本文主要是介绍Python简易爬虫,爬取斗鱼颜值美女!!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
代码简单用作初学Python,只要运行脚本图片自动下载根据,斗鱼网页更新而更新!!
QQ学习交流群127591054
JackChiang
Python版本3.5
<1>版本1,效果如图片,存在问题不能给图片加自己的名字,代码不够灵活。版本2解决这个问题
#coding=utf-8
#爬取斗鱼颜值妹子图片
import re
import urllib
import time#定义为方法
def getHTML(url):page = urllib.urlopen(url)html=page.read()return html#开始根据链接爬图片保存数据
def getImage(html):imagelist = re.findall(r'data-original="(.*?\.jpg)"',html);print imagelistx=0for imageone in imagelist:print('开始下载:%s'%imageone)urllib.urlretrieve(imageone,'C:\\Users\\JackChiang\\Pictures\\PythonData\\%d.jpg'%x)x+=1time.sleep(0.5)
fileimg = getHTML('https://www.douyu.com/directory/game/yz')
print fileimg
getImage(fileimg)#斗鱼颜值地址:https://www.douyu.com/directory/game/yz效果图~~~
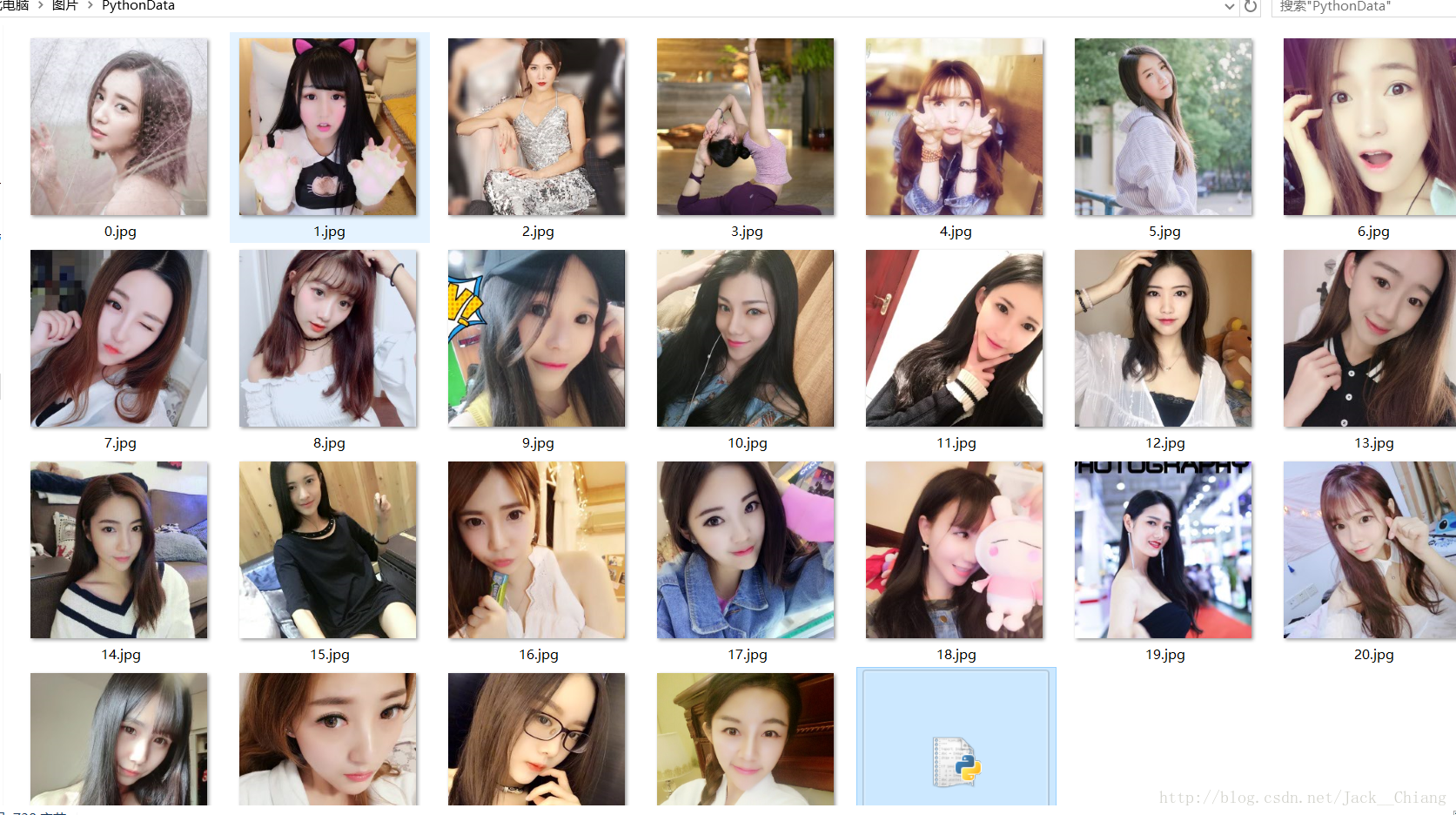
<2>版本2更灵活一些
#coding=utf-8
#爬取斗鱼颜值妹子图片
import re
import urllib.request
import time
from bs4 import BeautifulSoup#定义为方法
def getHTML(url):page = urllib.request.urlopen(url)html=page.read()return html#开始根据链接爬图片保存数据
def getImage(html):#创建对象,传入网页数据soup1 = BeautifulSoup(html)soupL = soup1.select('#live-list-contentbox')print(str(soupL))strone = str(soupL)soup2 = BeautifulSoup(strone)soupLi = soup2.select('li')for soupLione in soupLi:#获取单个li标签获取数据soupone = BeautifulSoup(str(soupLione))name = soupone.a['title']print('开始下载:%s'%name)url = soupone.img['data-original']try:urllib.request.urlretrieve(url,'C:\\Users\\JackChiang\\Pictures\\PythonData\\%s.jpg'%name)print(url)except OSError:print('出现异常,地址为:%s'%url)finally:time.sleep(0.5)fileimg = getHTML('https://www.douyu.com/directory/game/yz')
getImage(fileimg)#斗鱼颜值地址:https://www.douyu.com/directory/game/yz代码运行状态

效果图
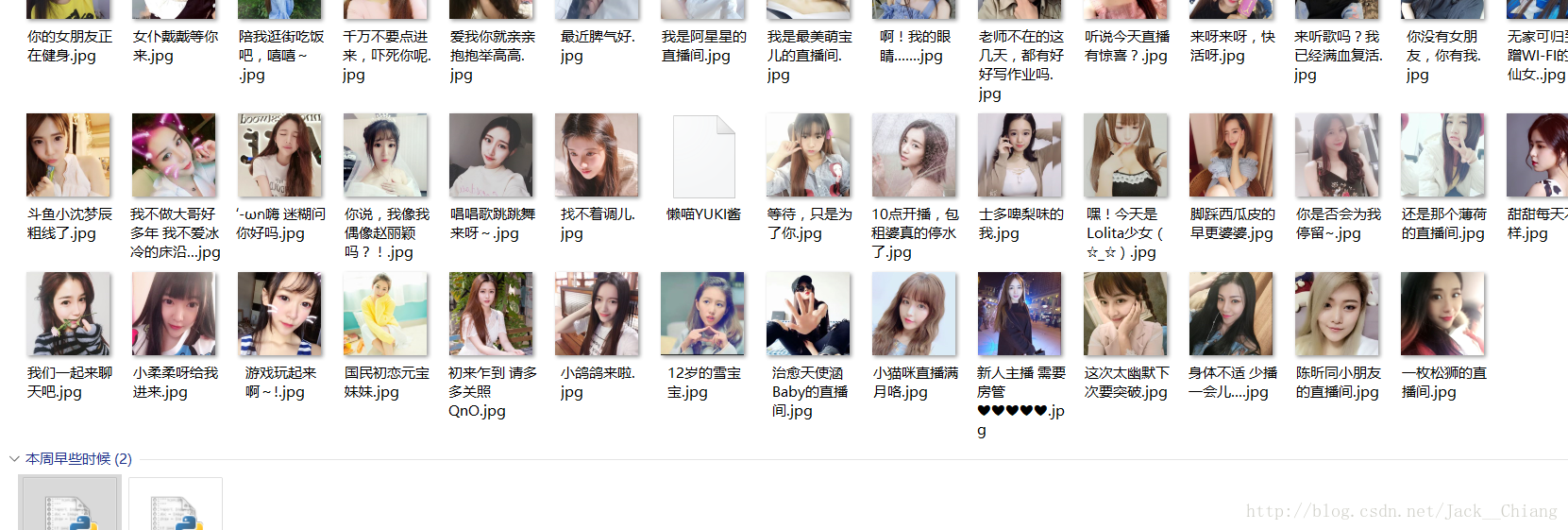
后续版本会有更好效果!!
这篇关于Python简易爬虫,爬取斗鱼颜值美女!!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






