本文主要是介绍(二十)Flask之上下文管理第一篇(粗糙缕一遍源码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
每篇前言:
🏆🏆作者介绍:【孤寒者】—CSDN全栈领域优质创作者、HDZ核心组成员、华为云享专家Python全栈领域博主、CSDN原力计划作者
- 🔥🔥本文已收录于Flask框架从入门到实战专栏:《Flask框架从入门到实战》
- 🔥🔥热门专栏推荐:《Python全栈系列教程》、《Django框架从入门到实战》、《爬虫从入门到精通系列教程》、《前端系列教程》、《tornado一条龙+一个完整版项目》。
- 📝📝本专栏面向广大程序猿,为的是大家都做到Flask从入门到精通,穿插有很多实战优化点。
- 🎉🎉订阅专栏后可私聊进一千多人Python全栈交流群(手把手教学,问题解答); 进群可领取Python全栈教程视频 + 多得数不过来的计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 🚀🚀加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!
引子:
当一个客户端,比如浏览器,向 Flask 服务发起 HTTP 请求,它首先会被 Web 服务器(如 gunicorn 或 uWSGI)接收。这个 Web 服务器的任务不仅仅是接收请求,它还作为 Flask 应用程序与外部环境之间的桥梁。
为了使 Web 服务器和 Python Web 应用程序能够“对话”,我们需要一个规范或者说是一个协议。这就是 WSGI,即 Web Server Gateway Interface。Flask 利用 Werkzeug 这一 WSGI 工具库来满足这个规范的需求。
现在,当一个 HTTP 请求达到 Web 服务器,Werkzeug 会介入并起到关键作用。它的职责是从原始 HTTP 请求中提取出有意义的数据,并将其转化为 Flask 可以轻松操作的格式。这意味着,原始的请求数据如:
GET /index.html HTTP/1.1
Host: www.example.com
会被 Werkzeug 解析,并且转化为 Flask 可以直接使用的请求对象,比如 flask.request。这样,开发者可以轻松地访问请求的各个部分,例如 headers、query parameters、body 等,无需深入了解底层的 HTTP 协议。
简而言之,通过 WSGI 和 Werkzeug 的配合,当 HTTP 请求达到 Flask 应用时,我们可以直观、高效地处理它,使开发变得更为简洁。
看源码捋一下一个完整请求在Flask里整个生命周期都干了啥?
前面讲过请求一旦到来,就会执行app.__call__方法:
from flask import Flaskapp = Flask(__name__)@app.route('/')
def hello_world():return 'hello world'if __name__ == '__main__':app.__call__app.run()进入__call__方法:
【需要注意的是:参数environ 已经是一个经过 WSGI 服务器处理后的字典,它包含了所有与 HTTP 请求相关的信息。即当一个 HTTP 请求到达 WSGI 服务器时,服务器会解析这个请求,并将相关的信息转化为 environ 字典中的一系列键值对!】
(拓展:start_response 是 WSGI 规范中定义的一个回调函数,它的主要作用是设置响应的状态和 HTTP 头部。当你的应用程序决定如何响应请求时,它需要调用这个函数来开始发送响应)
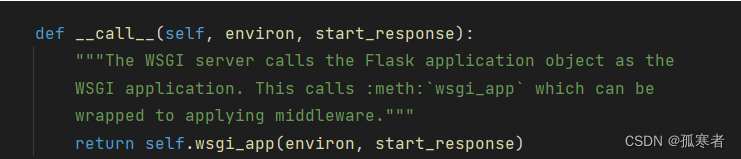
继续进去:
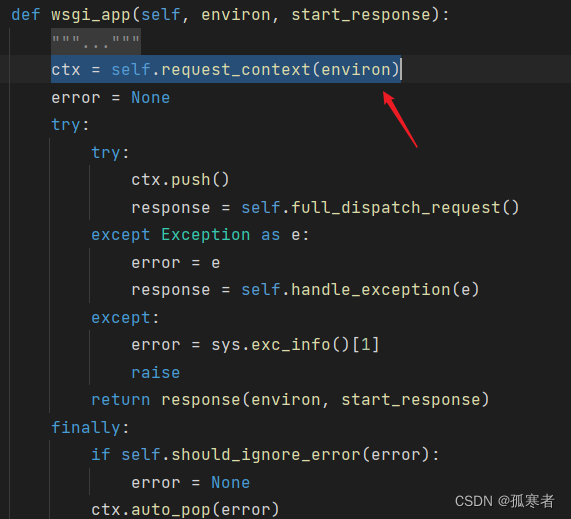
上面选中那一句实现了三个功能:
- 将WSGI处理之后的请求数据environ又处理了一遍;
- 设置session为None;
- 实现路由匹配(根据url找到对应视图函数)。
下面扣源码来证实~
进去request_context:
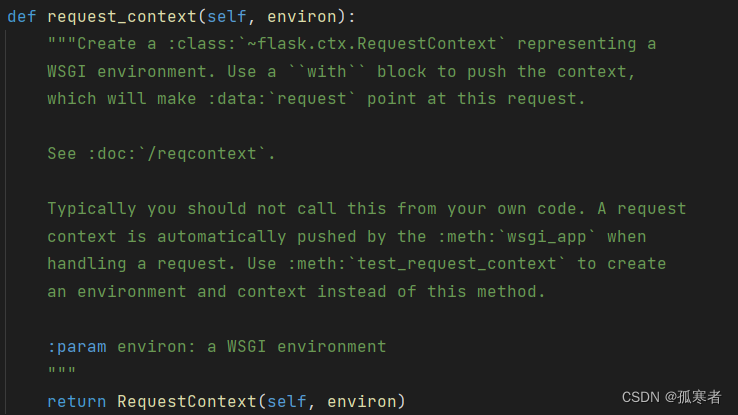
继续进去:
- 下图第一个箭头所指位置就是功能一:将WSGI处理之后的请求数据environ又处理了一遍。主要任务就是将 WSGI 提供的
environ字典转换为 Flask 可以更容易处理的请求对象(可以自己继续进源码去探究) - 下图第二个箭头所指位置就是功能二:设置session为None。
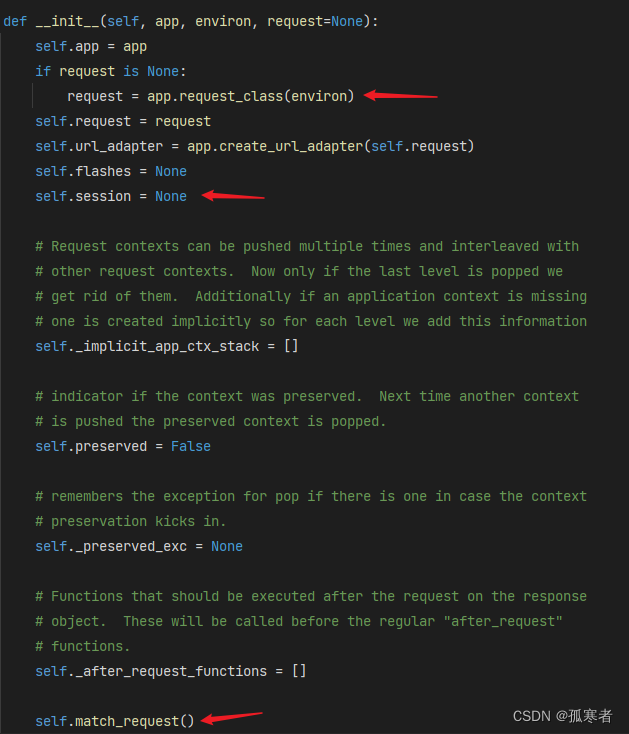
而上图最后一个箭头所指位置就是功能三:实现路由匹配(后续深入讲解)~
回到wsgi_app函数,继续下一句:
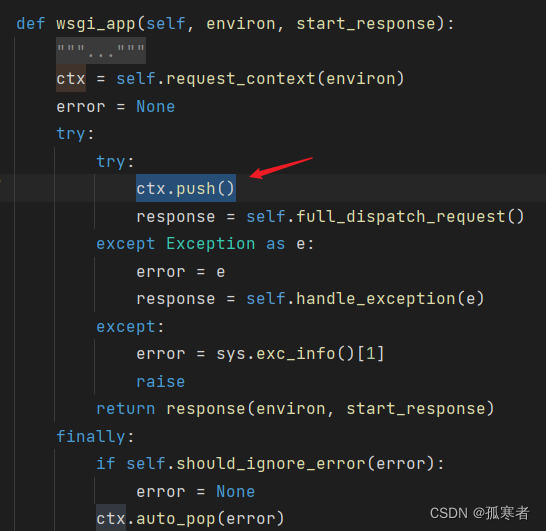
进去:
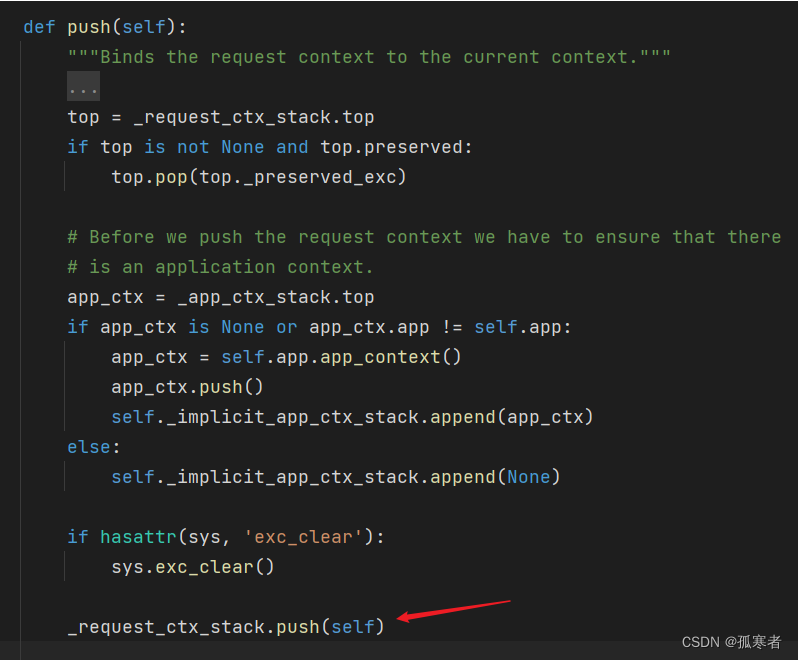
其他部分先不管,直接看上图箭头所指位置,是不是很眼熟?
- 这部分就是Flask使用了自己实现的threading.local()对象!
进去_request_ctx_stack对象:
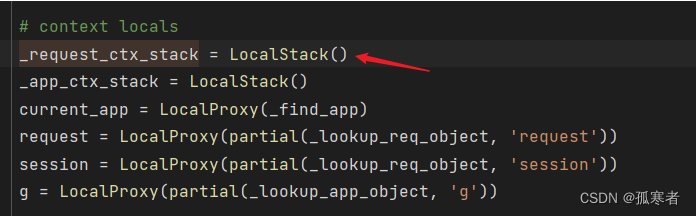
进去LocalStack()对象:
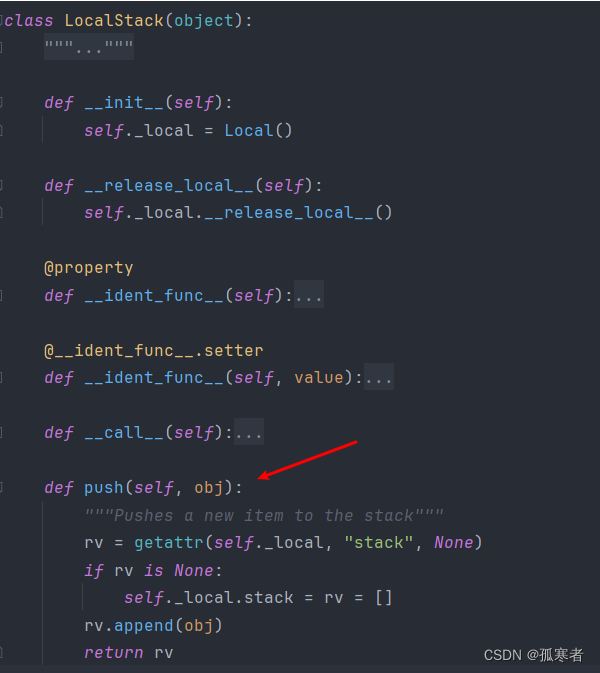
回退两层:
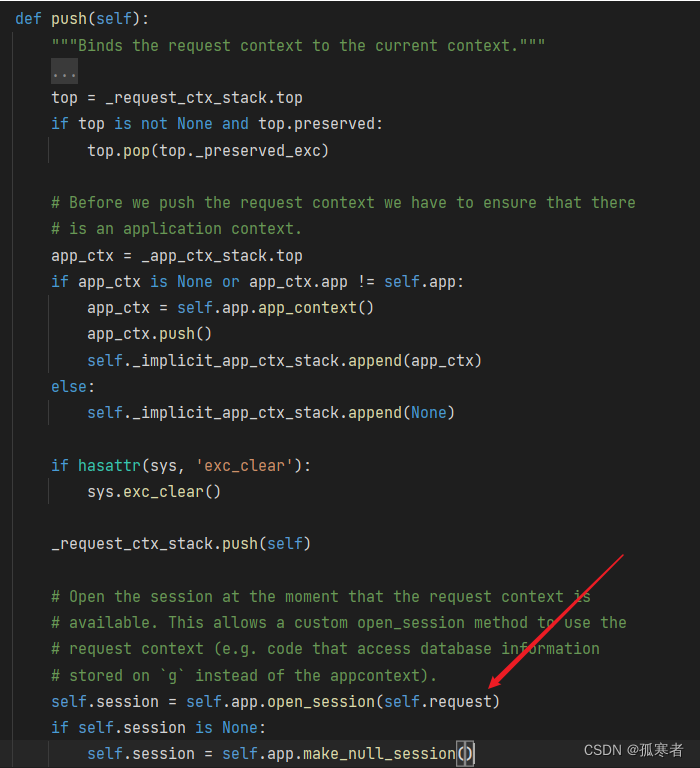
下图箭头所指就是给ctx里的session赋值:
- 下图倒数第三行调用了应用对象(通常是一个Flask应用实例)的
open_session方法,并传入当前的请求对象self.request。这个方法的目标是从请求中提取会话数据(如果存在的话)并返回一个会话对象。 - 如果
open_session没有返回一个有效的会话对象(例如,当前请求可能是一个全新的请求,没有任何之前的会话数据),那么self.session将为None。在这种情况下,代码会调用make_null_session方法来创建一个新的、空的会话对象。这确保了self.session始终有一个有效的会话对象,无论是从请求中提取的还是新创建的空会话。
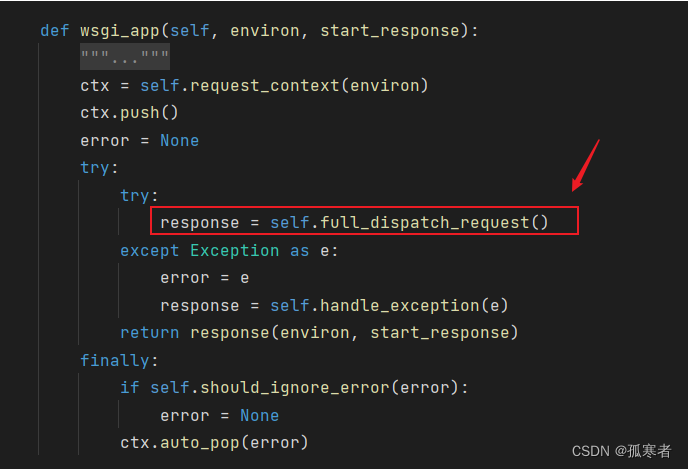
回去继续往下扒:
下图箭头所指就是Flask用于处理一个请求并返回相应响应的核心逻辑:
- 当一个HTTP请求到达Flask应用时,它需要经过一系列的处理步骤,如:预处理(前置处理),路由匹配,视图函数处理,以及后处理(后置处理)等,然后最终得到一个HTTP响应(response)。
full_dispatch_request方法封装了这整个流程。
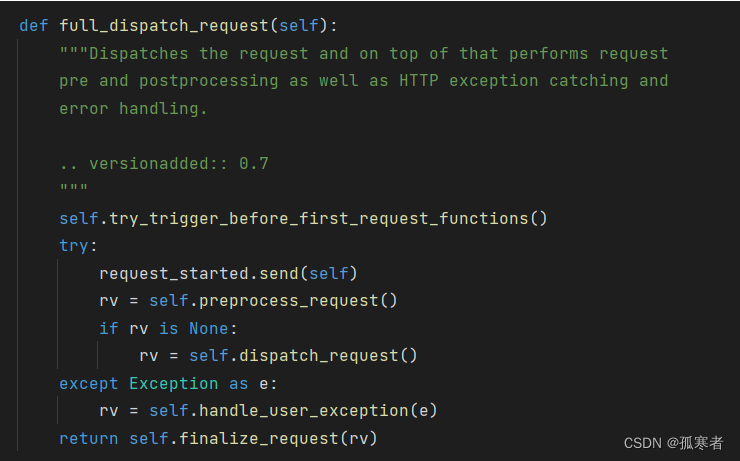
进去:
简单讲一下这个函数各语句功能:
触发首次请求前的函数:
self.try_trigger_before_first_request_functions()这一行尝试触发任何注册为“在第一个请求之前执行”的函数。这些函数只会在应用收到其第一个请求时执行一次,通常用于一些应用的初始化工作。
发送请求开始信号:
request_started.send(self)这一行发送一个
request_started信号。Flask使用信号来允许开发者在某些事件(如请求开始或结束)发生时执行自定义代码。请求预处理:
rv = self.preprocess_request()这一行调用
preprocess_request方法来执行任何注册的请求预处理函数,例如before_request钩子。这些钩子可以用于各种目的,如用户身份验证、设置数据库连接等。请求分发:
if rv is None:rv = self.dispatch_request()如果预处理函数没有返回任何值(即返回
None),则该代码调用dispatch_request方法。dispatch_request方法的职责是根据当前请求的URL找到对应的路由和视图函数,并执行它。请求后处理:
return self.finalize_request(rv)最后,无论请求处理过程中是否发生异常,
finalize_request方法都会被调用。它负责执行任何注册的请求后处理函数(例如after_request钩子)并返回最终的HTTP响应。综上所述,
full_dispatch_request方法封装了Flask处理HTTP请求的整个流程,包括前后处理、路由分发、异常处理和最终响应的创建。
先进去preprocess_request()函数:
【可以看到确实在执行所有注册的请求预处理函数,例如before_request钩子】
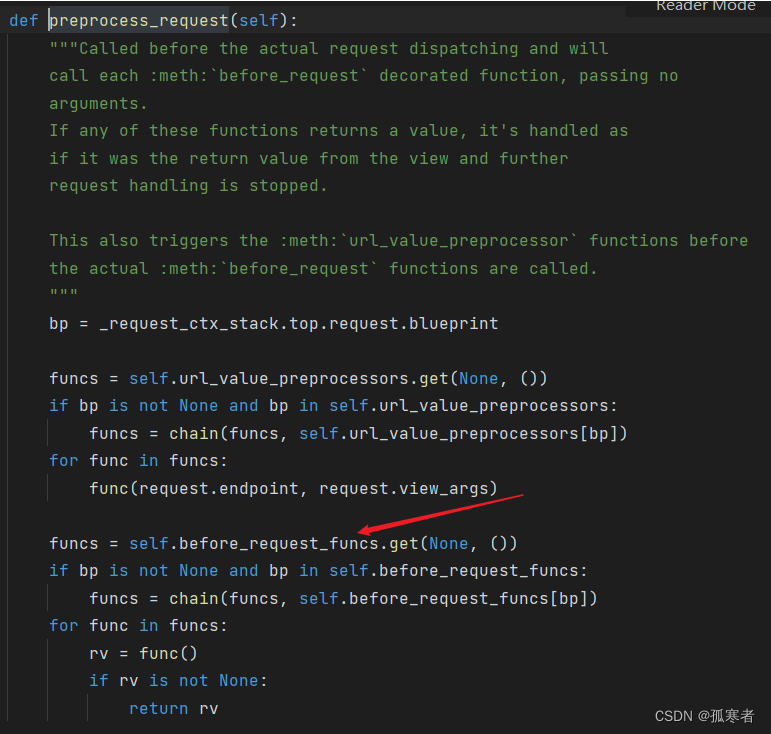
回去一层,进去finalize_request()函数:
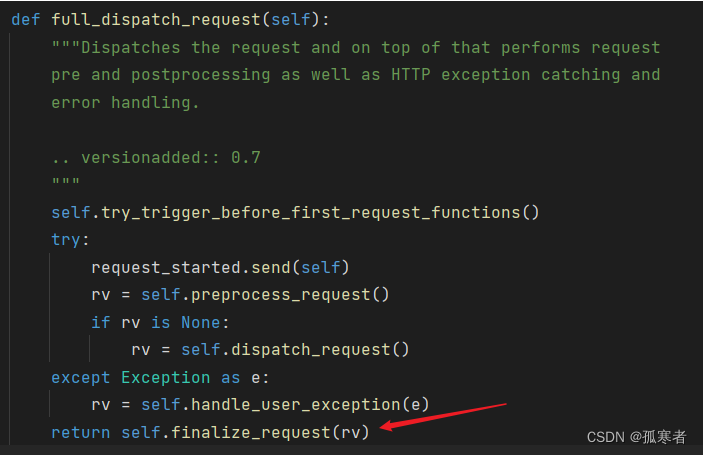
继续进去:
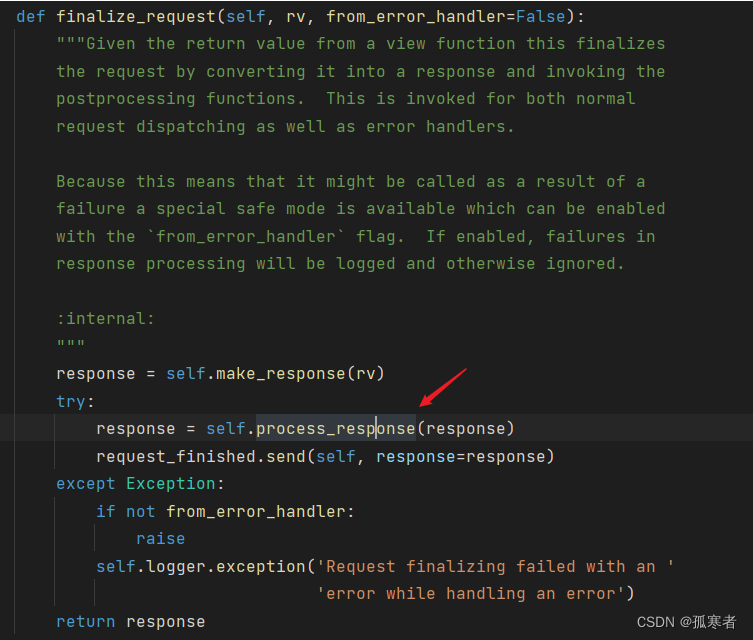
继续进去:
重要部分:
self.session_interface是Flask应用中用于处理会话的接口。is_null_session方法检查给定的会话(在这里是ctx.session)是否是一个空会话。如果不是一个空会话(也就是说,会话中包含了一些数据),那么条件判断为真。- 当条件判断为真时,
save_session方法将当前的会话数据(ctx.session)保存到响应中(response)。这通常涉及将会话数据加密并设置为一个Cookie,然后将该Cookie附加到HTTP响应中。这样,当浏览器接收到这个响应时,它会保存这个Cookie,并在后续的请求中将其发送回服务器。这使得服务器能够识别并“记住”用户之间的连续请求。
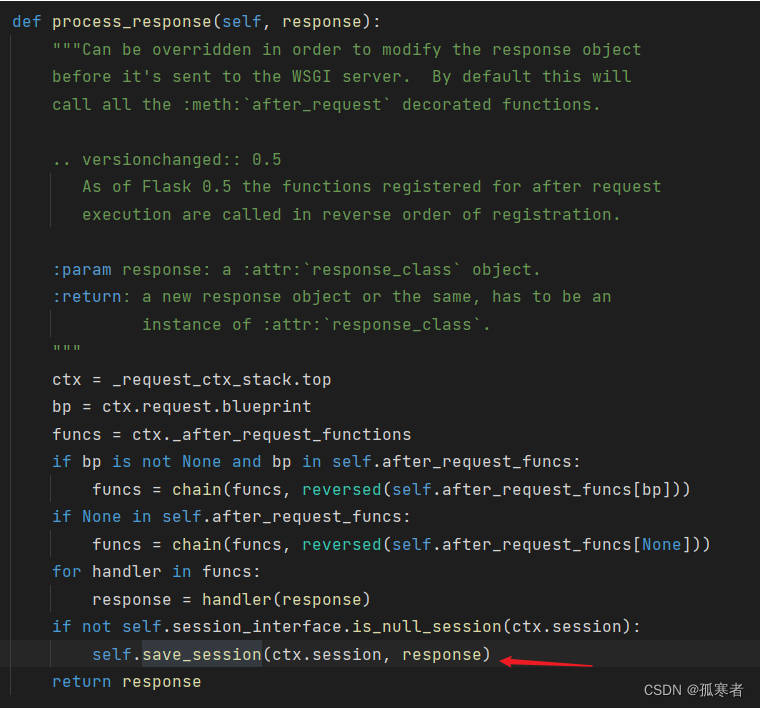
回到最开始:
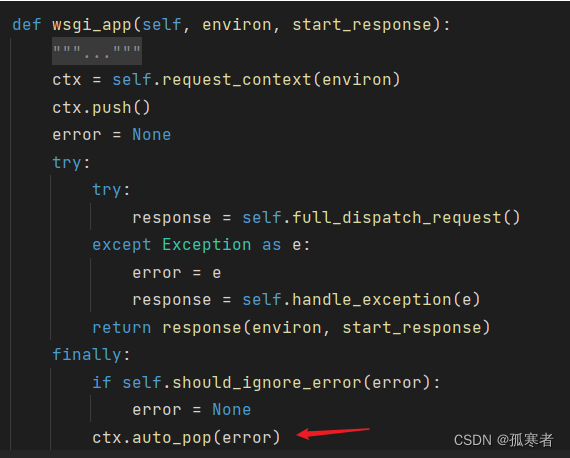
继续进去:
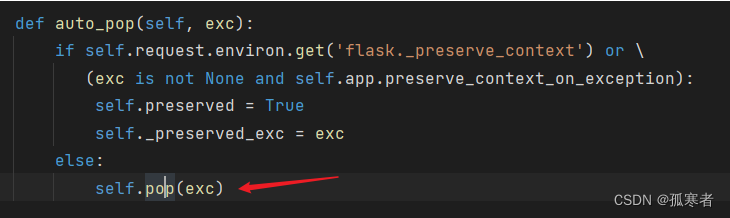
继续进去:
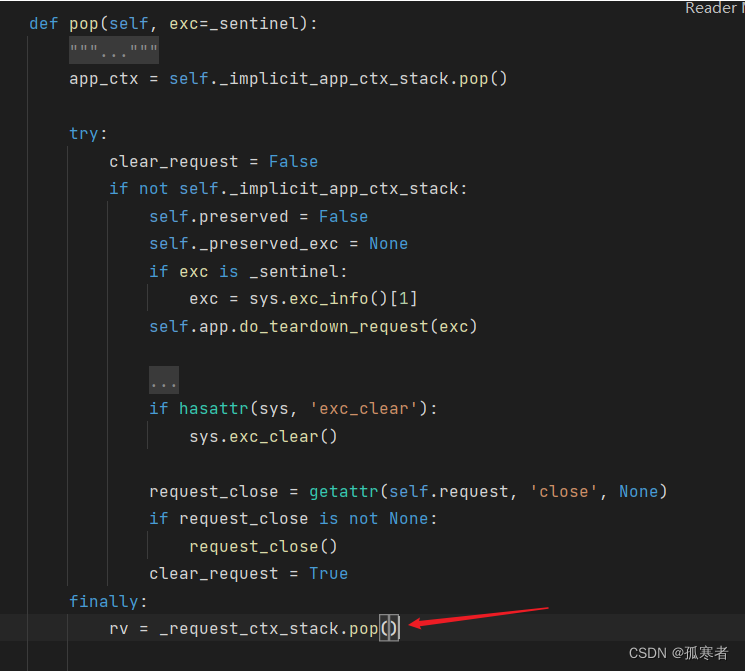
看看_request_ctx_stack对象是啥呢?
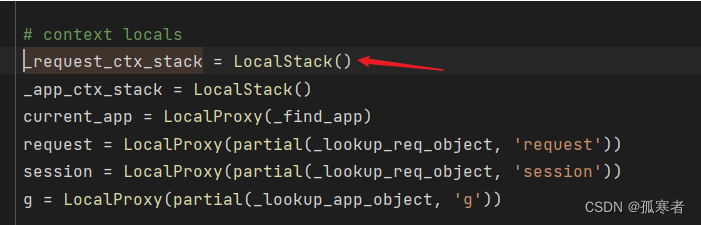
进去:
【threading.local()对象???:是的!】
文末扯几句:
本文较为粗糙地捋了一遍Flask最为核心部分(上下文管理)的源码!
粗糙是粗糙,但味道没有错,仔细扣扣源码~
后续几篇文章会继续细化这部分!
这篇关于(二十)Flask之上下文管理第一篇(粗糙缕一遍源码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








