本文主要是介绍ResNeXt网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文:Aggregated Residual Transformations for Deep Neural Networks
论文链接:link.
PyTorch代码:
link.
这是一篇发表在2017CVPR上的论文,介绍了ResNet网络的升级版:ResNeXt。下面介绍我看这篇论文时候做的笔记,和大家一起分享该模型。
作者提出 ResNeXt 的主要原因在于:传统的要提高模型的准确率,都是加深或加宽网络,但是随着超参数数量的增加(比如channels数,filter size等等),网络设计的难度和计算开销也会增加。因此本文提出的 ResNeXt 结构可以在不增加参数复杂度的前提下提高准确率,同时还减少了超参数的数量(得益于子模块的拓扑结构一样,后面会讲)。
作者在论文中首先提到VGG,VGG主要采用堆叠网络来实现,之前的 ResNet 也借用了这样的思想。然后提到 Inception 系列网络,简单讲就是 split-transform-merge 的策略,但是 Inception 系列网络有个问题:网络的超参数设定的针对性比较强,当应用在别的数据集上时需要修改许多参数,因此可扩展性一般。
于是重点来了,作者在这篇论文中提出网络 ResNeXt,同时采用 VGG 堆叠的思想和 Inception 的 split-transform-merge 思想,但是可扩展性比较强,可以认为是在增加准确率的同时基本不改变或降低模型的复杂度。这里提到一个名词cardinality,原文的解释是the size of the set of transformations,如下图 Fig1 右边是 cardinality=32 的样子,这里注意每个被聚合的拓扑结构都是一样的(这也是和 Inception 的差别,减轻设计负担)

附上原文比较核心的一句话,点明了增加 cardinality 比增加深度和宽度更有效,这句话的实验结果在后面有展示:

当然还有一些数据证明 ResNeXt 网络的优越性,例如原文中的这句话:In particular, a 101-layer ResNeXt is able to achieve better accuracy than ResNet-200 but has only 50% complexity.
Table1 列举了 ResNet-50 和 ResNeXt-50 的内部结构,另外最后两行说明二者之间的参数复杂度差别不大。

接下来作者要开始讲本文提出的新的 block,
举全连接层(Inner product)的例子来讲,我们知道全连接层的就是以下这个公式:
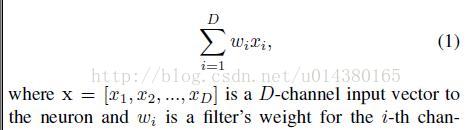
再配上这个图就更容易理解其splitting,transforming和aggregating的过程。
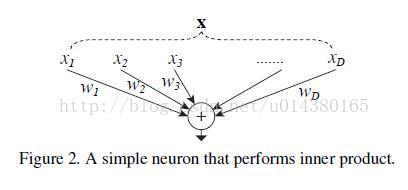
然后作者的网络其实就是将其中的 wi x i
替换成更一般的函数,这里用了一个很形象的词:Network in Neuron,式子如下:
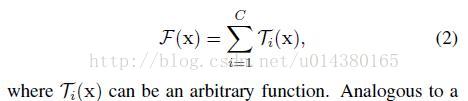
其中C就是 cardinality,Ti有相同的拓扑结构(本文中就是三个卷积层的堆叠)。
然后看看fig 3。这里作者展示了三种相同的 ResNeXt blocks。fig3.a 就是前面所说的aggregated residual transformations。 fig3.b 则采用两层卷积后 concatenate,再卷积,有点类似 Inception-ResNet,只不过这里的 paths 都是相同的拓扑结构。fig 3.c采用的是grouped convolutions,这个 group 参数就是 caffe 的 convolusion 层的 group 参数,用来限制本层卷积核和输入 channels 的卷积,最早应该是 AlexNet 上使用,可以减少计算量。这里 fig 3.c 采用32个 group,每个 group 的输入输出 channels 都是4,最后把channels合并。这张图的 fig3.c 和 fig1 的左边图很像,差别在于fig3.c的中间 filter 数量(此处为128,而fig 1中为64)更多。作者在文中明确说明这三种结构是严格等价的,并且用这三个结构做出来的结果一模一样,在本文中展示的是 fig3.c 的结果,因为 fig3.c 的结构比较简洁而且速度更快。

这个表2主要列举了一些参数,来说明 fig1 的左右两个结构的参数复杂度差不多。第二行的d表示每个path的中间channels数量,最后一行则表示整个block的宽度,是第一行C和第二行d的乘积。

在实验中作者说明ResNeXt和ResNet-50/101的区别仅仅在于其中的block,其他都不变。贴一下作者的实验结果:相同层数的ResNet和ResNeXt的对比:(32*4d表示32个paths,每个path的宽度为4,如fig3)。实验结果表明ResNeXt和ResNet的参数复杂度差不多,但是其训练误差和测试误差都降低了。

另一个实验结果的表格,主要说明增加Cardinality和增加深度或宽度的区别,增加宽度就是简单地增加filter channels。第一个是基准模型,增加深度和宽度的分别是第三和第四个,可以看到误差分别降低了0.3%和0.7%。但是第五个加倍了Cardinality,则降低了1.3%,第六个Cardinality加到64,则降低了1.6%。显然增加Cardianlity比增加深度或宽度更有效。

接下来这个表一方面证明了residual connection的有效性,也证明了aggregated transformations的有效性,控制变量的证明方式,比较好理解。

因此全文看下来,作者的核心创新点就在于提出了 aggregrated transformations,用一种平行堆叠相同拓扑结构的blocks代替原来 ResNet 的三层卷积的block,在不明显增加参数量级的情况下提升了模型的准确率,同时由于拓扑结构相同,超参数也减少了,便于模型移植。另外该算法目前只有Torch版本。
这篇关于ResNeXt网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








