本文主要是介绍Pyhton基础知识:整理18 -> 基于面向对象的知识完成数据分析的案例开发,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据准备:两份数据,一份是是字符串的形式,一份是json格式,之后对数据处理后,需要合并为一份的数据,进而进行图表的开发
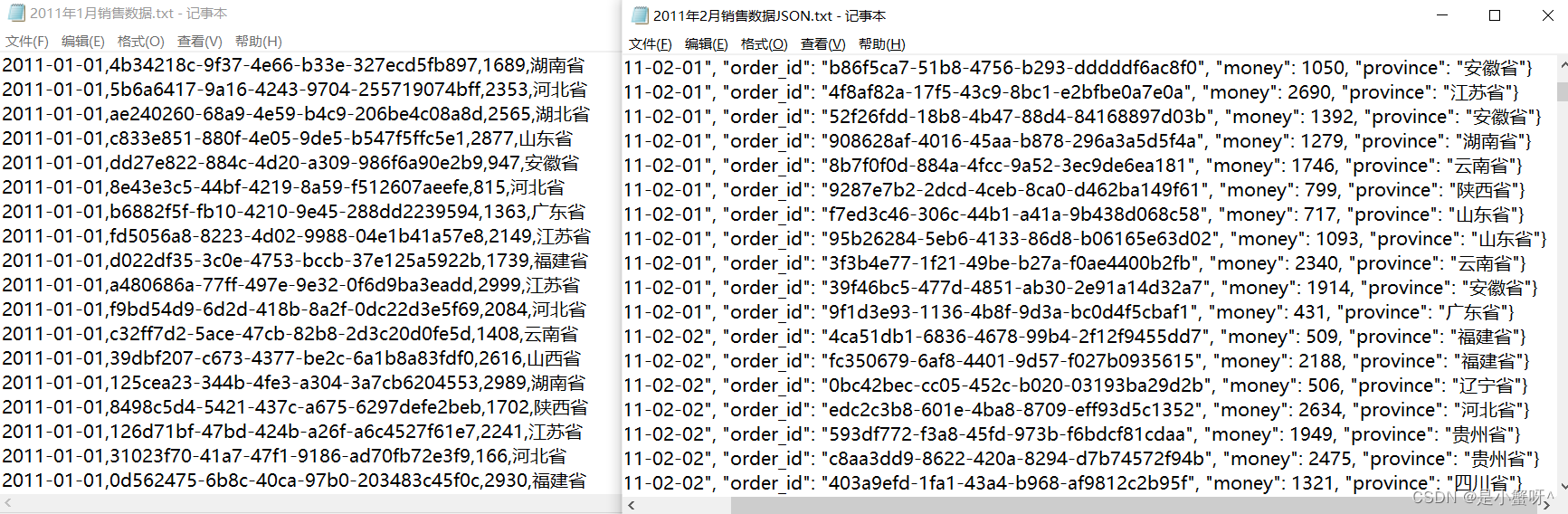
1 设计一个类,完成对数据的封装
"""数据定义的类
"""
class Record:date = None # 订单日期order_id = None # 订单idmoney = None # 订单金额province = None # 销售地区def __init__(self, date, order_id, money, province):self.date = dateself.order_id = order_idself.money = moneyself.province = provincedef __str__(self):return f"date: {self.date}, order_id: {self.order_id}, money: {self.money}, province: {self.province}"2 设计一个抽象类,定义文件读取的相关功能,并使用子类实现具体的功能
"""
和文件相关的类定义
"""from data_defined import Record
import json# 先定义一个抽象类来做顶层设计,确定有哪些功能需要实现
class FileReader:def read_data(self):"""读取文件的数据,读到的每一条数据都转换为Record对象,将它们都封装到list内,返回即可"""pass# 子类1
class TextFileReader(FileReader):def __init__(self, path):self.path = path # 定义成员变量,记录文件的路径# 复写父类的方法(实现抽象方法)def read_data(self):"""读取文本文件的数据"""fr1 = open(self.path, 'r', encoding="UTF-8")lines = fr1.readlines()fr1.close()record_list: list[Record] = []for line in lines:line = line.strip("\n") # 去掉换行符data_ls = line.split(",")# print(data_ls)record = Record(data_ls[0], data_ls[1], int(data_ls[2]), data_ls[3])record_list.append(record)return record_list# 子类2
class JsonFileReader(FileReader):def __init__(self, path):self.path = path # 定义成员变量,记录文件的路径# 复写父类的方法(实现抽象方法)def read_data(self):"""读取json文件的数据"""fr2 = open(self.path, "r", encoding="UTF-8")lines = fr2.readlines()fr2.close()record_list: list[Record] = []for line in lines:data_dict = json.loads(line)record = Record(data_dict["date"], data_dict["order_id"], int(data_dict["money"]), data_dict["province"])record_list.append(record)return record_list3 数据处理
from file_defined import FileReader, TextFileReader, JsonFileReader
from data_defined import Recordtext_file_reader = TextFileReader("D:/PyCharm_projects/python_study_projects/text/2011年1月销售数据.txt")
data1 = text_file_reader.read_data()json_file_reader = JsonFileReader("D:/PyCharm_projects/python_study_projects/text/2011年2月销售数据JSON.txt")
data2 = json_file_reader.read_data()
# print(type(data2)) # list
print(data2)# 将2个月份的数据合并为1个list
all_data = data1 + data2data_dict = {} # 定义一个空字典for record in all_data:if record.date in data_dict.keys():# 已存在,需要累加data_dict[record.date] += record.moneyelse:data_dict[record.date] = record.money
print(data_dict)
4 可视化图表开发
from pyecharts.charts import Bar
from pyecharts.options import *
from pyecharts.globals import ThemeType# 可视化图表开发
bar = Bar(init_opts=InitOpts(theme=ThemeType.LIGHT)) # 设置主题bar.add_xaxis(list(data_dict.keys())) # 添加 x 轴的数据
bar.add_yaxis("销售额", list(data_dict.values()), label_opts=LabelOpts(is_show=False)) # 添加 y 轴的数据, is_show=False表示不展示数据bar.set_global_opts(title_opts=TitleOpts(title="2011年1月-2月销售数据", pos_left="center", pos_top="5%")
)bar.render("D:/PyCharm_projects/python_study_projects/modules/bar_sale_chart.html")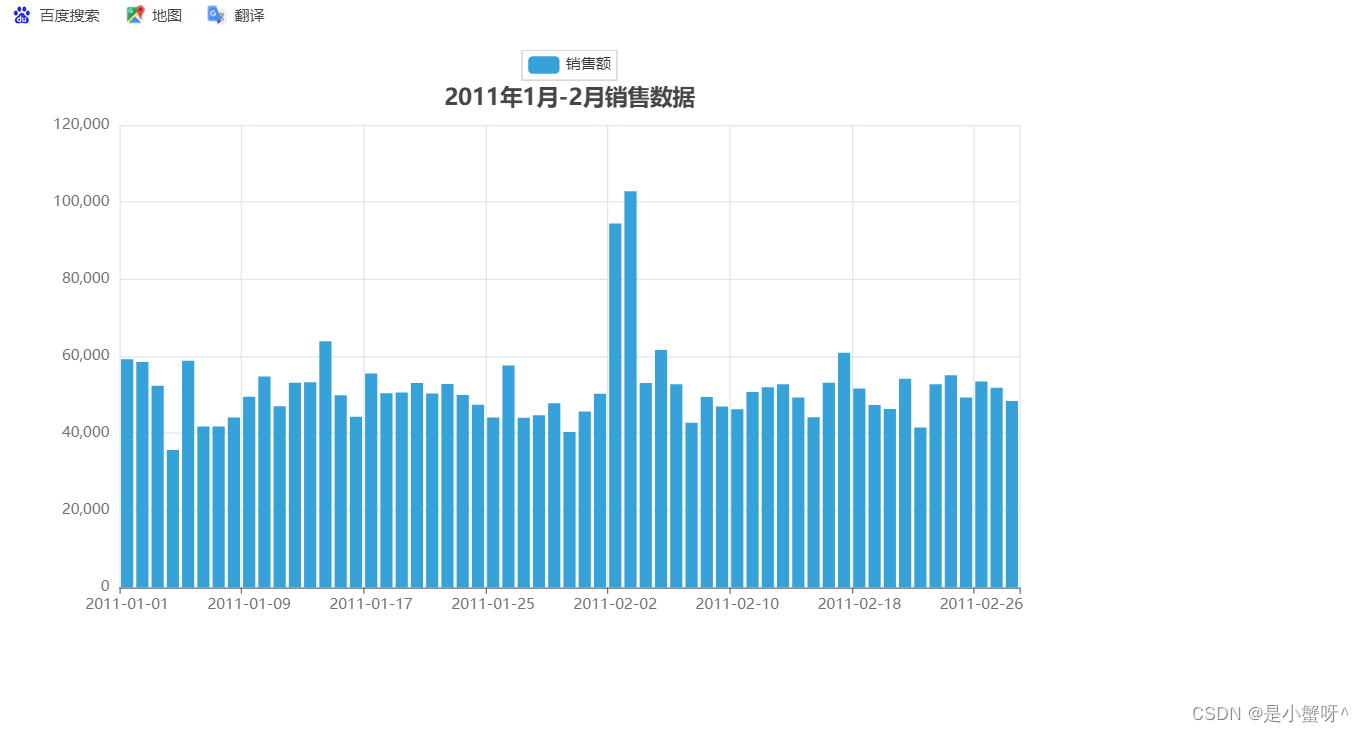
这篇关于Pyhton基础知识:整理18 -> 基于面向对象的知识完成数据分析的案例开发的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







