本文主要是介绍[论文学习]Private traits and attributes are predictable from digital records of human behavior,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
cited:
Kosinski M, Stillwell D, Graepel T. Private traits and attributes are predictable from digital records of human behavior[J]. Proceedings of the National Academy of Sciences, 2013, 110(15): 5802-5805.
我们的研究显示,易于获得的数字行为记录、Facebook Likes可自动准确地预测一系列高度敏感的个人属性,包括性取向,种族,宗教和政治观点,人格特质,智力,幸福,使用上瘾物质,父母分离,年龄和性别。所提供的分析是基于58,000名志愿者提供Facebook Likes的数据,详细的人口统计资料和几项心理测验的结果。所提出的模型使用维数约减来预处理Likes数据,然后将其输入逻辑/线性回归以预测个体的心理状况。该模型判别同性和异性男性的准确率为88%,分别非裔美国人和白人美国人的准确率为95%,民主党和共和党区分准确度为85%。对于个性特质“Openness”,预测准确性接近于标准人格测试的测试精度。我们给出属性和Likes之间的关联的一些例子,并讨论在线个性化和隐私的影响。
人类活动,例如社会互动,娱乐,购物和收集信息等的比例,由数字服务和设备进行记录的比例越来越高。 这种数字媒介行为可以很容易地记录和分析,从而加剧了计算社会科学(computational social science)的出现和新的服务,如个性化搜索引擎,推荐系统和在线精准营销。 然而,广泛的个人行为记录的广泛可用性,以及对于客户和公民的更多了解的渴望,引起了与隐私和数据所有权相关的严重挑战。
我们区分实际记录的数据和可以从这些记录统计预测的信息。 人们可能会选择不透露某些关于他们的生活方式的信息,例如他们的性取向或年龄,然而这些信息可能从他们生活的其他方面的统计意义上预测出来。 例如,美国的主要零售网络使用客户购物记录来预测女性客户的怀孕情况,并他们发送定时定位的优惠。 在某些情况下,大量的产前维生素和孕妇服装的优惠券可能会受到欢迎,但也可能导致悲剧性的结果,例如,将未婚妇女怀孕透露(或不正确地)给她的家人在文化中这是不可接受的。如该示例所示,预测个人信息以改进产品,服务和定位也可能导致危险的隐私入侵。
基于各种线索预测个体特征和属性,例如书面文字样本、心理测验的答案或人们居住的空间的出现,已经具有悠久的历史。人类对数字环境的迁移使得基于人类行为的数字记录做预测变得有可能。已经有研究表明,网站浏览日志可以预测人们的年龄,性别,职业,教育水平甚至个性。类似地,可以基于个人网站,音乐收藏,Facebook或Twitter简档的属性(诸如朋友的数量或友谊网络的密度或使用的语言)来预测个性。 此外,Facebook的关系网络中的位置证明可以对性取向进行预测。
我们的研究表明,基于基本的人类数字行为记录可以用来自动准确地估计通常认为是私人的个人特征的程度。这项研究是基于Facebook Likes,Facebook的用户用来表达他们与在线内容的积极关联(或“喜欢”)的机制,如照片,朋友的状态更新,产品的Facebook页面,体育,音乐家,书籍,餐馆,或流行的网站。Likes表示非常通用的数字记录的一个类别,类似于Web搜索查询,Web浏览历史记录和信用卡购买。例如,用户对音乐的Likes类似于使用在线听音乐和搜索歌曲和艺术家,或订阅相关的Twitter频道。与其他信息来源相反,Facebook Likes默认是公开的。然而,这些其他数字记录仍然可用于许多方面(例如,政府,Web浏览器,搜索引擎或Facebook应用程序的开发人员),因此类似的预测不太可能限于Facebook环境。
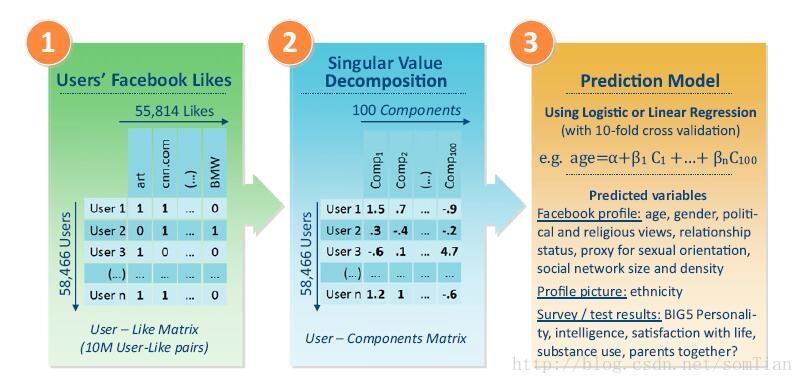
图1:该研究基于美国58,466名志愿者的样本,通过myPeopleality Facebook应用程序(www.mypersonality.org/wiki)获得,其中包括他们的Facebook个人资料信息,他们的Likes列表(没人平均值n = 170),心理测验分数和调查信息。用户和他们的Likes被表示为稀疏的User-Like矩阵,如果存在用户和Like之间的关联,则将其设置为1,否则为0。使用奇异值分解(SVD)减少了User-Like矩阵的维数。使用线性回归模型预测数字变量,如年龄或智力,而使用逻辑回归预测二分法变量,如性别或性取向。在这两种情况下,使用10-fold cross-validation,并使用k =100 top SVDcomponents。对于性取向,父母的关系状态和药物消耗仅使用k = 30 top SVD components,因为该信息可用的用户数量较少。
研究的设计如图1所示。我们选择了特征和属性揭示预测分析的准确性和可能性,包括“性取向”,“种族起源”,“政治观点”,“宗教”,“个性”,“智力” “生活满意度”(SWL),物质使用(“酒精”,“药物”,“香烟”),“21岁前个人和父母是否一直在一起”,以及基本的人口统计特征,如“年龄” “性别”,“关系状况”,“关系网络的规模和密度”。使用国际人格试题库(IPIP)调查问卷的20项设立了五因素模型人格分数(n = 54,373)。使用Raven’s标准推理测验(SPM)测量智力(n = 1,350),使用SWL量表测量SWL(n = 2,340)。年龄(n = 52,700;平均值u= 25.6; SD = 10),性别(n = 57,505; 62%女性),关系状态(“单”/“关系”; n = 46,027;单身49%意见(“自由主义”/“保守党”; n = 9,752; 65%自由党),宗教(“穆斯林”/“基督教”; n = 18,833; 90%基督教徒)和Facebook社交网络信息[n = 17,601;中值大小,X = 204;四分位数范围(IQR)206;中值密度,X = 0.03; IQR,0.03]是从用户的Facebook个人资料中获得的。用户饮用酒精(n = 1,196; 50%饮酒),药物(n = 856; 21%服用药物)和香烟(n = 1211; 30%抽烟)以及21岁前用户是否与父母一直呆在一起(n = 766; 56%保持在一起)。使用轮廓图片进行视觉检查,将种族来源分配给随机选择的用户子样本(n = 7,000; 73%的白种人,14%的非裔美国人,13%的其他人)。性取向使用Facebook个人资料“Interested in””领域分配;只对同性别其他人感兴趣的用户被标为同性恋者(4.3%男性,2.4%女性),而对异性用户感兴趣的用户则被标记为异性恋者。
Results
二分变量预测: 图2示出了以受试者工作特征曲线 receiver-operating characteristic curve(AUC)下的面积表示的二分变量的预测精度,其等同于从每个类(例如,男性和女性)中正确分类两个随机选择的用户的概率。 种族和性别的准确性最高。 非裔美国人和白种人美国人被分类准确率为95%,性别分类准确率为93%,表明Likes表现的在线行为模式在允许几乎完美分类的组之间显着不同。
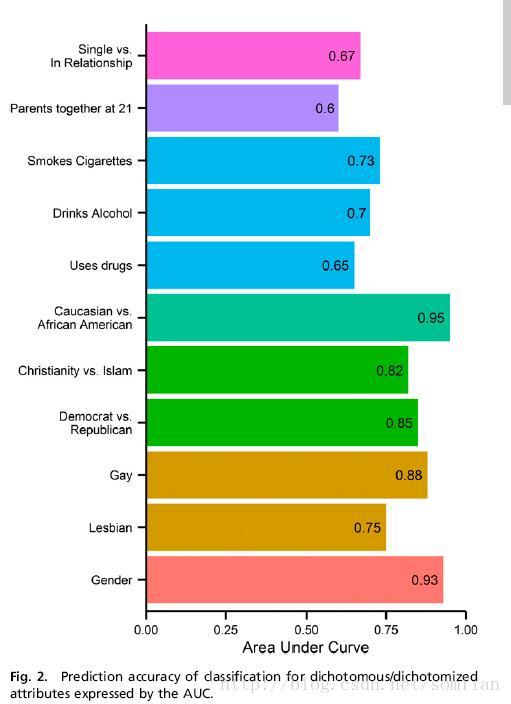
基督教徒和穆斯林分类准确度为82%,民主党和共和党人(85%)也取得了类似的成果。 男性性取向(88%)比女性更容易区分(75%),这可能表明从在线行为观察到异性和同性恋男性之间的行为差距更大。
关系状态和上瘾物质使用(65%至73%)之间的预测精度良好。 与其他二分变量(例如,性别或性取向)相比,关系状态的相对较低的准确性可以由其时间变异性来解释。
当预测用户21岁之前和父母在一起或分开时,模型的准确性最低(60%)。。 虽然众所周知,父母离婚确实对年轻人的幸福有长期的长期影响,但令人惊奇的是,这可以通过他们的Facebook Likes来检测。 与父母分离的个人有较高的恋情关注概率,例如“如果我跟你在一起,那么我跟你在一起,我不想别的人”(表S1)。
数值变量预测: 图3给出了实际值和预测值之间的皮尔森相关系数所表示的数值变量的准确性。 年龄(r = 0.75),Facebook 关系网络密度(r = 0.52)和大小(r = 0.47)得到最高的相关性。 “开放”(r = 0.43),“外向”(r = 0.40)和“智力”(r = 0.39)的个性特征密切相关。 剩余的人格特质和SWL预测精度略低,(r = 0.17〜0.30)。
心理特征是潜在性状(即不能直接测量的性状)。 因此,他们的价值观只能通过对调查问卷的回答来大致评估。 图3中显示的透明条表示使用的问卷的准确性由其重新测试可靠性表示(同一受访者在两个时间点获得的问卷分数之间的Pearson相关系数)。“开放“度的预测和实际得分(r = 0.43)之间的相关性与重测信度(r = 0.50)非常接近。 这表明,对于“开放”特征,观察用户的喜好与使用他们的个性测试成绩本身大致相同。 对于剩余的特征,预测精度对应于大约一半的问卷的测试重新测试可靠性。
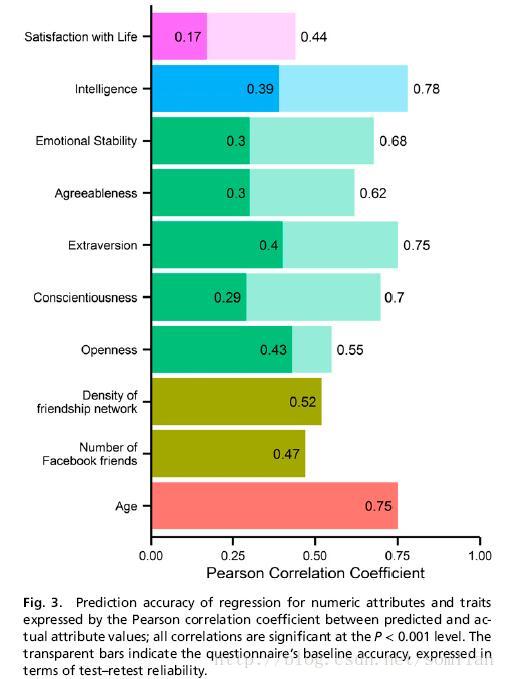
SWL的相对较低的预测精度(r = 0.17)可能归因于随着时间的推移不同,长期幸福与情绪波动分离, 因此,虽然SWL分数包含归因于情绪的变异性,但用户的喜好在较长时间内累积,因此可能仅适用于预测长期幸福感。
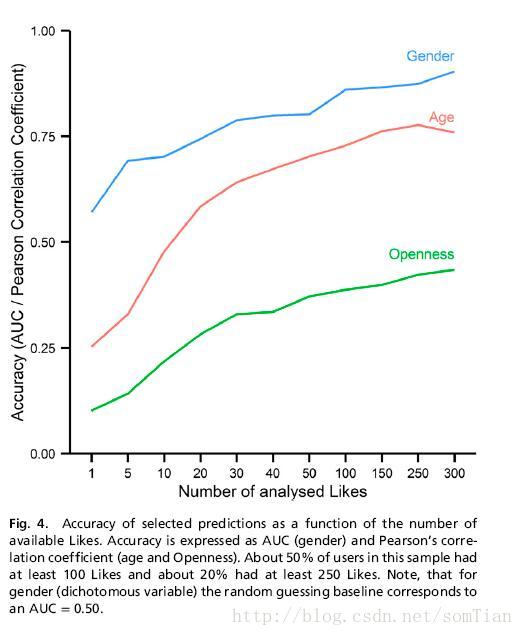
数据量和预测精度:迄今为止所呈现的结果依赖于拥有1-700 Likes之间的个人。 个人Likes的中位数为68(IQR(四分位距),152)。 因此,当给定随机个体时,预期准确度是多少,预测准确度如何随着观察到的Likes数量而变化? 使用至少有300个Likes的用户的子样本(n = 500),我们运行基于随机选择的Likes 数量n = 1,2…300的子集的预测模型。 结果如图4所示:即知道给定的用户的单个随机Like,可能会导致不可忽视的预测精度。 更多Likes会增加准确度,但每增加一条信息的收益递减。
Likes的预测力量:可以基于用户的Likes,高精度地预测个人特征和属性。 表S1显示了与每个属性相关的高度预测性的Likes的示例。 例如,高智商的最佳预测因素包括“Thunderstorms”,“The Colbert Report”,“Science”和““Curly Fries”,而低智商可以通过“Sephora”,“I Love Being A Mom”,“Harley Davidson“,”Lady Antebellum“等来揭示。男性同性恋的良好预测指标包括”No H8 Campaign“,”“Mac Cosmetics“,”Wicked The Musical“,男性异性恋的强烈预测指标包括”Wu-Tang Clan“,”Shaq “和”Being
Confused After Waking Up From Naps“。虽然一些Likes与他们预测的属性有明显的关联,比如”无H8运动“和同性恋情况一样,但其他的对也更为难以捉摸;,比如Curly Fries和高智商之间没有明显的联系。
此外,请注意,很少有Likes的用户会明确地显示其属性。 例如,不到5%的被标记为同性恋的用户与明确的同志团体相关联,例如No H8 Campaign,“Being Gay”,“Gay Marriage”,“I love Being Gay”,“We Didn’t Choose To Be Gay We Were Chosen“。因此,预测依赖于较少的信息,但更依赖于Likes,如”Britney Spears“或”Desperate Housewives“(均适合表示为同性恋者)。
补充材料和图表会有进一步的阐述,有几个流行的Likes的人格特质和年龄处于平均水平。 每个Like 吸引具有不同平均个性和人口特征的用户,因此可以用于预测这些属性。 例如,喜欢“Hello Kitty”品牌的用户在Openness上往往很高,在“Conscientiousness”,“agreeable”和“Emotional Stability”则较低,他们更有可能拥护民主党的政治观点,并可能是非裔美国人,主要是基督徒,略低于平均年龄。 使用相同的Likes创建图 S2,他们相对流行的四个组别:民主人士,基督教徒,同性恋者和非洲裔美国人。 例如,虽然喜欢“奥巴马”与民主党有明显的关系,但在基督徒,非裔美国人和同性恋个人中也是相当受欢迎的。
Conclusions
我们的研究表明,各种各样的人的个人属性,从性取向到智力,可以使用他们的Facebook Likes自动准确地推断。 Facebook Likes和其他广泛类型的数字记录(例如浏览历史,搜索查询或购买历史记录)之间的相似性表明,揭示用户属性的潜力不大可能仅限于Likes。 此外,本研究中预测的各种属性表明,给定适当的训练数据,也可能揭示其他属性。
预测用户的个人属性和偏好可用于改进众多产品和服务。例如,可以设计数字系统和设备(例如在线商店或汽车)来调整其行为以最适合每个用户。此外,通过为当前用户模型添加心理维度,可以提高营销和产品建议的相关性。例如,在面对情绪不稳定(神经质)用户时,网络保险广告可能会强调安全性,但在处理情绪稳定的用户时会强调潜在的威胁。此外,数字行为记录可以提供一种方便可靠的心理特征测量方法。基于大量行为的自动评估不仅更准确,更不容易作弊和虚假陈述,而且还可能允许随时间的评估来检测趋势。此外,基于数字记录行为观察的推论可能为人类心理学研究开辟新的大门。
另一方面,从数字行为记录预测个人属性可能具有相当大的负面影响,因为它在没有得到用户的个人同意和注意到情况下可以很容易地应用于大量的人。 商业公司,政府机构甚至Facebook的Facebook朋友都可以使用软件来推断个人可能没有打算分享的智力,性取向或政治观点等属性信息。人们可以想象,即使不正确的这样的预测可能会对个人的福祉,自由甚至生活构成威胁。 重要的是,考虑到人们留下的数字痕迹不断增加,个人很难控制哪些属性被揭示。 例如,只是避免明确同性恋内容可能不足以阻止他人发现自己的性取向。
数字曝光担忧的提升有可能对人们的数字技术经验产生不利影响,减少对在线服务的信任,甚至完全阻止数字技术的使用。 然而,我们希望通过为用户提供信息透明度和控制权,可以保持在数字环境中互动的各方之间的信任和诚意,从而在数字时代的承诺和危险之间实现个人控制的平衡。
这篇关于[论文学习]Private traits and attributes are predictable from digital records of human behavior的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






