本文主要是介绍冻结Prompt微调LM: T5 PET (a),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
T5
paper: 2019.10 Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Task: Everything
Prompt: 前缀式人工prompt
Model: Encoder-Decoder
Take Away: 加入前缀Prompt,所有NLP任务都可以转化为文本生成任务
T5论文的初衷如标题所言,是为了全面公平的对比不同预训练和迁移策略的贡献和效果,避免在A模型上效果不好的预训练目标在B上可能效果更优的情况,对比项包括
-
预训练目标:语言模型,乱序还原,MLM(不同的掩码率),Span掩码, etc
-
预训练数据:构建C4数据集,从C4抽取不同领域语料来训练
-
模型架构: Encoder-Decoder,Decoder Only,Encoder Only
-
迁移策略:逐步解冻,全量微调,局部微调
-
其他:多任务预训练,模型大小
说句题外话,再看论文结果发现Encoder-Decoder的模型结果+SpanMLM损失函数效果最好。不知道这是否是谷歌押注T5,而没有像OpenAI一样选择Deocder结构的原因。
具体对比结果这里不细说,本文只关注T5为了公平对比以上差异,提出的Text2Text的通用建模框架:用相同的模型,相同的预训练,相同的损失函数和解码方式,把文本分类,摘要,翻译,QA都转化成了生成任务,而转化的方式就是通过加入前缀prompt。
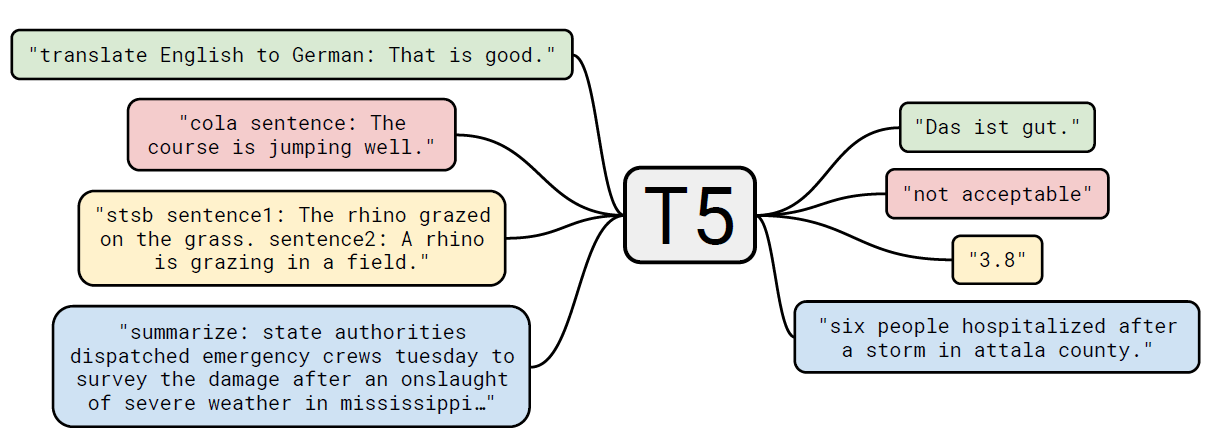
针对不同的下游微调任务,我们看下T5提出的Text2Text是如何构建prompt模板的
-
WMT英语到德语的翻译任务,输入是'translate English to German:'+input, 输出是翻译结果
-
CNN Mail摘要任务: 文本摘要任务,输入是‘Summarize:'+input,输出是摘要
-
MNLI任务:输入是'mnli hypothesis:'+假设+'premise:'+叙述,输出是contradiction, entailment,neutral
-
STS文本相似任务:输入是'stsb sentence1:'+input1+‘sentence2:’+input2, 输出是1~5的打分(离散化)
-
问答SQuAD任务:输入是'question:'+提问+ 'context:'+上下文,输出是答案
不难发现在T5的时代,prompt模板的构建还比较粗糙,更多是单纯的任务名称+任务类型来区分不同的NLP任务,只是让模型在解码时多一层条件概率,既给定不同prompt前缀在解码时采用不同的条件概率(attention)。并没有太多从语义和上下文关联的角度去进行prompt模板的构建,我猜这是T5在论文中提到他们尝试了不同的prompt模板发现效果影响有限的原因(哈哈因为都不太好所以没啥差异),不不能否定T5在通用LM上做出的贡献~
PET-TC(a)
paper a: 2020.1 Exploiting Cloze Questions for Few Shot Text Classification and Natural
prompt: 单字完形填空式人工Prompt
Task: Text Classification
Model: Roberta-large, XLM-R
Take Away: 加入完形填空式Prompt把文本分类任务转化成单字MLM
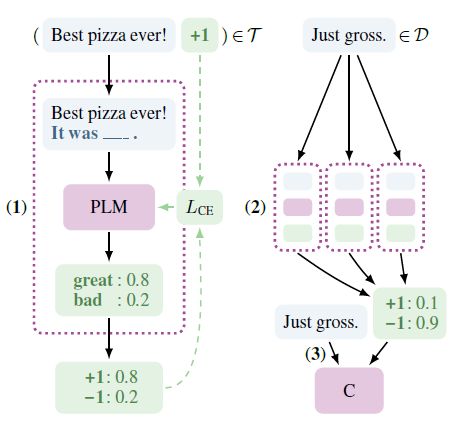
和第一章的LAMA相似,PET-TC也是把输入映射成完形填空式的prompt模板,对掩码词进行预测作为分类标签。不过PET没有直接使用prompt,而是用了半监督的方案。用多个prompt模板微调模型后,对大规模无监督数据进行预测,然后在伪标签上进行常规的模型微调,哈哈绕了一个圈最后还是输出的常规微调的模型。我大胆猜测作者很看好prompt范式在微调时引入的前置语义信息,以及无额外参数的设定,但是对不同prompt和answer模板带来的不稳定性感到头疼,于是搞出这么个折中的方法~
prompt & Answer Engineer
PET针对每个数据集人工设计了prompt模板和Answer词对标签的映射。针对单双文本输入分别举两个例子,以下a,b为原始输入文本,'_'位置为MASK词
-
单输入:Yelp评论1~5星打分,标签词分别为terrible, bad,okay,good,great
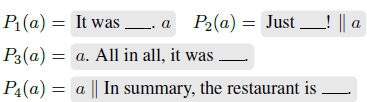
-
双输入:AG's News新闻四分类问题, 标签词分别为分类名称Worlds,Sports, Business, Science/Tech,
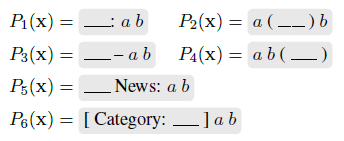
可以看出作者构建prompt模板的思路是尽可能还原文本所在的上下文场景,Answer词的选取是一对一的构建模式,每个label只选取一个词来表示。
固定prompt微调LM
完形填空式的prompt模板在微调时的优势,我认为主要有以下三点
-
没有额外参数的引入,常规微调需要引入hidden_size * label_size的额外参数(classify head)作为每个标签对应的空间表征,这部分需要针对下游任务重头学习。而完形填空的token是在原始vocab中的,于是只需要调整标签词的预训练表征让它在label上线性可分即可
-
前置语义信息的引入,因为标签词的选取本身符合label的原始语义,例如以上YELP评论打分中的5个形容词本身就是隐含了评论质量信息的,所以会引入部分前置信息,避免重头学习,这一点和MRC有些相似
-
预训练和微调的一致性高,都是解决完形填空问题,学习目标一致
微调的损失函数是交叉熵,作者没有引入额外参数,而是把MASK位置上模型的预估logits在label上归一化来得到分类预测。例如上面的AG新闻分类任务,先得到MASK位置worlds,sports,business,science这四个词的预测logits,然后归一化得到预估概率,再和分类标签计算交叉熵。
为了避免灾难遗忘作者在下游任务微调时加入了预训练的MLM任务,于是微调的损失函数如下
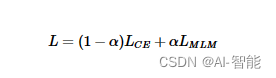
半监督+蒸馏
这部分的设计可以和prompt的部分分开来看,是一个半监督方案。以上每个任务对应的多个prompt模板,分别固定prompt微调LM得到一版模型,然后在大量的未标注样本上进行预测,再对多个模型的预测值进行加权得到伪标签。
最终在为标签上使用常规的微调方案(加classifier head),训练模型作为输出,这一步类比知识蒸馏。所以PET最后输出的还是常规的监督微调模型,Prompt只是被当做了一种半监督方案。效果上在小样本的设定上比直接使用监督微调都有一定的效果提升。
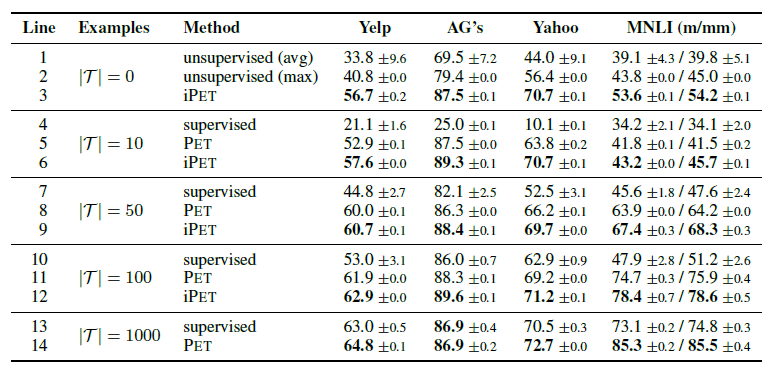
作者还做了iPET对以上过程通过迭代逐步扩大数据集,提高伪标签准确率的方案,不过这么麻烦的实现一点都不适合我这种懒人,哈哈就不细说了~
针对PET有几点疑问
-
完形填空类的prompt,在微调过程中可能的灾难遗忘,是否因为对label词的微调偏离了词在原始文本中语义表征,以及和其他词的相对位置
-
prompt模板差异带来的效果差异尚未解决,人工构建的prompt模板不一定是最优的
-
Answer词单token,以及和label一一对应的设定,限制性较强。这部分在后面的续作里作者做了改良
后面介绍的几个模型,大多是基于PET上述问题的改良~
这篇关于冻结Prompt微调LM: T5 PET (a)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







