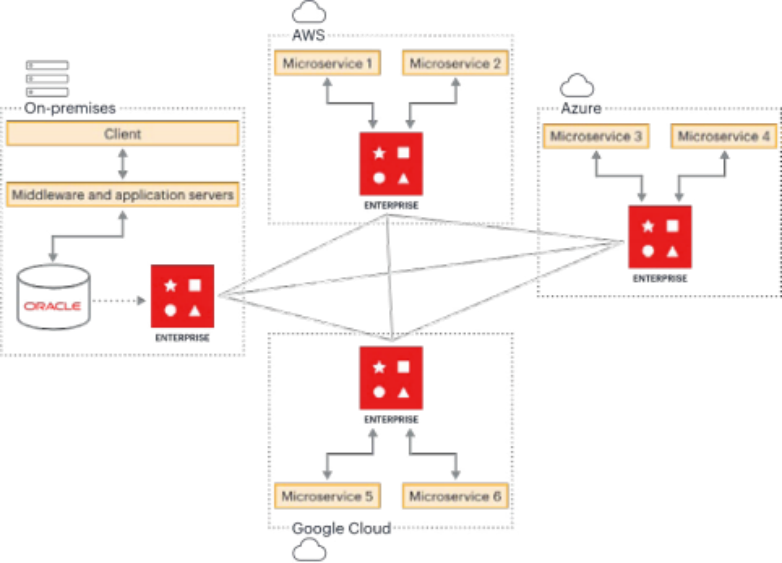
三、Redis Enterprise与MySQL协同
Redis Enterprise常常与MYSQL一同用作内存数据库或缓存,以下是一些用例:
1、二级键查询:通过使用Redis Enterprise的搜索引擎进行二级索引,支持对二级键中保存的MYSQL数据进行查询,只需要将数据从MYSQL数据库索引到Redis Enterprise即可实现。

2、针对写密集型工作负载的写入缓存:Redis Enterprise用作回写缓存,异步更新MYSQL中的关系表。

3、针对读密集型工作负载的缓存预取:使用缓存预取技术,将数据预加载到Redis Enterprise缓存中,以便应用程序在需要时能够快速访问。这样做可以提升应用程序的数据访问速度并降低成本。

4、让应用程序更现代化:弥补使用本地存储的传统应用程序与现代的云服务应用程序之间的差距。
这篇关于虹科分享 | Redis与MySQL协同升级企业缓存的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








