本文主要是介绍每十分钟区间取数据,忽略时间精准度到每10分钟,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原本sql
select device_id,to_char(local_create_time, 'YYYY-MM-DD hh24:mi:00') local_create_time
,pump_frequency_sensor from device_data.data_achwp where device_id = '30_27' ORDER BY local_create_time ASC limit 10;
只能精准到秒没办法忽略分钟个位数,实例:
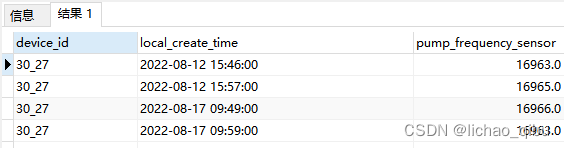
select device_id,
-- to_char(local_create_time, 'YYYY-MM-DD hh24:mi:ss') local_create_time
to_char( to_timestamp( (( EXTRACT ( epoch FROM local_create_time ) / 600) :: int8 - 1) * 600 ) - '8 hour'::interval, 'YYYY-MM-DD hh24:mi:ss' )
,pump_frequency_sensor from device_data.data_achwp where device_id = '30_27' ORDER BY local_create_time ASC limit 10;
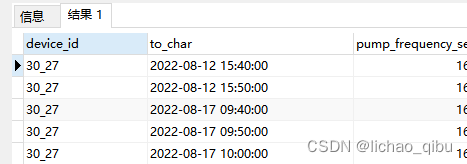
忽略分钟个位数
目前我的数据能保证每十分钟只有一条数据,如果十分钟多条数据,需要针对每十分钟进行数据分组,并对分组数据进行操作。
如果需要补位的情况需要配合下面这条sql
SELECTgenerate_series ( '2022-10-24 00:00:00' :: TIMESTAMP, NOW( ) :: TIMESTAMP, '10 min' );
搭配 函数
WITH “a” AS ( 表a),
b AS ( 表b)
) SELECT
*
FROM
“a” atb
LEFT JOIN b btb atb.关联时间= btb.关联时间
ORDER BY 分组字段
这篇关于每十分钟区间取数据,忽略时间精准度到每10分钟的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





