本文主要是介绍Swin版VMamba来了!精度再度提升,VMamba-S达成83.5%,超越Swin-S,已开源!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文首发:AIWalker
就在昨日,华科王兴刚团队公开了Mamba在ViT的入局Vim,取得了更高精度、更快速度、更低显存占用。相关信息可参考:
- 入局CV,Mamba再显神威!华科王兴刚团队首次将Mamba引入ViT,更高精度、更快速度、更低显存!
就在纳闷Swin版的VMamba啥时候出来之时,UCAS、华为以及鹏城实验室联合提出了Swin版本的VMamba,不出之外的取得了更高的精度,VMamba-S比Vim-S指标还高出3.2% ,不过这在意料之中,Swin-S也比DeiT-S高3%左右,不得不为Vim早一天公开感到庆幸,哈哈

https://arxiv.org/abs/2401.10166
https://github.com/MzeroMiko/VMamba
本文受到最近提出的状态空间模型的启发,提出了一种视觉状态空间模型(VMamba),在不牺牲全局感受野的情况下实现了线性复杂度。为了解决方向敏感的问题,我们引入了交叉扫描模块(CSM)遍历空间域和转换任何非因果的视觉图像顺序补丁序列。大量的实验结果证明,VMamba在各种视觉感知任务中表现出有前途的能力,而且随着图像分辨率的增加,表现出更明显的优势。

本文方案

上图为所提VMamba架构示意图,很明显与Swin Transformer具有相似的宏观架构,区别在于核心模块:VSS Block。很明显,VSS Block是一种大核卷积注意力模块,这里的关键就变成了如何基于SSM构建大感受野卷积注意力核了。在这里,参考S6(Selective Scan Mechanism),作者引入了2D选择性扫描机制。在S6中,矩阵$ B \in R^{B \times L \times N}, C \in R^{B \times L \times N}, \Delta in \in R^{B \times L \times D} 由输入数据 由输入数据 由输入数据x\in R^{B \times L \times N}$ 推导而来。这就意味着:S6具有输入感知的上下文信息,确保了该机制内权值的动态性。
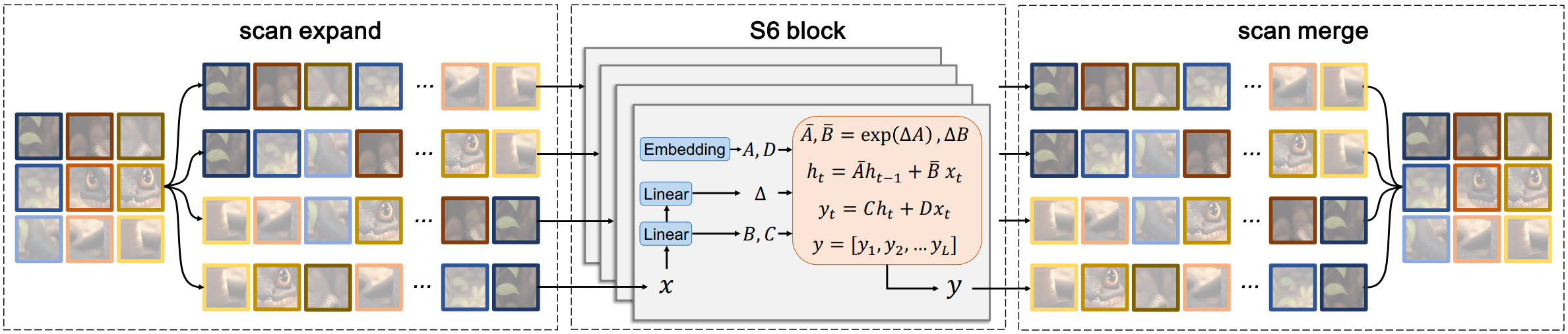
上图给出了由S6引申而来的交叉扫描模块CSM。流程上,
- 首先,将输入图像特征沿横纵坐标轴展开为序列,即图示的扫描扩展;
- 然后,沿四个方向进行扫描,即左上到右下、下右到左上、左下到右上、右上到左下。通过这种处理方式(可参考下图),任意像素都从不同方向集成了上下文信息。

- 最后,将每个序列回填至原始图像位置得到了新的图像特征。
本文实验

上表给出了三种不同大小VMamba架构参数信息,对应了Swin-T、Swin-S、Swin-B。
ImageNet分类
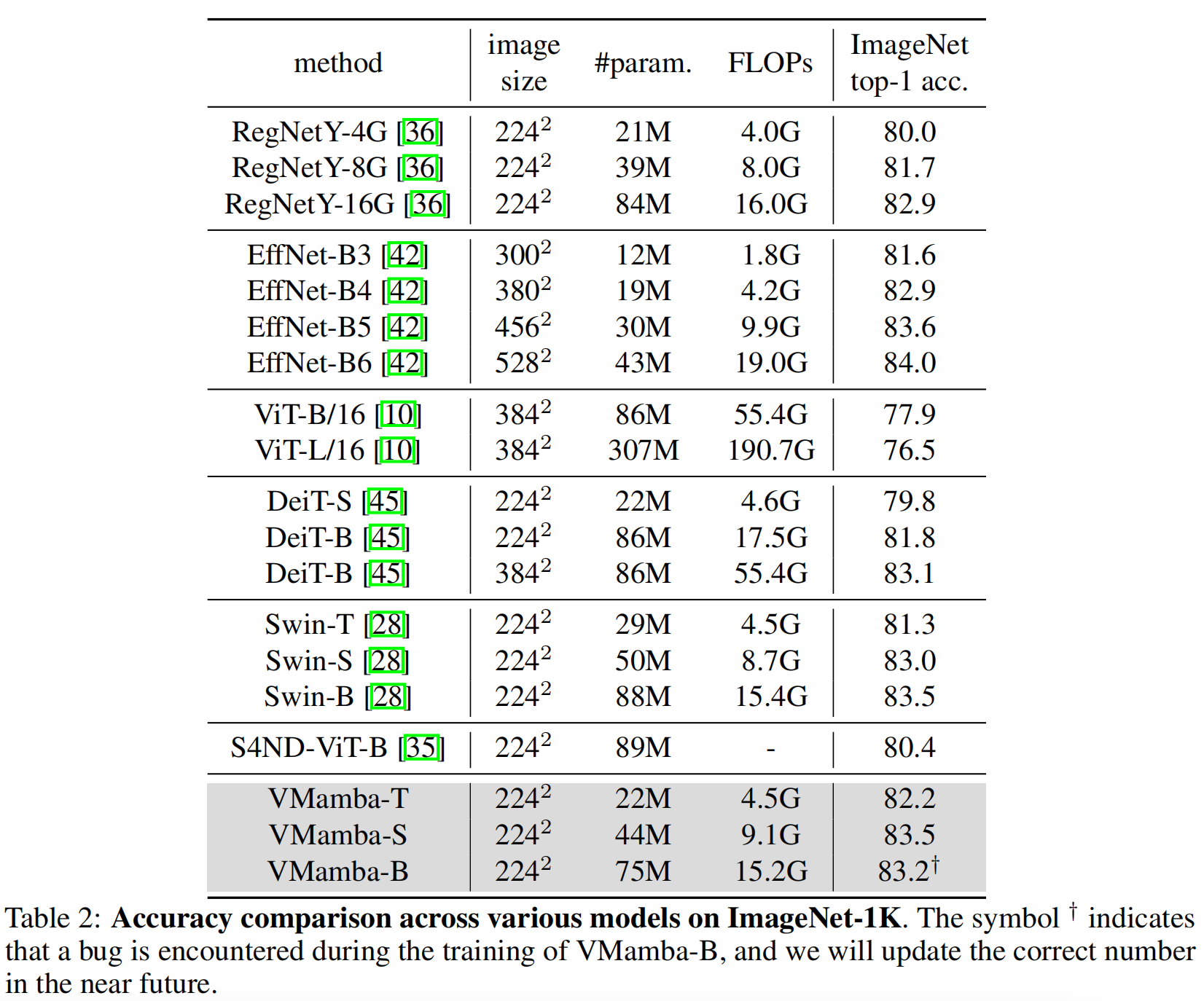
上表给出了ImageNet分类任务上的性能对比,可以看到:
- 在相似FLOPs下,VMamba-T以82.2%精度比RegNetY高出2.2%、比DeiT-S高出2.4%、比SwinT高出0.9%;
- 在Small尺度下,VMamba-S去的了83.5%,比RegNetY高出1.8%、比Swin-S高出0.5%;
- 在Base尺度下,VMamba取得了83.2%,比RegNetY高出0.3%、比DeiT-B高出0.1%。
COCO检测

ADE20K语义分割

Analysis

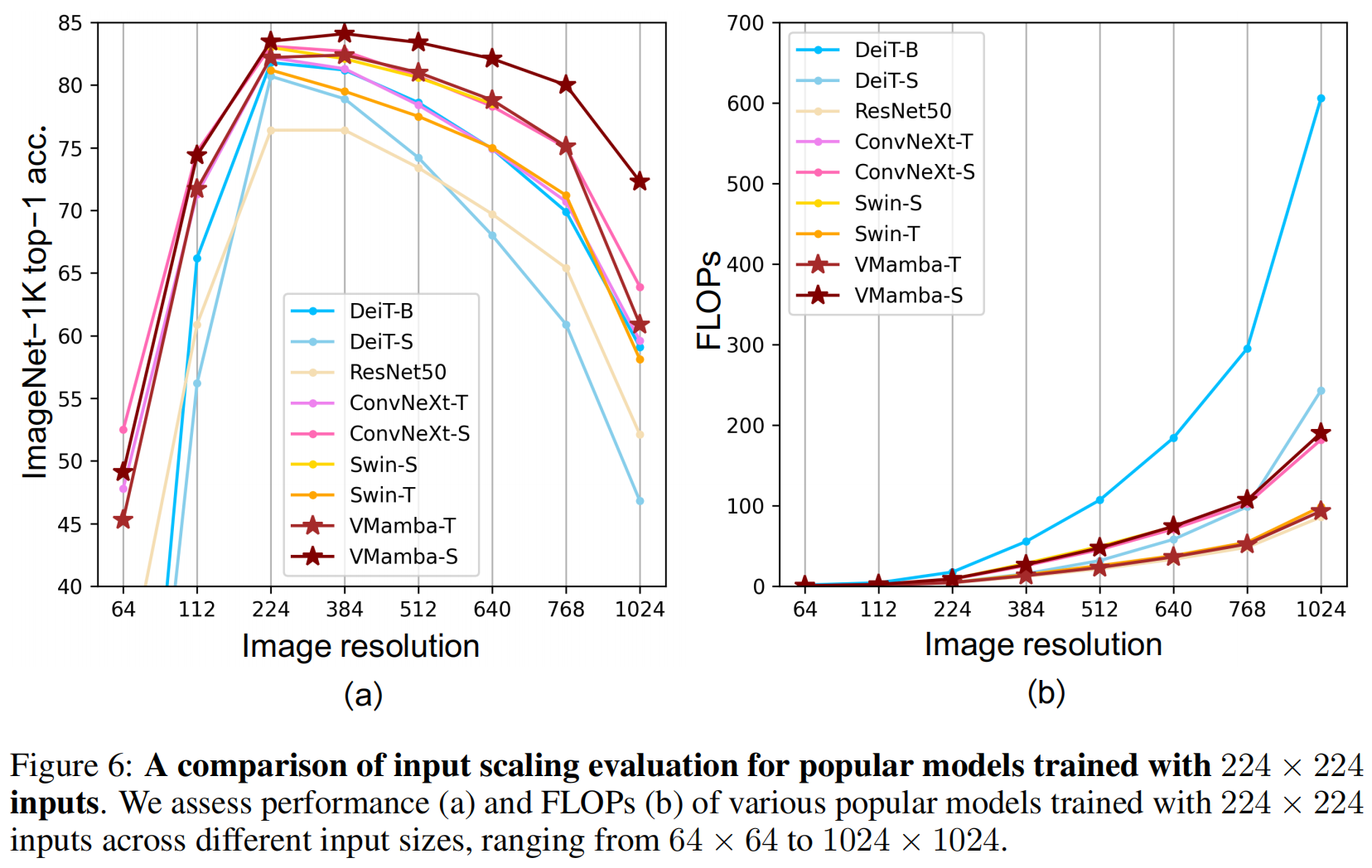
最后,作者还从感受野、输入分辨率等角度对VMamba进行了消融分析。总而言之,Mamba入局CV之路正式起航~
这篇关于Swin版VMamba来了!精度再度提升,VMamba-S达成83.5%,超越Swin-S,已开源!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






