本文主要是介绍扎克伯格宣布将购买35万个GPU,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Meta公司马克.扎克伯格1月18日在Instagram上发表文章称,该公司正在加强人工智能研究团队的力量,并在充实AI基础设施“弹药库“,计划在今年年底前向芯片设计商英伟达购买35万个H100 GPU芯片,从而使该公司的GPU总量达到约60万个,跻身全球最强大的AI系统之列。
如今美国科技巨头均投入大量资源在人工智能领域,持续采购AI芯片。Meta公司首席科学家Yann LeCun上月在旧金山的一场活动强调GPU的重要性:“如果认为人工智能时代已经到来,就必须购买更多GPU。”他同时表示,这是一场AI战争,而英伟达CEO黄仁勋正在提供武器。
NVIDIA H100 GPU 主要参数
作为 A100 的替代,H100采用了当前最先进的台积电 4nm 工艺、单块芯片拥有800 亿个晶体管,可以加快 AI、HPC、内存带宽、互连和通信的发展,甚至能够实现每秒近 5 兆字节的外部连接,是第一个支持PCle Gen5和利用HBM3的GPU,使记忆体频宽达到3TB/s。
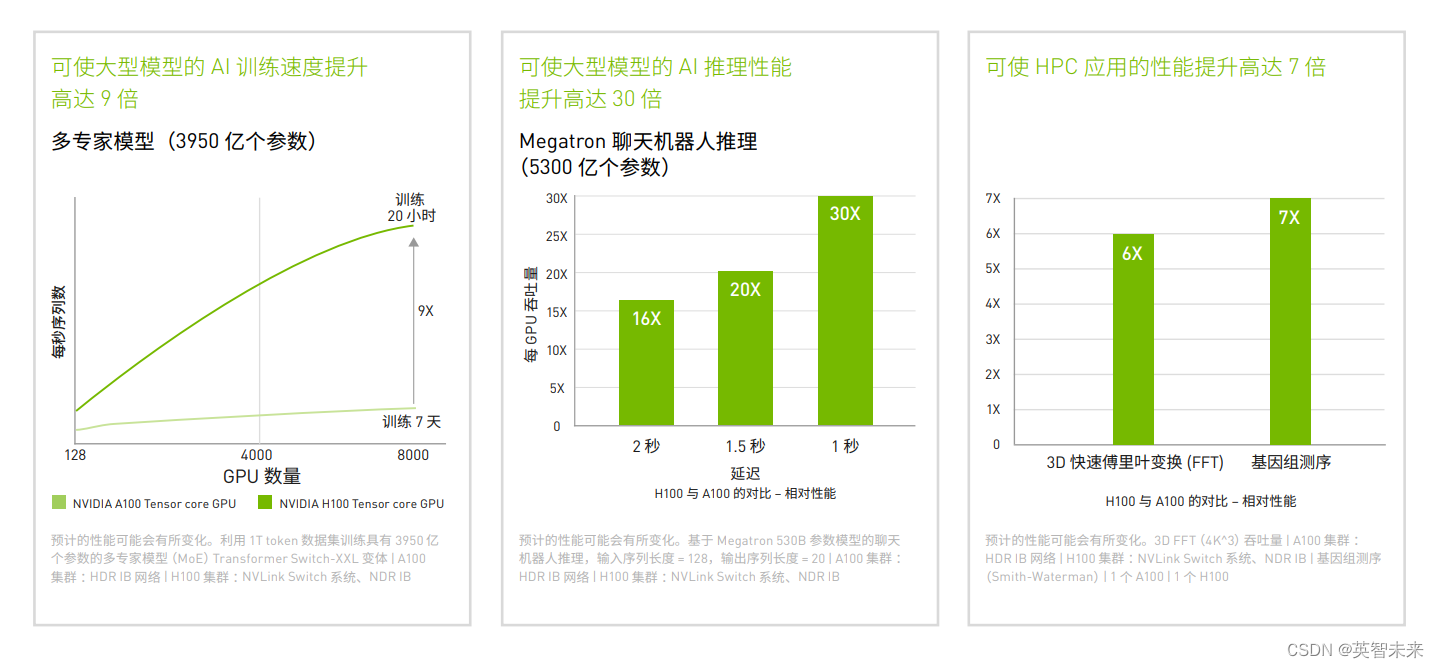
H100 配备第四代 Tensor Core 和 Transformer 引擎(FP8 精度),可使大型语言模型的训练速度提升高达 9 倍,推理速度提升 惊人的 30 倍。 对于高性能计算(HPC)应用,H100 可使 FP64 的每秒浮点运算次数 (FLOPS)提升至 3 倍,并可添加动态编程(DPX)指令,使性能提升高达 7 倍。借助第二代多实例 GPU (MIG)技术、内置的 NVIDIA 机密计算和 NVIDIA NVLink Switch 系统,H100 可安全地加速从企业级到百亿亿次级 (Exascale)规模的数据中心的各种工作负载。
由于基础大模型的本地训练成本不菲,H100一机难求,很多企业选择使用现成的人工智能数据中心设备和生成式AI服务器集群。baystoneai.com聚合全球智算算力资源GPU服务器,满足企业用户使用NVIDIA H100 GPU或其他算力资源,如有需求欢迎咨询作者
这篇关于扎克伯格宣布将购买35万个GPU的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








