本文主要是介绍非因解读 | 基于RPPA靶向蛋白组学的CellBox模型在癌症联合治疗中的应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于RPPA靶向蛋白组学的CellBox模型在癌症联合治疗中的应用
由于肿瘤细胞在治疗环境变化和疾病进程产生的耐药性和多克隆抗性,使传统的单一药物治疗已不能满足肿瘤研究的现状,而由于样本和实验条件的限制,配对样本或者大队列实验的开展、通过探索性实验的结果来确定潜在治疗靶点等方式都具有挑战性,因此通过计算模型的方法对靶向组合进行预测,已成为研究靶向组合治疗的方法之一。
在计算模型中,如何更大规模的找到潜在的、可以组合起来对某些关键通路、机制起到重要作用的靶点,是靶向组合治疗的关键。非因RPPA靶向蛋白组学技术作为一种有别于常规蛋白组学的检测方法,可实现上千例样本的几百种靶点平行比对,能够为用药组合研究以及生物标志物探索和验证提供完美的解决方案。
哈佛大学cBio中心主任、蛋白结构和蛋白定量生物学专家Chris Sander的团队通过机器学习算法构建了基于RPPA靶向蛋白组学的CellBox模型,来实现靶向药物组合效果和功能预测,并对其准确性进行评估。Chris Sander团队于2021年2月在《Cell Systems》上发表题为“CellBox: Interpretable Machine Learning for Perturbatio Biology with Application to the Design of Cancer Combination Therapy”的文章(图1)。

图1
基于机器学习算法的CellBox模型优点:高精准度、抗噪性能优异、可预测上靶向药物下游蛋白水平变化、提供更多的未知药物组合。同时,该方法有着很强的拓展延伸效能,可以针对不同的扰动进行设计,来实现在不同的细胞模型效应下,更准确地发掘最佳的药物及药物组合疗法,为靶向药物拓展和耐药机理挖掘提供一个高效的验证平台。
考虑到不同细胞系在药物靶点间的表达差异,CellBox模型的构建需要针对某一个细胞系的生物学系统作为背景,同时获得多条件处理下的多样本蛋白质表达水平和细胞表型变化的配对数值,而RPPA技术可以高通量、高精度地提供蛋白质表达水平变化的直接证据,特别适合CellBox模型的训练和预测。
非因生物传承MD安德森的价值和理念,已经开发了一整套包含几百个和磷酸化靶点RPPA蛋白组学分析panel——Cancer Signaling Pano-Profiler。非因RPPA新型蛋白组学技术具有其它高通量蛋白组学所无可比拟的超高灵敏度,可在40微克总蛋白或15毫克组织中(米粒大小)分析>300种中、低丰度蛋白,包括大量药物靶点、细胞信号蛋白、翻译后修饰蛋白(磷酸化,乙酰基化,甲基化)等。RPPA技术在定量能力、重复性、大样本分析比对能力上的优势,是其它蛋白组学技术手段所不具备的。
CellBox模型构建
为构建一个数据驱动的模型,预测经药物联合治疗后分子和细胞行为的动力学特征,扰动数据必须具备以下特征:(1)有一组多因素处理下多样本的蛋白水平和细胞表型变化的配对值;(2)一部分数据用于机器学习并保留剩余数据以检测模型性能。在该项研究中,研究人员利用12种药物及其联合用药处理黑色素瘤细胞SK-Mel-33,测量了89个扰动条件,并用MD安德森RPPA技术平台所产生的药物扰动生物学数据检测了药物处理之前和经药物处理24h之后细胞裂解液中82个蛋白质及其磷酸化水平。同时还测定了细胞周期进展和细胞活力等细胞表型反应谱作为扰动数据集(图2A)。通过测量一组系统的蛋白质组学和表型反应得到的数据构建网络模型,将蛋白变化与细胞表型可以定量联系起来。研究人员利用一组非线性网络常微分方程(ordinary-differential-equation,ODE)来模拟系统对药物扰动的动态反应,并用部分扰动数据进行机器学习(图2B)。
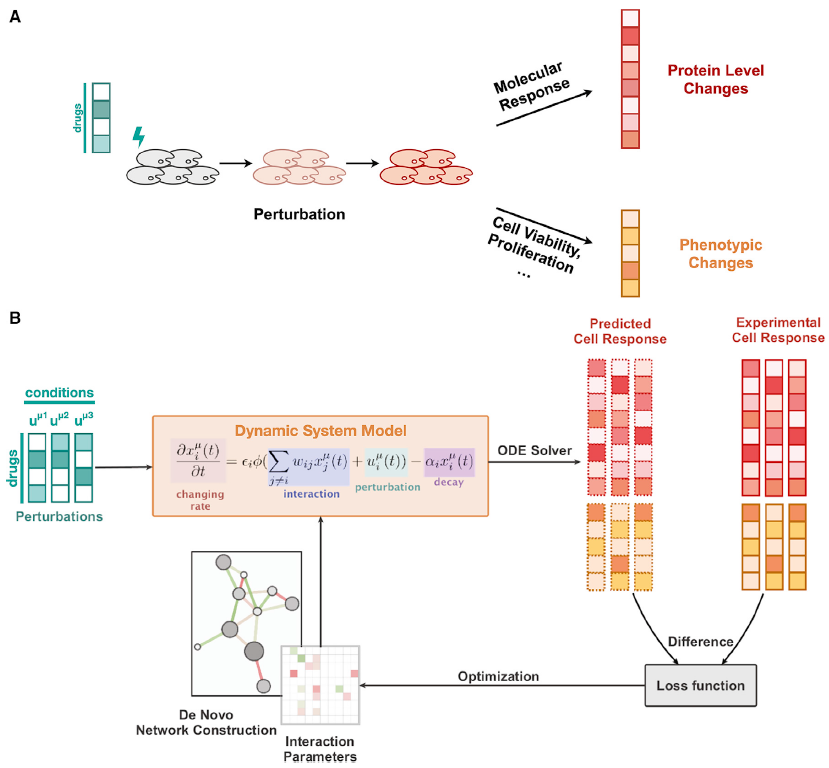
图2
用扰动数据训练CellBox以准确预测细胞反应
研究者随机选择70%的数据进行机器学习,并保留剩余30%数据用于测试机器学习的预测性能。发现ODE模型的数值解可以有效关联到实验数据(图 3A、3B)。为了验证预测的可重复性,用1000个独立随机数据分区重复建模方案,发现所有模型和在不同条件下的平均预测与实验数据显著相关。Pearson’s的相关系数为0.93(图3C)。对单个扰动条件的更精细分析表明,模型在所有条件下的预测都与实验测量结果有很高的相关性(图3D)。这些结果表明,基于ODE数据驱动的CellBox细胞系统模型可以准确预测细胞的动态反应。
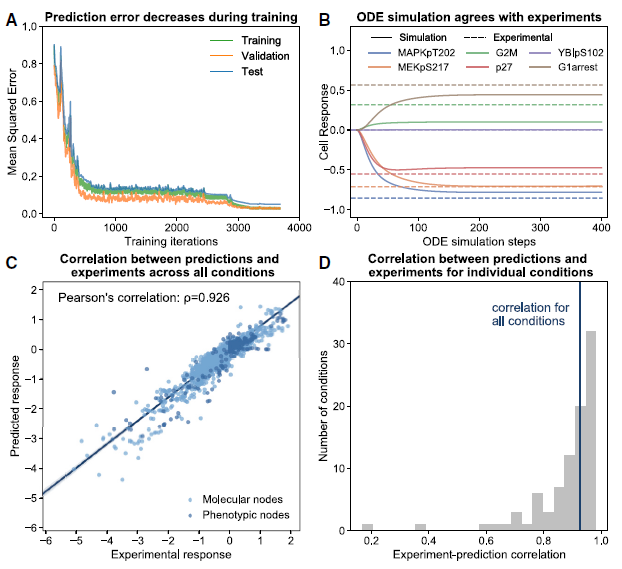
图3
CellBox模型可用于预测单一药物到联合治疗条件下的细胞反应,或用于预测 Leave-One-Drug-Out交叉验证效果。单一药物到联合治疗:将所有单一药物治疗条件下的数据用于机器学习,并对所有联合用药结果进行预测。Leave-One-Drug-Out:保留或去除一种药物的单独或联合治疗的所有条件,其他条件用于机器学习。结果发现,当只使用单个药物条件进行机器学习时,CellBox模型以较高的精度预测联合用药对细胞的影响,并优于使用信念传播算法(belief-propagation,BP)、静态共表达网络模型(Co-exp)和在相同数据上训练的神经网络回归模型(NN) (图4A);当与一种药物相关的组合条件的数据不用于机器学习时,CellBox模型同样以高精度预测未见过的药物组合对细胞的影响(图4B);当一种药物的所有条件下的数据均不用于机器学习时,CellBox以一般精度预测了保留药物对细胞的影响(图4C)。总的来说,CellBox模型对保留数据的预测值与实验观察结果高度相关,而且相比于其他模型更适合对联合用药结果进行准确预测。
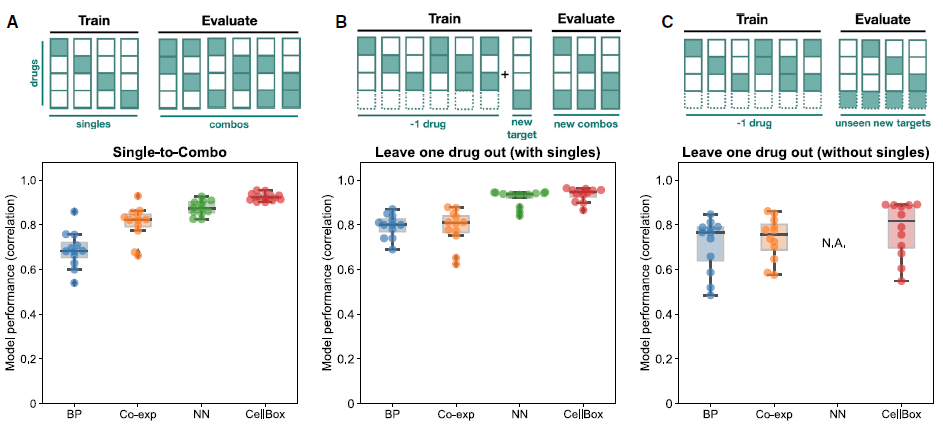
图4
CellBox模型对噪声的稳健性好且需要的训练集更小
为了测试当训练数据的质量或数量受到影响时模型的稳定性,研究人员将训练数据增加了5%乘性高斯噪声,发现其预测结果与原始数据进行训练的预测结果具有类似的相关性(图5A)。随着背景噪声的增加,模型的性能在收敛性和预测能力方面都逐渐降低。加性高斯噪声显示出类似的趋势(图5B)。研究人员认为,在适度的实验误差下,模型的性能是稳定的。这也从另一个侧面说明了RPPA所提供的蛋白组学数据比基因组或转录组更能够直观预测药物效应。
接下来,研究人员研究了不同数量的数据对模型预测的影响(10%-90%,以10%递增),发现用完整数据40%的数据量时就可以对其他数据进行准确预测(图5C)。
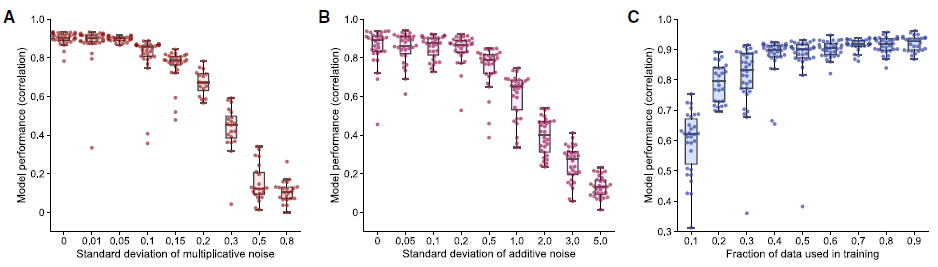
图5
CellBox模型和已知结果的比较
研究人员以药物的主要靶点为基础,研究药物活性节点与其下游效应之间的相互作用,发现所有12个药物活性节点均与其他已知的主要下游蛋白效应具有显著的边际连接,且相互作用方向与预期效应一致(图6),这些表明,模型可以捕捉到文献提供的药物靶点与其下游效应器之间的相互作用。
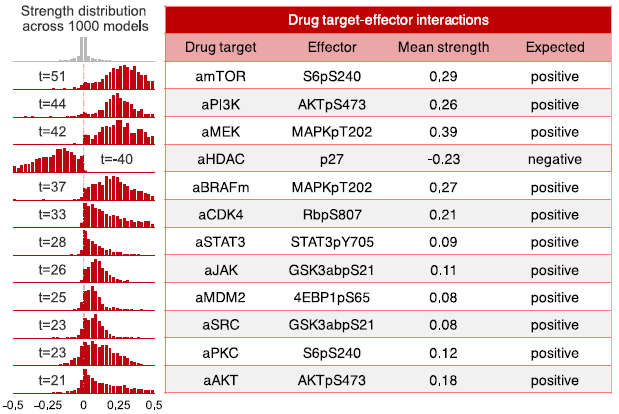
图6
CellBox模型可用于特定药物联合作用下未知效应的预测
用1000个完整模型的模拟来定量预测扰动中约11万个动态反应,对于网络模型中每个蛋白或磷酸化蛋白节点,CellBox模型可以模拟不同剂量的单独用药或组合用药的抑制,并预测表型变化(图7)。
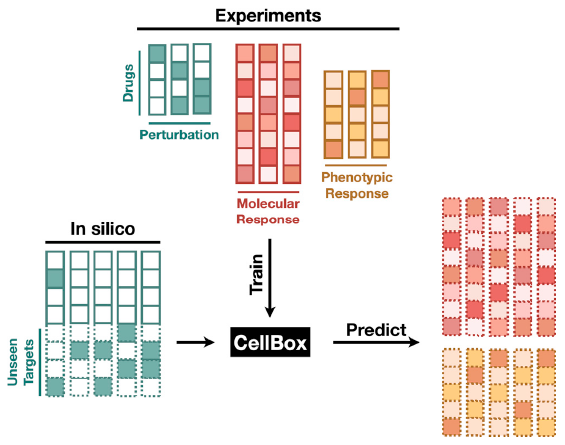
图7
CellBox模型可以预测动态细胞反应,用来设计癌症的靶向组合治疗方案。为了提供具有足够准确性和潜在机制洞察力的预测,研究人员将深度学习中使用的优化算法应用于生物可解释微分方程(ODE)系统。CellBox模型可以有效地训练,并且独立于先验知识,以预测对看不见的扰动的分子和表型反应,并具有较高的准确性。尽管经过相对较小的实验训练,该模型能够模拟细胞对各种任意组合扰动的响应。通过期望的表型结果(如增殖减少)来排序细胞对计算组合扰动的反应,可能会指导特定的治疗方法。
该研究认为CellBox模型可推广到其他类型的系统和更大的系统。一个诱人但具有挑战性的前景是通过遗传扰动结合个体肿瘤背景,提出最佳的、个性化的靶向组合治疗方案。研究人员认为只要有合适的扰动响应数据,CellBox模型可以广泛应用于生物学的其他领域,如发育生物学或合成生物学。未来的关键挑战是针对每种感兴趣的生物环境的实验设计,以及可转移和可扩展的机器学习方法的进一步发展。
展望未来
非因生物RPPA新型蛋白组学技术研发实验室自建设以来,已经和清华大学、复旦大学附属肿瘤医院、中山大学孙逸仙纪念医院、四川大学华西医院、山东大学齐鲁医院等几十家国内知名机构建立长期合作关系,并提供优质的技术服务,协助合作机构完成了大量的科研工作。
非因生物一直致力于通过生物信息学结合机器学习的方法开发In-silico靶向药物平台,从一个全新的角度支持到如火如荼的药物靶向治疗和组合的开发,加速药物转化进程。非因生物正在运用RPPA以及肿瘤细胞库的强大优势,搭建基于CellBox靶向药物组合的人工智能平台PReDICT(Proteomic Resolver for Drug Interaction and Combinational Therapy),在不远的将来将会为药物开发提供完美解的决方案。
这篇关于非因解读 | 基于RPPA靶向蛋白组学的CellBox模型在癌症联合治疗中的应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






