本文主要是介绍Mybatis集成MySQL使用游标查询处理大批量数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
基于数据的时间范围查询,给符合条件的用户推送积分即将到期的提醒。
初期用户量小使用最普通简单的分页查询扫描数据处理数据没问题。随着用户量的上升表数据已经上千万,每天扫描处理的数量也超百万,limit分页出现了慢sql,任务执行时间也达不到预期了。
上述方案出现瓶颈后考虑放弃limit方案,使用游标的方式进行全量数据的获取,这样一来SQL执行快任务执行也快。
MySQL游标查询
useCursorFetch
使用游标查询时,,必须在jdbc url上设置连接属性参数useCursorFetch=true

FetchSize
在设置了useCursorFetch=true后,需要在SQL中指定fetchSize,即一次获取的数据量。
如果不设置fetchSize参数,则执行时仍然是全量返回,可能会出现OOM。
Mybatis集成Cursor查询
mapper接口方法返回值声明为Cursor类型,下面是SQL和Mapper的示例。
Cursor<Long> selectExpireCouponMember(@Param("endTime") String endTime);<select id="selectExpireCouponMember" resultType="java.lang.Long" fetchSize="5000">selectdistinct member_idfrom t_dj_couponwhereend_time > end_time < #{endStartTime} and end_time < #{endTime}
</select>下面是基于上面的SQL做大量数据查询后写入文件的代码示例。
String fileName = DateFormatUtils.format(System.currentTimeMillis(), DateUtils.PATTERN_YYYY_MM_DD) + "_status_push_member.txt";
File file = new File(fileName);
file.createNewFile();fileWriter = new FileWriter(file);
bufferedWriter = new BufferedWriter(fileWriter);
try (SqlSession sqlSession = sqlSessionFactory.openSession()) {DjCouponMapper mapper = sqlSession.getMapper(DjCouponMapper.class);try (Cursor<Long> cursor = mapper.selectStartCouponMember(startDate, startDateEnd, BrandContextHolder.getBrandMdCode())) {Iterator<Long> iterator = cursor.iterator();Set<Long> couponMemberSet = new HashSet<>(pageSize.intValue());while (iterator.hasNext()) {couponMemberSet.add(iterator.next());writeNum++;if (couponMemberSet.size() >= pageSize) {bufferedWriter.write(couponMemberSet.toString());bufferedWriter.newLine();bufferedWriter.flush();writeLine++;couponMemberSet.clear();}}if (CollectionUtils.isNotEmpty(couponMemberSet)) {bufferedWriter.write(couponMemberSet.toString());bufferedWriter.newLine();bufferedWriter.flush();writeLine++;}}
}Mybatis是如何实现基于Cursor查询的
com.mysql.cj.jdbc.result.ResultSetImpl实现类
ResultSetImpl 是mybatis中实现游标查询结果解析的类。这个实现类的next方法中调用了ResultsetRows接口的next方法。
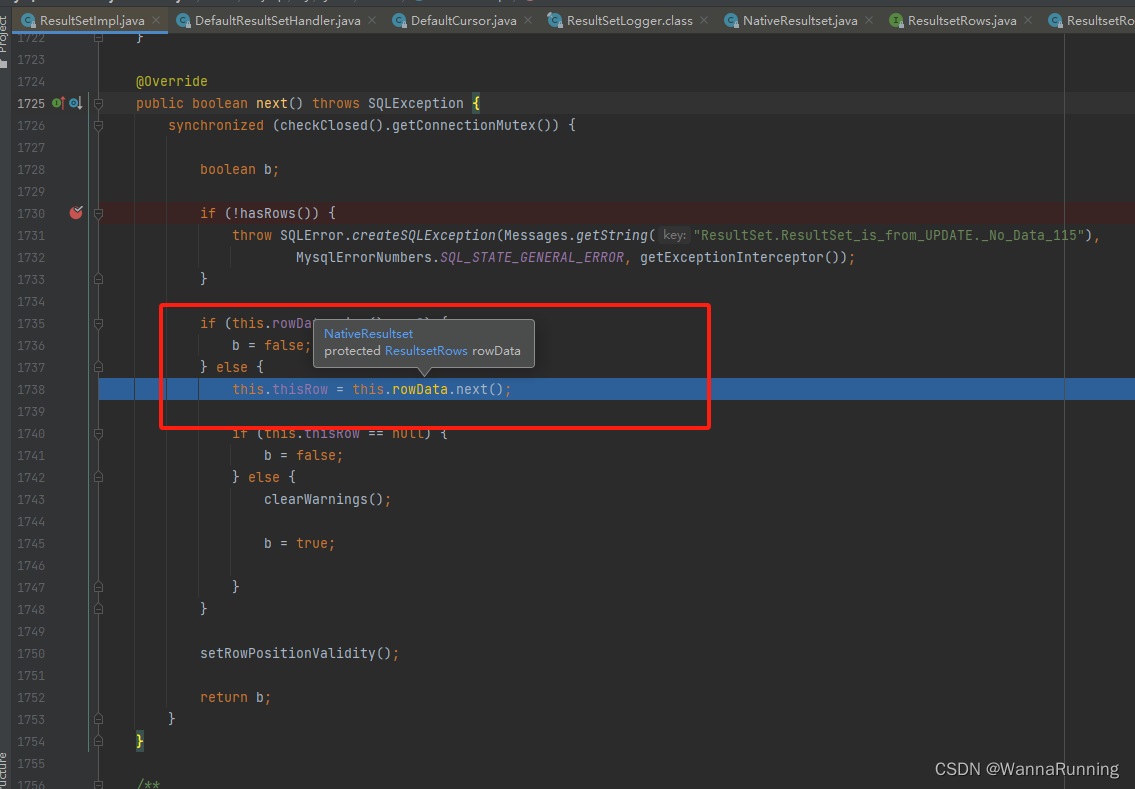
ResultsetRows接口
ResultsetRows接口有ResultsetRowsCursor,ResultsetRowsStatic,ResultsetRowsStreaming三个实现类。
本文写的游标查询的场景,使用的是ResultsetRowsCursor这个实现类。
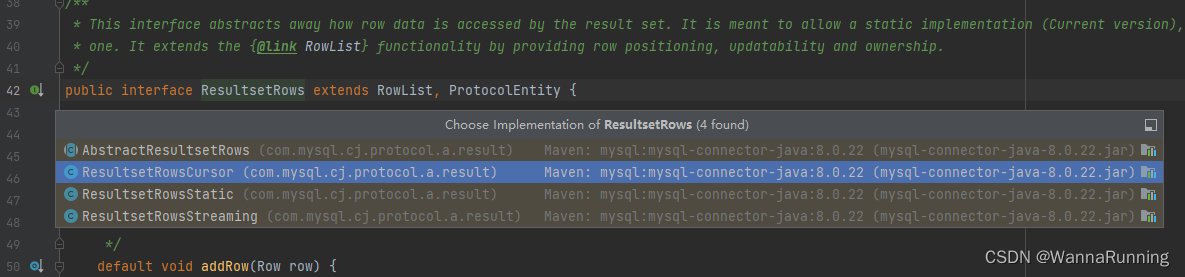
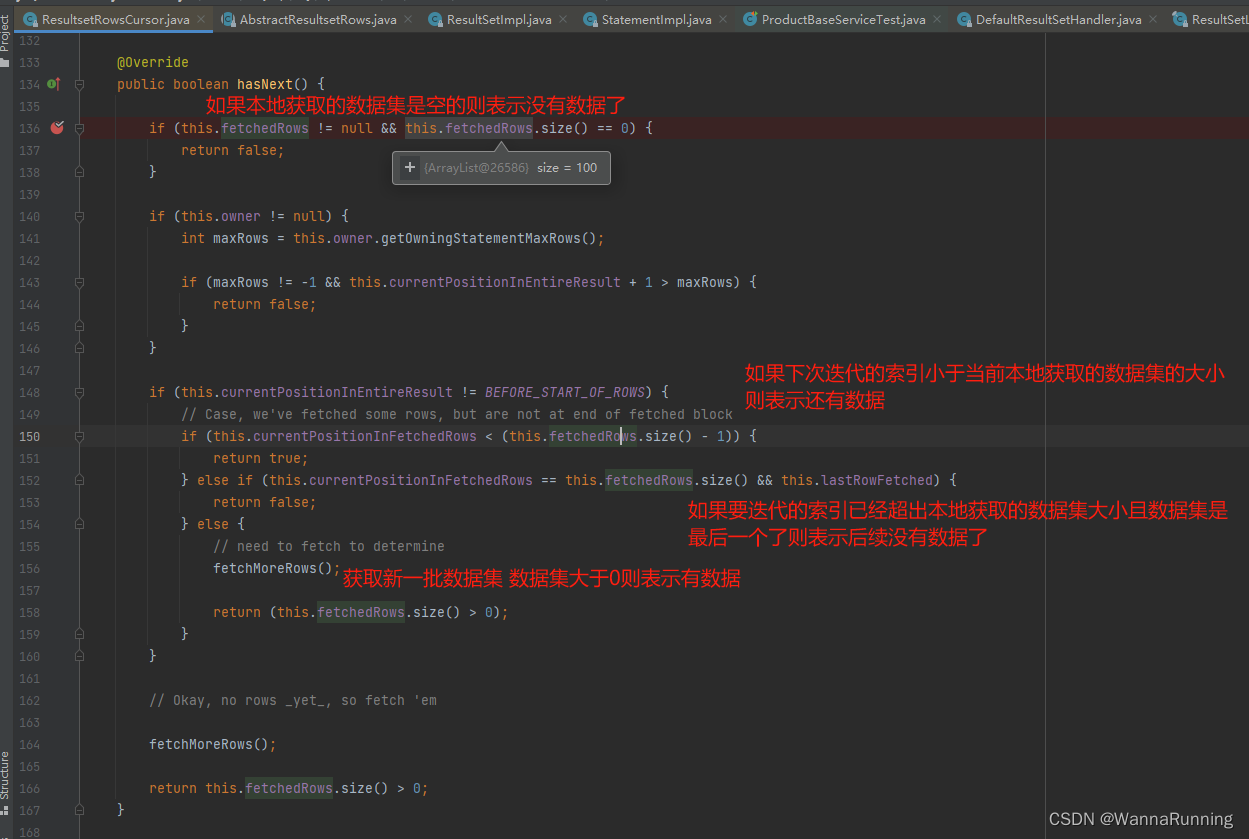
详细看下ResultsetRowsCursor这个实现类,主要是实现了Iterator的hasNext和next方法,这也是使用Cursor获取数据需要的两个方法。
下面是hasnext方法的逻辑,根据下次要获取的游标索引和当前本地数据集计算返回是否还有后续数据可以获取。
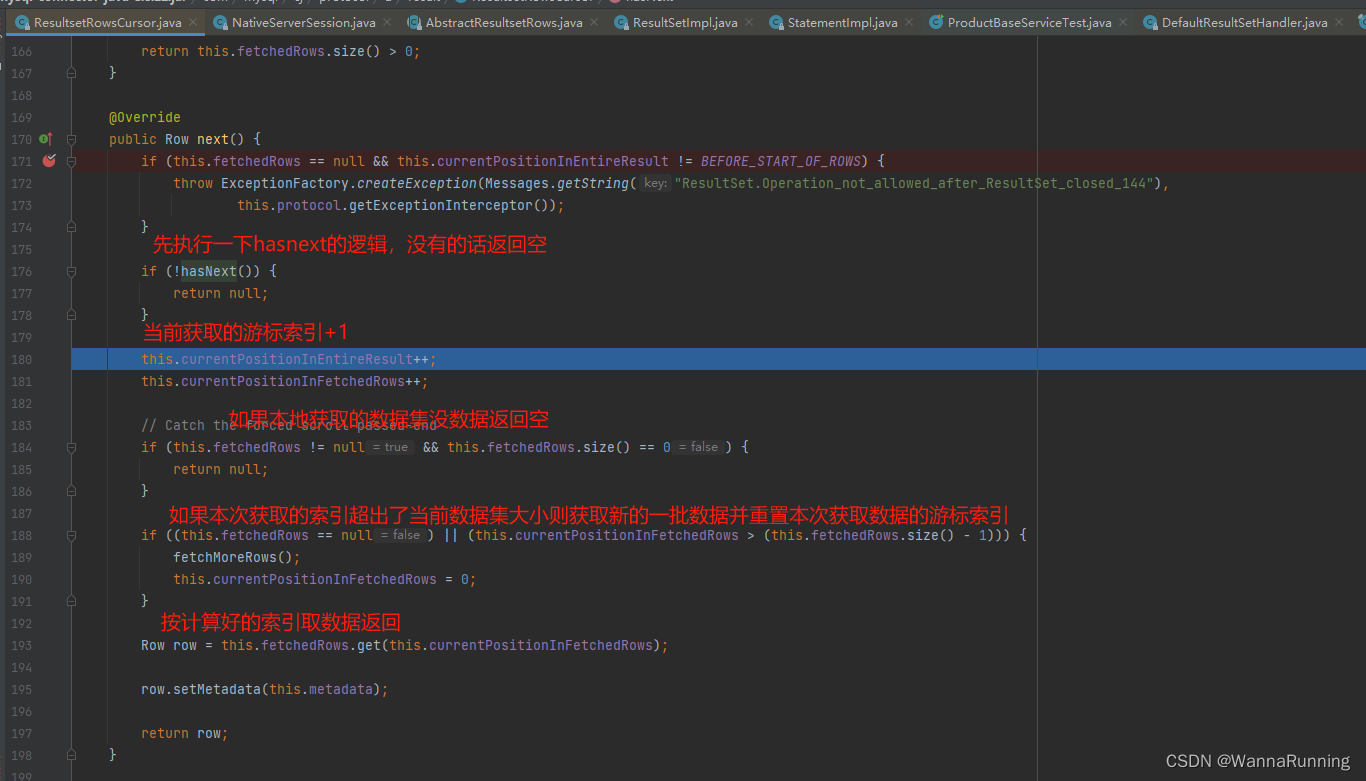
 下面是next方法的逻辑,先执行一下hasnext的逻辑判断,再取值
下面是next方法的逻辑,先执行一下hasnext的逻辑判断,再取值
这篇关于Mybatis集成MySQL使用游标查询处理大批量数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






