本文主要是介绍利用Python+SQL,用人货场的分析方法,对电商双十一促销活动进行复盘分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 背景
- 一、观察数据
- 1.1 数据来源:
- 1.2 读取数据:
- 二、分析思路
- 人货场
- 1. 整体情况(场)
- 2.商品情况(货)
- 3. 消费者情况(场)
- 三、计算并分析
- 3.1 处理数据
- 3.2 聚合数据
- 3.3 分析整体情况(场)
- 3.4 分析商品情况(货)
- 3.5 分析消费者情况(人)
- 四、总结
背景
某电商公司最近举行了一场促销活动,该案例是对此次活动的一次复盘和分析。所需要用到的工具有Python + SQL。
python会用到的库有:
- sqlalchemy
- pandas
- sklearn
一、观察数据
1.1 数据来源:
会用到数据库中的3个表的数据:
- 商品属性表(sales_item)
- 商品线上信息(sales_page)
- 用户订单表(sales_order)
1.2 读取数据:
步骤:
- import sqlalchemy
- 写sql读取语句
- 执行sql语句
- 用df.info()、df.head()去观察数据
import pandas as pd
import sqlalchemy
#此处忽略数据库连接地址
engine = sqlalchemy.create_engine('xxxx')#sql语句
sql_cmd = "select * from sales_item"# 执行sql语句,获取数据
sales_item = pd.read_sql(sql=sql_cmd, con=engine)sales_item.info()
sales_item.head(5)
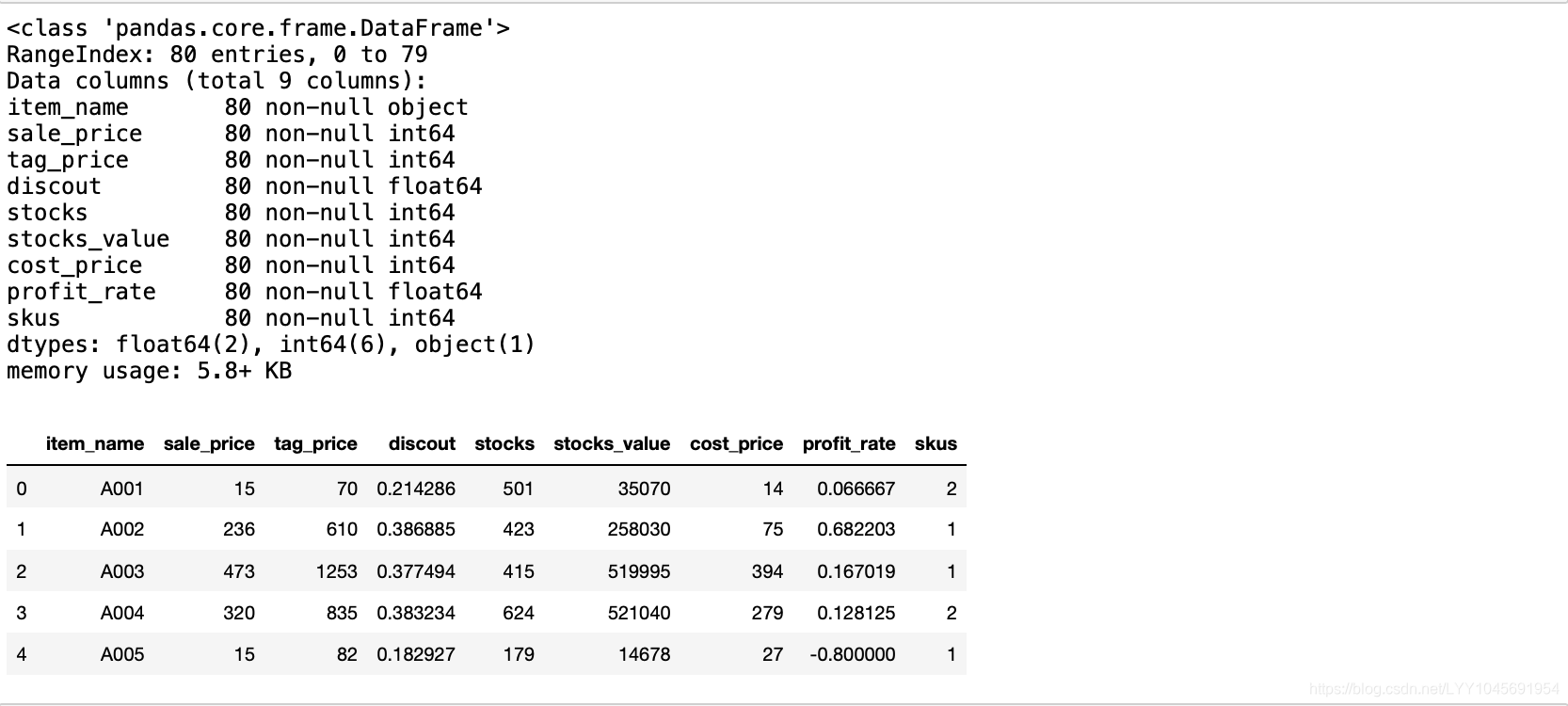
sql_cmd = "select * from sales_page"
sales_page = pd.read_sql(sql=sql_cmd, con=engine)sales_page.info()
sales_page.head(5)

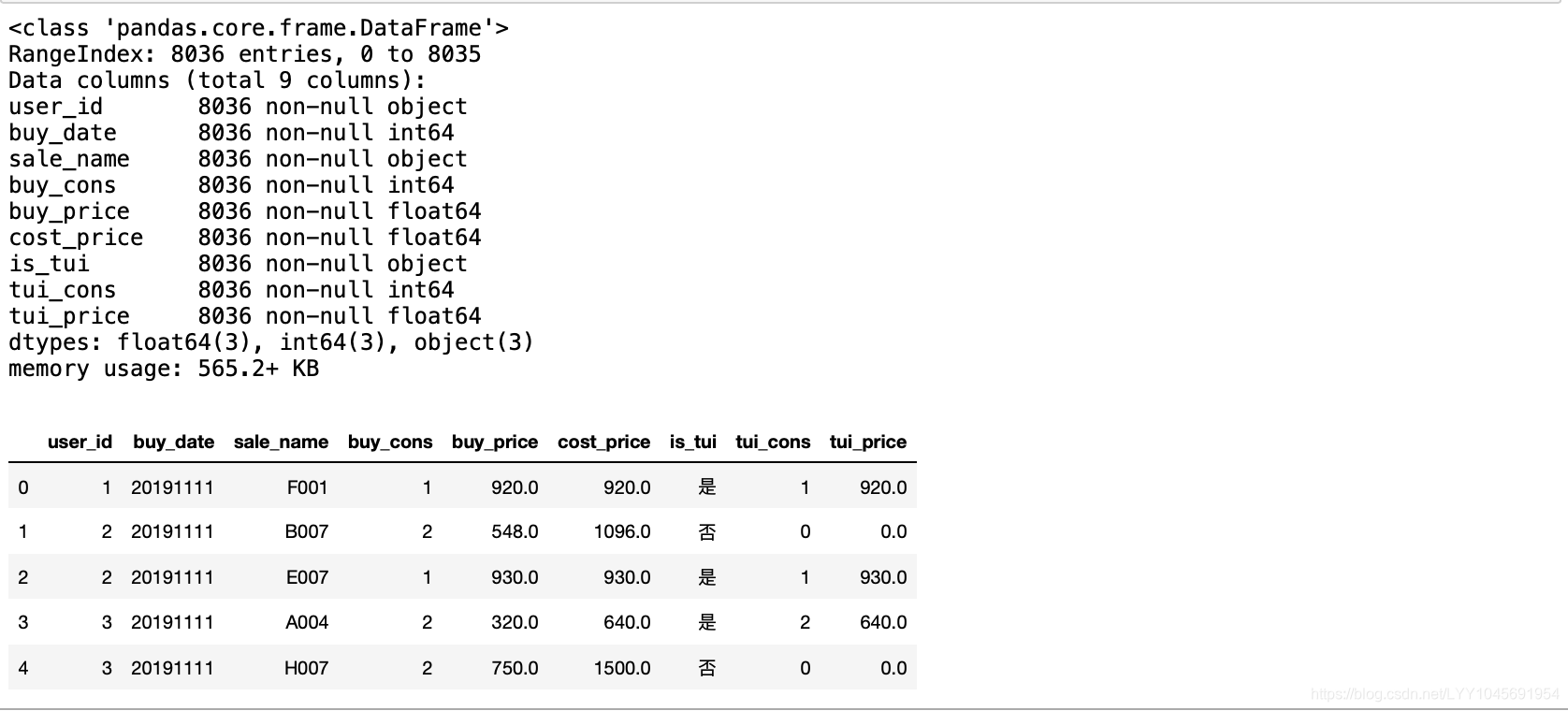
sql_cmd = "select * from sales_order"
sales_order = pd.read_sql(sql=sql_cmd, con=engine)sales_order.info()
sales_order.head(5)
二、分析思路
人货场
从人货场的角度去分析,其中”场“可以理解为是整理的运营情况。这里的分析不一定要按”人货场“的顺序,可以适当调节。
1. 整体情况(场)
1.1分析整体情况、并于去年的同比
2.商品情况(货)
2.1 什么商品在商品页面是吸引人的(衡量UV、加收藏、加购物车)
2.2 什么商品是用户需求多的(下单购买多)
2.3 什么商品是用户不满意的(被退回多)
2.4 什么商品能为公司带来更多利润
2.5 这些促销商品中,什么价格区间能吸引消费者下单
2.6 这些促销商品中,什么折扣区间能吸引消费者下单
3. 消费者情况(场)
3.1 哪些消费者是重要的(贡献金额较大)
3.2 哪些消费者存在一定风险(退货较多)
三、计算并分析
3.1 处理数据
先把表的属性改成中文,方便提供给其他部门做分析。
sales_item.rename(columns={"sale_name":"商品名","sale_price":"售卖价","tag_price":"吊牌价","discout":"折扣率","stocks":"库存量","stocks_value":"货值","cost_price":"成本价","profit_rate":"利润率","skus":"SKU"},inplace=True)sales_page.rename(columns={"sale_name":"商品名","uvs":"UV数","collections":"收藏数","carts":"加购物车数"},inplace=True)sales_order.rename(columns={"user_id":"用户id","buy_date":"购买日期","sale_name":"商品名","buy_cons":"购买数量","buy_price":"购买单价","cost_price":"购买金额","is_tui":"是否退货","tui_cons":"退货件数","tui_price":"退货金额"},inplace=True)
我们发现is_tui(是否退货)这里存的是object,检查除了“是和否”,是否还有其他字段。
sales_order["是否退货"].value_counts()

改成“1和0”,方便之后统计退货数
sales_order['是否退货']=sales_order["是否退货"].map({"是":1,"否":0})
3.2 聚合数据
sales_item和sales_page相连可以得到每个商品的商品属性以及在页面中的用户操作信息
再链接sales_order可以得到每个商品的订单信息
先对sales_order做统计汇总
# 统计每个商品的一个销售情况orderGroupByItem = sales_order.groupby("商品名").agg({"购买数量":"sum","购买金额":"sum","退货件数":"sum","退货金额":"sum","购买单价":"mean","用户id":pd.Series.nunique}).reset_index()
orderGroupByItem.rename(columns={"购买数量":"商品销售数量","购买金额":"商品销售金额","是否退货":"商品退货数量","退货金额":"商品退货金额","购买单价":"商品销售单价","用户id":"购买用户数量"},inplace=True)
orderGroupByItem.head()
再连接三个表:
item_page = sales_item.merge(sales_page,how="left",on="商品名")
dt = item_page.merge(orderGroupByItem,how="left",on="商品名")
3.3 分析整体情况(场)
总体运营部分,主要关注销售额、售卖比、UV、转化率等指标,其他指标作为辅助指标。销售额用来和预期目标做对比,售卖比用来看商品流转情况。
- GMV:销售额,即到手价。
- 实销:GMV – 拒退金额。
- 销量:累计销售量(含拒退)。
- 客单价:GMV / 客户数,客单价与毛利率息息相关,一般客单价越高,毛利率越高。
- UV:商品所在页面的独立访问数。
- 转化率:客户数 / UV。
- 折扣率:GMV / 吊牌总额(吊牌总额 = 吊牌价 * 销量),在日常工作中,吊牌额是必不可少的。
- 备货值:吊牌价 * 库存数。
- 售卖比:又称售罄率,GMV / 备货值。
- 收藏数:收藏某款商品的用户数量。
- 加购数:加购物车人数。
- SKU数:促销活动中的SKU计数(一般指货号)。
- SPU数:促销活动中的SPU计数(一般指款号)。
- 拒退量:拒收和退货的总数量。
- 拒退额:拒收和退货的总金额。
#1、GMV:销售额,包含退货的金额
gmv = dt["商品销售金额"].sum() #3747167.0#2、实际销售额=GMV - 退货金额
return_sales = dt["商品退货金额"].sum()
return_money = gmv - return_sales #2607587.0#3、销量:累计销售量(含拒退)
all_sales = dt["商品销售数量"].sum()
all_sales #12017#4、客单价:GMV / 客户数,客单价与毛利率息息相关,一般客单价越高,毛利率越高。custom_price = gmv / dt["购买用户数量"].sum()
custom_price #493.56783456269756# 5、UV:商品所在页面的独立访问数
uv_cons = dt["UV数"].sum() #1176103# 6、转化率:客户数 / UV。
uv_rate = dt["购买用户数量"].sum() / dt["UV数"].sum()
uv_rate #0.006455216932530569# 7、折扣率:GMV / 吊牌总额(吊牌总额 = 吊牌价 * 销量),在日常工作中,吊牌额是必不可少的。
tags_sales = np.sum(dt["吊牌价"] * dt["商品销售数量"])
discount_rate= gmv / tags_sales
discount_rate #0.4179229541452886# 8、备货值:吊牌价 * 库存数。
goods_value = dt["货值"].sum()
goods_value #18916395# 9、售卖比:又称售罄率,GMV / 备货值。
sales_rate = gmv / goods_value
sales_rate #0.19809096817866195# 10、收藏数:收藏某款商品的用户数量。
coll_cons = dt["收藏数"].sum()
coll_cons 6224# 11、加购数:加购物车人数。
add_shop_cons = dt["加购物车数"].sum()
add_shop_cons #18690# 12、SKU数:促销活动中的最小品类单元(一般指货号)。
sku_cons = dt["SKU"].sum()
sku_cons #125# 13、SPU数:促销活动中的SPU计数(一般指款号)。
spu_cons = len(dt["商品名"].unique())
spu_cons #80# 14、拒退量:拒收和退货的总数量。退货件数
reject_cons = dt["退货件数"].sum()
reject_cons #3643# 15、拒退额:拒收和退货的总金额。
reject_money = dt["商品退货金额"].sum()
reject_money #1139580.0# 汇总统计
sales_state_dangqi = pd.DataFrame({"GMV":[gmv,],"实际销售额":[return_money,],"销量":[all_sales,],"客单价":[custom_price,],"UV数":[uv_cons,],"UV转化率":[uv_rate,],"折扣率":[discount_rate,],"货值":[goods_value,],"售卖比":[sales_rate,],"收藏数":[coll_cons,],"加购数":[add_shop_cons,],"sku数":[sku_cons,],"spu数":[spu_cons,],"拒退量":[reject_cons,],"拒退额":[reject_money,],}, ) #index=["今年双11",]# 去年的数据是已经统计好了的,不需要计算(写死的内容)
sales_state_tongqi = pd.DataFrame({"GMV":[2261093,],"实际销售额":[1464936.517,],"销量":[7654,],"客单价":[609.34567,],"UV数":[904694,],"UV转化率":[0.0053366,],"折扣率":[0.46,],"货值":[12610930,],"售卖比":[0.1161,],"收藏数":[4263,],"加购数":[15838,],"sku数":[82,],"spu数":[67,],"拒退量":[2000,],"拒退额":[651188.57,],}, ) #index=["去年双11",]#sales_state = pd.concat([sales_state_dangqi, sales_state_tangqi])
sales_state_dangqi_s = pd.DataFrame(sales_state_dangqi.stack()).reset_index().iloc[:,[1,2]]
sales_state_dangqi_s.columns = ["指标","今年双11"]
sales_state_tongqi_s = pd.DataFrame(sales_state_tongqi.stack()).reset_index().iloc[:,[1,2]]
sales_state_tongqi_s.columns = ["指标","去年双11"]
sales_state = pd.merge(sales_state_dangqi_s, sales_state_tongqi_s,on="指标")
sales_state["同比"] = (sales_state["今年双11"] - sales_state["去年双11"]) / sales_state["去年双11"]
sales_state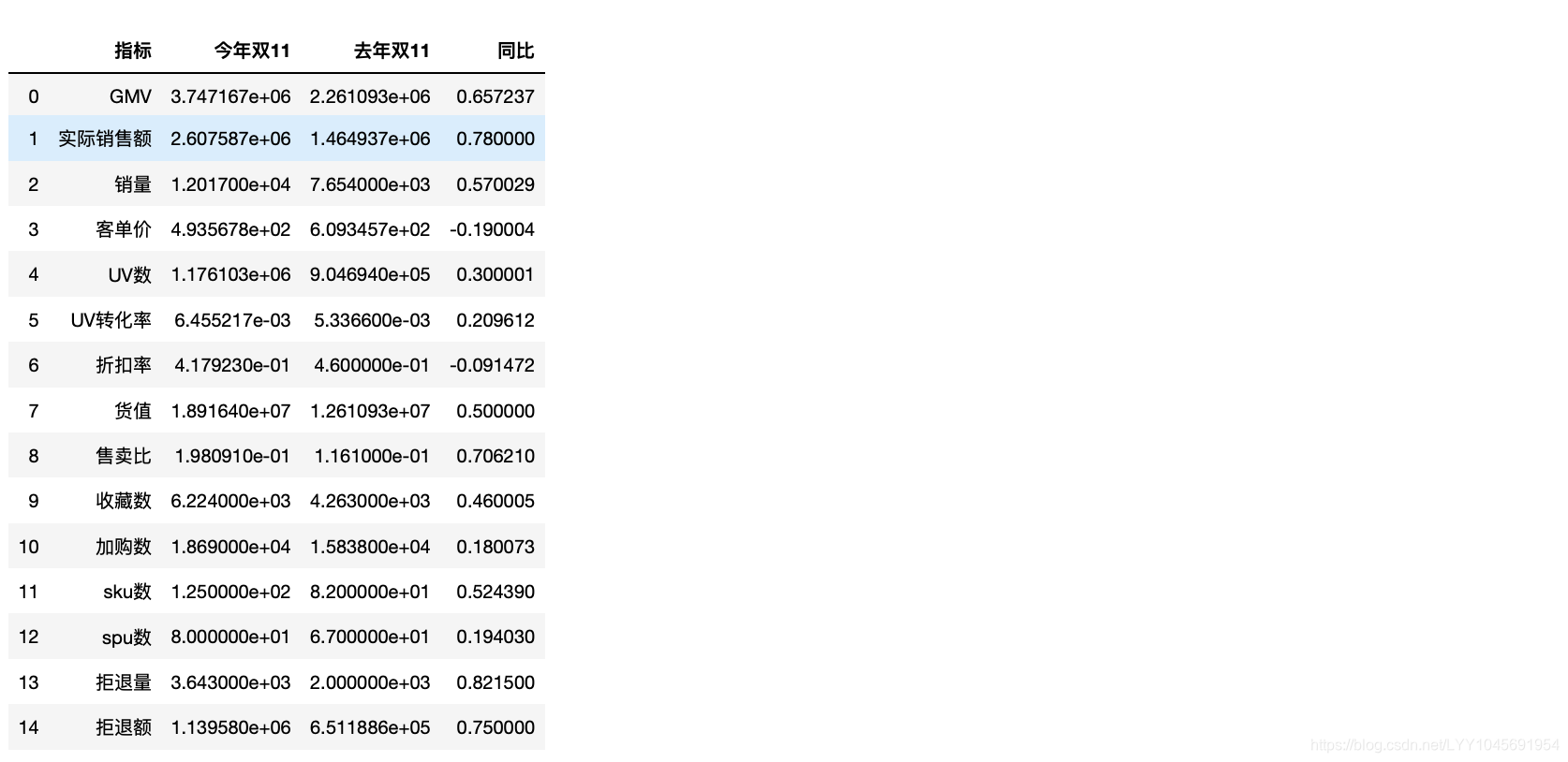
3.4 分析商品情况(货)
步骤三、从商品的角度细分问题
2.1 什么商品在商品页面是吸引人的(衡量UV、加收藏、加购物车)
步骤:
- 用item_page(sales_item 和 sales_page的合并)分析每个商品的热度
- 对UV数、收藏数、加购物车数这三个指标做归一化
- 对着三个指标给一定的权重算分数,去衡量商品的热度
from sklearn import preprocessingitem_page.head()
item_page["加购率"]=item_page["加购物车数"]/item_page["UV数"]
scaler = preprocessing.MinMaxScaler()
scaler.fit(item_page[["UV数","收藏数","加购物车数"]])
scaled_item_page = scaler.transform(item_page[["UV数","收藏数","加购物车数"]])scaled_item_page = pd.DataFrame(scaled_item_page,columns=["归一化UV数","归一化收藏数","归一化加购物车数"])
scaled_item_pagescaled_item_page=pd.concat([item_page,scaled_item_page],axis=1)
#加购物车:6,加收藏:3,UV:1
scaled_item_page["分数"]=scaled_item_page["归一化UV数"]*1+scaled_item_page["归一化收藏数"]*3+scaled_item_page["归一化加购物车数"]*6scaled_item_page.sort_values(by="分数",ascending=False)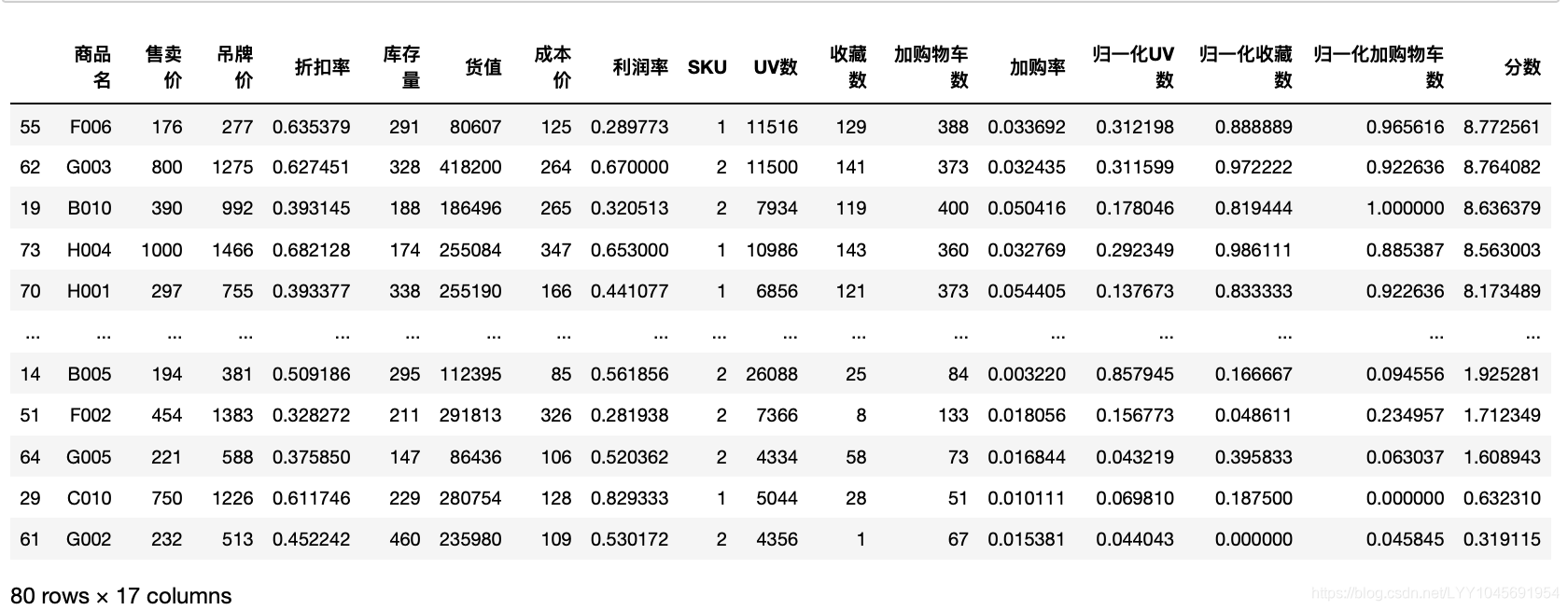
scaled_item_page.sort_values(by="分数",ascending=False).head(5)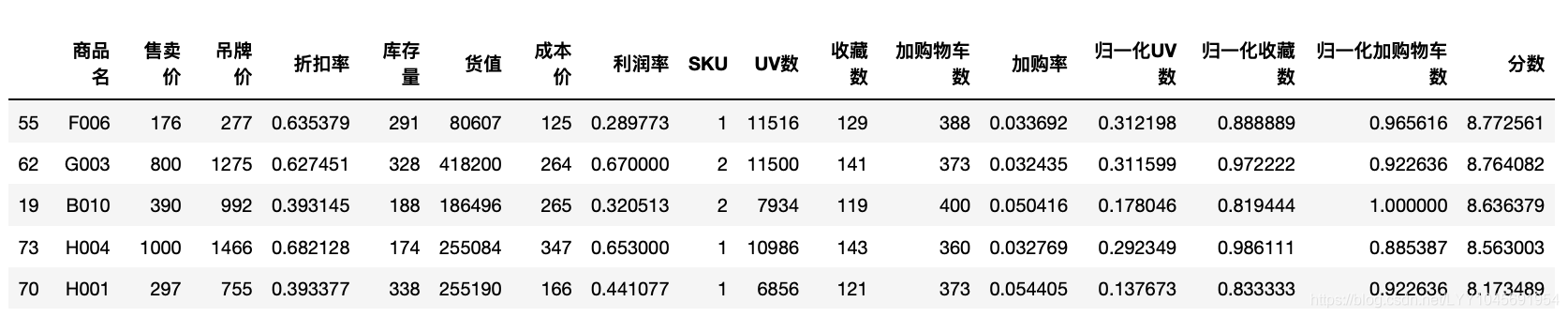
2.2 什么商品是用户需求多的(购买多)
继续从商品的角度,针对订单表带来的信息,对商品订单进行分析:
先回顾一下orderGroupByItem表
orderGroupByItem.info()
orderGroupByItem.head(5)
增加一列实际成功售出(购买总数-退货总数),排列展示出来。
orderGroupByItem["实际售出"]=orderGroupByItem["商品销售数量"]-orderGroupByItem["退货件数"]查看什么商品是用户需求多的
orderGroupByItem.sort_values(by=["商品销售数量","购买用户数量"],ascending=[False,False]).head(5)
2.3 什么商品是用户不满意的(被退回多)
orderGroupByItem.sort_values(by=["退货件数","购买用户数量"],ascending=[False,False]).head(5)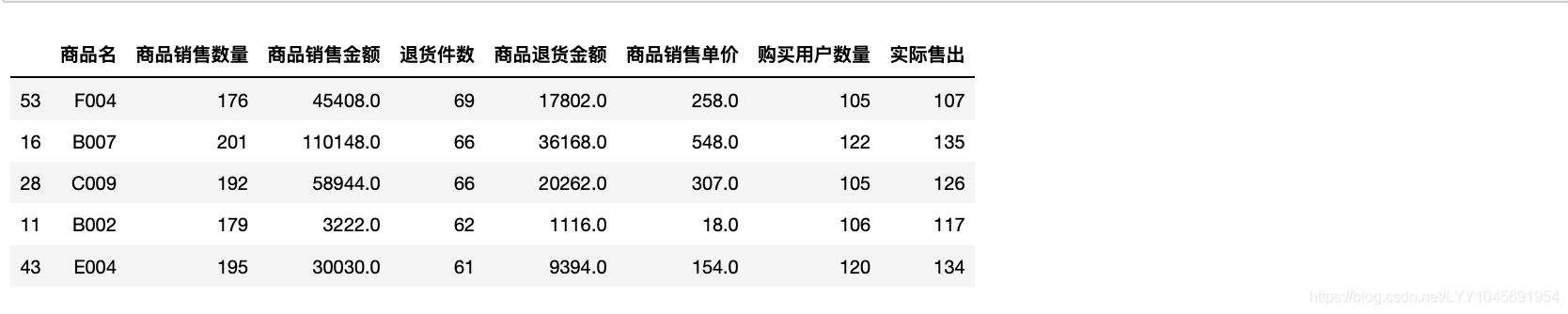
2.4 什么商品能为公司带来更多利润
dt["实际总利润"]=dt["售卖价"]*dt["利润率"]*dt["商品销售数量"]
dt[["商品名","售卖价","吊牌价","折扣率","利润率","实际总利润"]].sort_values(by="实际总利润",ascending=False).head(5)
2.5 这些促销商品中,什么价格区间能吸引消费者下单
一般来说,价格越低消费者越能接受,越想下单。但是要考虑转化率和退货率。
回顾一下dt表,因为三表合并后维度较大,有(80,20)的shape
dt = item_page.merge(orderGroupByItem,how="left",on="商品名")
dt.shape #(80,20)
检查售卖价是否与平均购买单价一致,如果是的话可以删除一列
sum(dt["商品销售单价"]==dt["售卖价"])
上面的结果为80,即=商品数,即每个的售卖价与平均购买单价一致,删掉其中一列
dt.drop(["商品销售单价"],axis=1,inplace=True)
观察一下售卖价怎么分组
dt["售卖价"].describe()

最低为9,最高为1000,标准差为约等于221,可以大致分为4等分。
priceBins=[0,250,500,750,1000]
priceLabels=["0-250","250-500","500-750","750-1000"]
dt["价格分组"]=pd.cut(dt["售卖价"],priceBins,labels=priceLabels)priceDt=dt.groupby("价格分组").agg({"商品名":pd.Series.nunique,"UV数":"sum","收藏数":"sum","加购物车数":"sum","商品销售数量":"sum","商品销售金额":"sum","退货件数":"sum","购买用户数量":"sum"
}).reset_index()priceDt.rename(columns={"商品名":"商品数"},inplace=True);
priceDt
增加几个指标,去判断消费者对这个价格的接受能力
#消费者数占比,销售占比、客单价、转化率等
priceDt["实际售出"]=priceDt["商品销售数量"]-priceDt["退货件数"]
priceDt["退货率"]=priceDt["退货件数"]/priceDt["商品销售数量"]
priceDt["消费者数占比"]=priceDt["购买用户数量"]/priceDt["购买用户数量"].sum()
priceDt["销售占比"]=priceDt["商品销售金额"]/priceDt["商品销售金额"].sum()
priceDt["客单价"]=priceDt["商品销售金额"]/priceDt["购买用户数量"]
priceDt["转化率"]=priceDt["购买用户数量"]/priceDt["UV数"]
priceDt
750-1000的转化率较高,说明用户在浏览了商品页面后下单的概率较大。但是因为这个价格区间商品数较少,可能受某件商品影响较大。同时商品的退货率也相对较高。因为商品数较少,可以查看这个商品的具体数据,看看是否有异常。
dt[dt["价格分组"]=="750-1000"][["商品名","折扣率","UV数","收藏数","加购物车数","商品销售数量","退货件数","购买用户数量"]]
查看全部商品的描述性统计
dt[["商品名","折扣率","UV数","收藏数","加购物车数","商品销售数量","退货件数","购买用户数量"]].describe()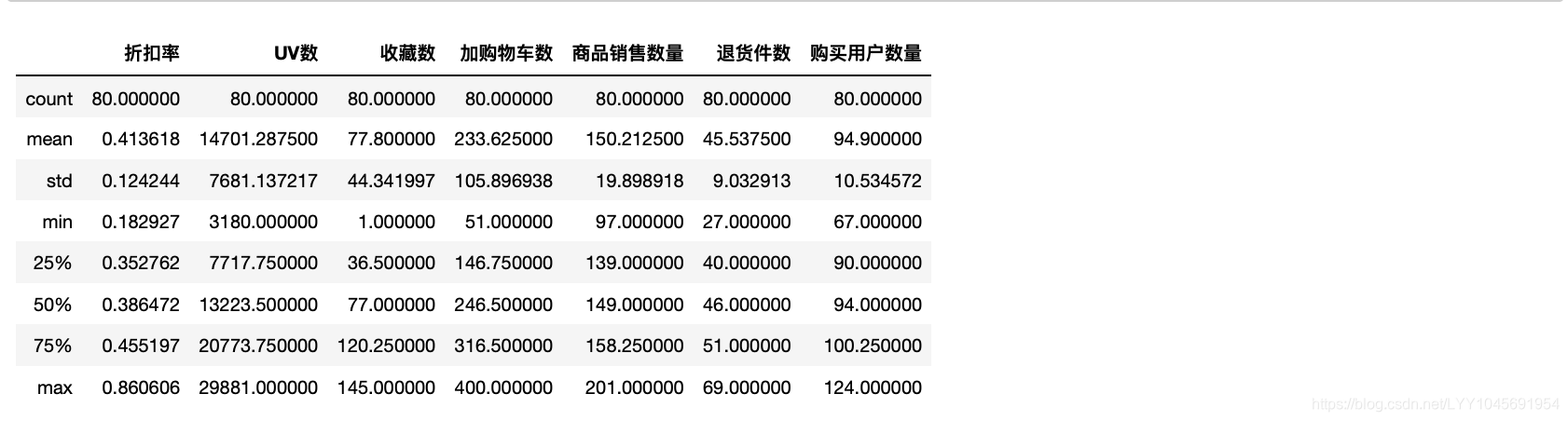
对比价格区间在750-1000可以看出,价格区间在750-1000的UV值都低于平均值,但收藏值都高于平均值,商品G003,H004的收藏之接近最高,加购物车数除了F001,其他表现很好。销售数据表现不错,但退货件数也比较高。购买用户数除了F001,其他都在平均值附近。推测这组数据转化率较高原因是UV较少,提升了转化率。
转化率第二高的是500-750,这个价格区间的退货数也比较低。但是也是受商品数量较少的影响,去证明消费者对这个价格区间能接受的说服力不够。因为数量较少,也可以查看具体商品详情。

查看具体商品详情,发现这个价格区间也是UV数较低,售出数量与整体的平均值相似。同时可以看见H007的UV数低、收藏数、加购物车数以及销售数据较高,转化率高达0.03517(159/4520),此价格区间的平均转化率为0.006890,整体转化率为0.0064552,推测该款商品如果能被曝光更多,可以带来更多的销售。
总的来说,这些促销商品中,500-1000这个价格区间的转化率不错,能吸引消费者下单。
2.6这些促销商品中,什么折扣区间能吸引消费者下单
dt["折扣率"].describe()

discntBins=[0.15,0.3,0.45,0.6,0.75,0.9]
discntLabels=["15折-3折","3折-45折","45折-6折","6折-75折","75折-9折"]
dt["折扣分组"]=pd.cut(dt["折扣率"],discntBins,labels=discntLabels)discntDt=dt.groupby("折扣分组").agg({"商品名":pd.Series.nunique,"UV数":"sum","收藏数":"sum","加购物车数":"sum","商品销售数量":"sum","商品销售金额":"sum","退货件数":"sum","购买用户数量":"sum"
}).reset_index()discntDt.rename(columns={"商品名":"商品数"},inplace=True);
discntDt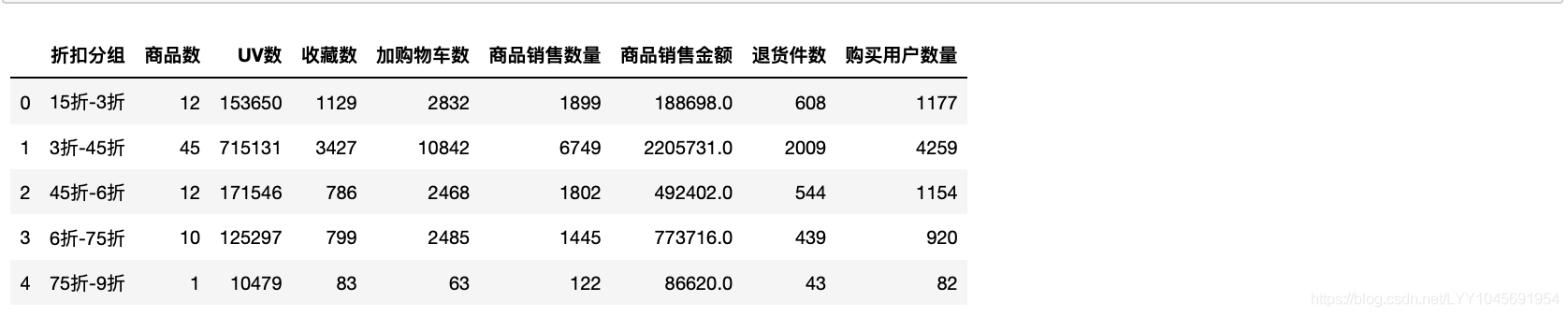
这样分组的话75-9折只有一件商品,再试试做调整。
discntBins=[0,0.3,0.6,0.9]
discntLabels=["3折以下","3-6折","6折以上"]
dt["折扣分组"]=pd.cut(dt["折扣率"],discntBins,labels=discntLabels)discntDt=dt.groupby("折扣分组").agg({"商品名":pd.Series.nunique,"UV数":"sum","收藏数":"sum","加购物车数":"sum","商品销售数量":"sum","商品销售金额":"sum","退货件数":"sum","购买用户数量":"sum"
}).reset_index()discntDt.rename(columns={"商品名":"商品数"},inplace=True);
discntDt
#消费者数占比,销售占比、客单价、转化率
discntDt["实际售出"]=discntDt["商品销售数量"]-discntDt["退货件数"]
discntDt["退货率"]=discntDt["退货件数"]/discntDt["商品销售数量"]
discntDt["消费者数占比"]=discntDt["购买用户数量"]/discntDt["购买用户数量"].sum()
discntDt["销售占比"]=discntDt["商品销售金额"]/discntDt["商品销售金额"].sum()
discntDt["客单价"]=discntDt["商品销售金额"]/discntDt["购买用户数量"]
discntDt["转化率"]=discntDt["购买用户数量"]/discntDt["UV数"]
discntDt
3折以下的转化率最高,折扣越高,对消费者的吸引力越大,猜测会让消费者感到买到就是赚得到。但是能看到3折以下的退货率也是最高的。看平均每件商品的热度信息和订单信息。
discntDt["平均UV"]=discntDt["UV数"]/discntDt["商品数"]
discntDt["平均收藏"]=discntDt["收藏数"]/discntDt["商品数"]
discntDt["平均加购物车"]=discntDt["加购物车数"]/discntDt["商品数"]
discntDt["平均商品销售数量"]=discntDt["商品销售数量"]/discntDt["商品数"]discntDt["平均用户数"]=discntDt["购买用户数量"]/discntDt["商品数"]
discntDt[["折扣分组","商品数","平均UV","平均收藏","平均加购物车","平均商品销售数量","平均退货件数","平均用户数"]]
3折以下的,除了平均UV数不是最高,其他的都是最高的,消费者对低折扣还是最心动的。
3.5 分析消费者情况(人)
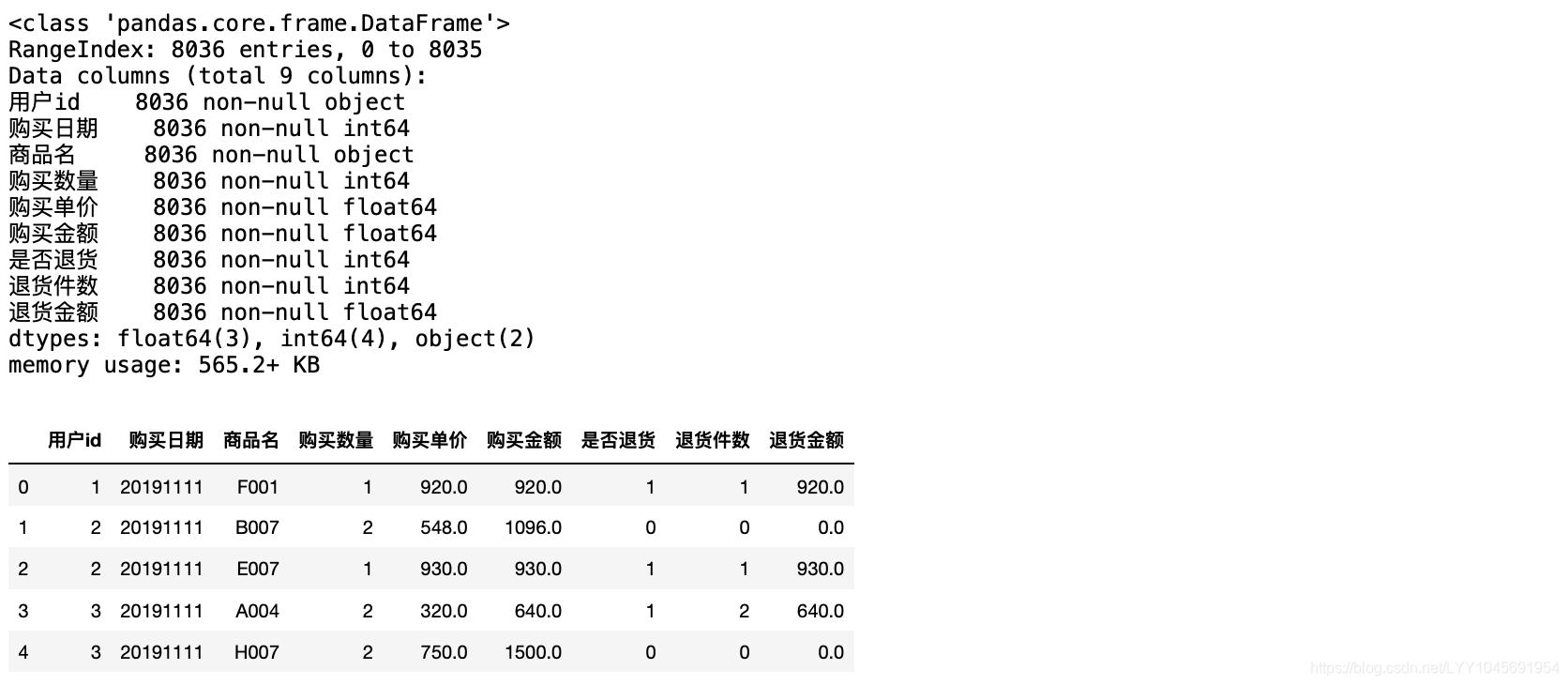
这时候只看sales_order。
回顾一下这个表
3.1 哪些消费者是重要的(贡献金额较大)
users_info=sales_order.groupby("用户id").agg({"商品名":pd.Series.nunique,"购买日期":"count","购买数量":"sum","购买单价":"mean","购买金额":"sum","是否退货":"sum","退货件数":"sum","退货金额":"sum"}).reset_index()
users_info.rename(columns={"购买日期":"购买次数","商品名":"购买商品数","购买单价":"客单价","是否退货":"退货次数"},inplace=True)
users_info["实际贡献"]=users_info["购买金额"]-users_info["退货金额"]users_info.sort_values(by=["实际贡献","购买金额","购买数量"],ascending=[False,False,False]).head(10)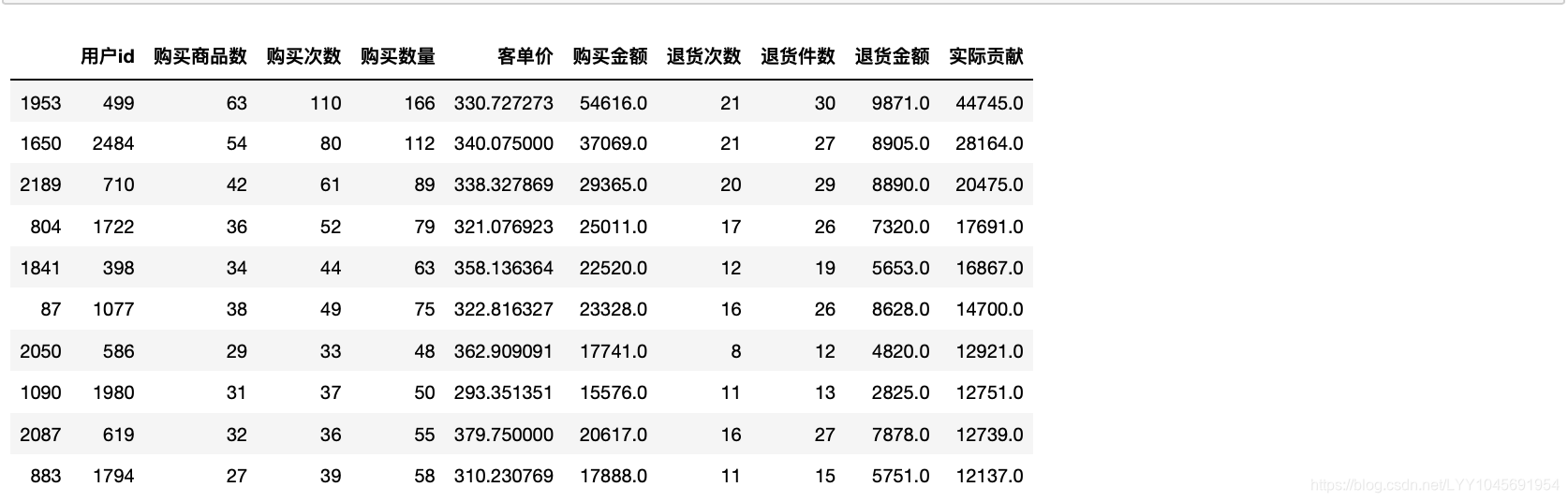
3.2 哪些消费者存在一定风险(退货较多)
users_info.sort_values(by=["退货件数","退货金额"],ascending=[False,False]).head(10)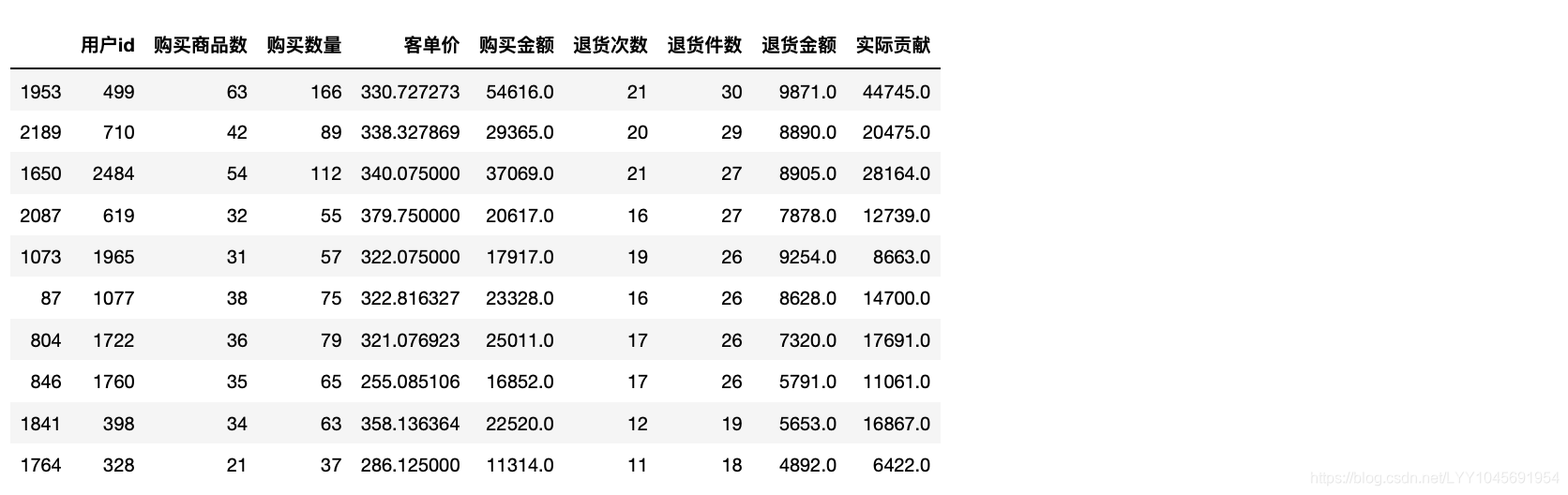
这里面有一些消费者在贡献top里,他们退货多的原因有可能也是因为购买较多,尝试计算退货率。
users_info["退货率"]=users_info["退货件数"]/users_info["购买数量"]
users_info.sort_values(by=["退货率","退货件数"],ascending=[False,False]).head(10)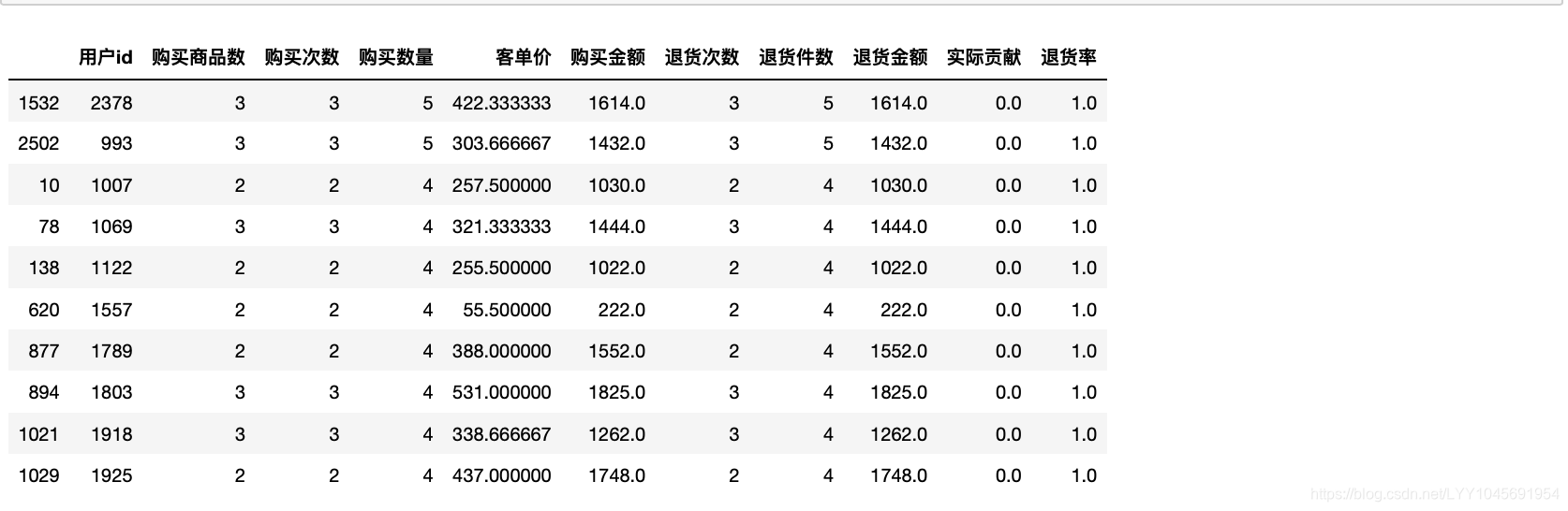
会出现一个新的问题:有的用户购买得少又都退了,那么凭退货率被定义为风险客户的话是不明智的。此时需要更多的消费者数据去做支持。
四、总结
今年双十一的整体指标除了客单价和折扣率都同比上升了,今年的促销活动比去年有进步。
消费者对商品的折扣率比较敏感,折扣越低UV等指标越高。
消费者这里没有更多更远的数据去做支持,不能下结论。
这篇关于利用Python+SQL,用人货场的分析方法,对电商双十一促销活动进行复盘分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







