本文主要是介绍语义分割中多尺度特征的配准问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.问题阐述
语义分割的目的是给每一个像素进行正确的分类,这个定义提供了一种从分类视角看待问题的思路,但不能很好的阐述语义分割所面临的关键问题。顾名思义,语义分割是将图像分成若干块,同时获取块的类别,也就是语义信息。这其中有两个关键,一是分割的准确性,保证每个类边缘的准确;二是类别预测的准确性。要准确预测类别,需要利用深层的网络提取语义特征,而随着网络层数的加深,边缘细节不可避免的损失掉了。
很直观的我们可以用边界预测的方式来解决这个问题,也的确有很多论文这么做。但更多的论文是通过融合多尺度特征来保证在获取健壮的语义表示(大尺度)的同时维持细节(小尺度)。因为多尺度还有助于像素分类,毕竟不同的类别可能需要在不同的尺度之下进行探测。图像的多尺度还有一些其他的优势,比如省内存,最近视觉Transformer相关的论文也有相当多的一部分在致力于提取多尺度的特征或者说是恢复成多尺度的结构。
多尺度特征的提取问题暂且不谈,我们重点来讨论一下如何同时利用好不同尺度的特征,也就是如何进行多尺度特征融合。以FPN结构为例,小尺度的图像先经过1*1卷积降维使得大家通道数都一样,然后大尺度的图像经过一个上采样使得大家图像尺寸一样,规模都一样之后就可以相加了。然而真的可以直接相加吗,相加默认了像素之间存在一个一一对应的关系,但这个对应关系是否正确呢?在上采样通常只是双线性插值的情况下,这个对应关系明显存在疏漏。
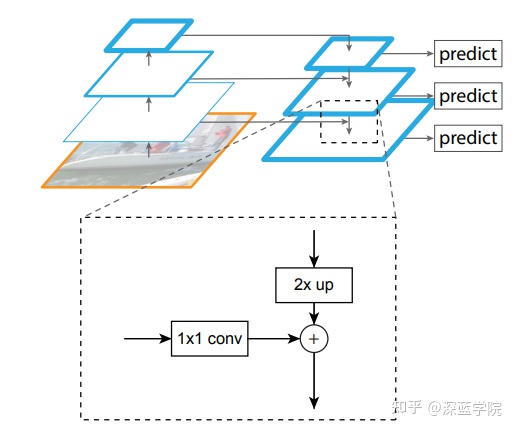
最近刚好看到了两篇论文SFsegNet(ECCV 2020), AlignSeg(TPAMI 2021)都是重点解决的这个问题,在此特地总结一下,包括他们的解决思路以及具体的代码实现。这两篇论文都是认为像素之间一一对应的关系存在误差,需要进行纠正,需要寻找每个像素之间正确的对应关系,也就是为每个像素寻找对应点。这不就是一个配准问题吗?当然不是很严格的一样,但是思路打开了,能否借鉴一下配准领域的知识呢,譬如这两篇论文都是用光流的方式进行配准,去计算每个像素的运动。
·可不可以不对所有像素进行计算,只计算一些关键点?(这样会有收益吗)
·可不可以用其他的方式配准?(光流似乎最好实现)
·不准的原因是什么,是不是这里发生了运动?(肯定不是真实的运动,是什么的运动呢)
不管怎样解决这个问题,这两篇论文至少都证明了语义分割中配准问题是真真实实存在的,以下图来自SFsegNet, 可以很明显的看到不同尺度之间图像“对应”像素之间的语义差别还是蛮大的,估计了光流然后纠正后效果十分明显。

1.AlignSeg: Feature-Aligned Segmentation Networks
论文地址:
https://arxiv.org/abs/2003.00872
代码地址:
https://github.com/speedinghzl/AlignSeg
这里只看配准部分,其他部分有兴趣的可以看看原文。
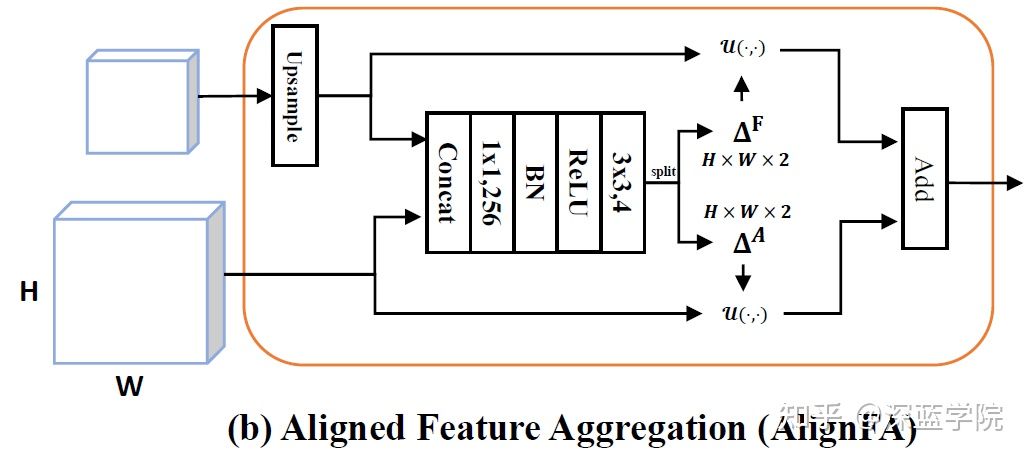
模块组成很直观,先对低分辨率特征上采样,再与高分辨率特征相连,经过1x1卷积降到256,然后BN,激活,经过3x3卷积得到四个通道,其含义就是两个尺度特征的offset map(H x W x 2, 因为有两个方向的偏移,所以乘2)。模块里没有体现的就是那个u函数,也就是如何利用offset map进行纠正,纠正之后把两个尺度的特征相加即可。论文给出的纠正公式如下:(出自Spatial transformer networks,但论文并没有进行引用,我还是看的SFsegNet发现的)

拍脑袋想一下,有了offset map,直接按照偏移量将原像灰度值(为了简便,这样表述)赋给新的像点不就好了吗?为什么要用这个看起来这么复杂的公式。实际上要考虑到偏移不是整数的情况,直接赋值就是最近邻插值,不太精确,论文这个公式就是双线性插值。
点(h,w)经过偏移变成
![]()
, 新像点(h,w)的值由偏移后的点附近(-1,1)范围内的点按距离双线性插值得到。虽然求和范围是全图,但把max以及绝对值展开,就会发现只有在距偏移后的点(-1,1)的方格内的点才对权重有贡献。
来看一下实际的代码实现,发现论文作者并没有按论文里说的一起计算偏移分量,delta_gen还是各自经过卷积得到,作者回复因为两个尺度偏移矩阵的方差不一样,分开计算效果更好。
代码复杂的部分依然是这个双线性插值如何实现,但仔细一看,我发现和下一篇的warp函数基本上完全一样,这里就不介绍了。它的第二个插值函数实际并没有用到...
class CAB(nn.Module):def __init__(self, features):super(CAB, self).__init__()self.delta_gen1 = nn.Sequential(nn.Conv2d(features*2, features,
kernel_size=1, bias=False),InPlaceABNSync(features),nn.Conv2d(features, 2, kernel_size=3,
padding=1, bias=False))self.delta_gen2 = nn.Sequential(nn.Conv2d(features*2, features,
kernel_size=1, bias=False),InPlaceABNSync(features),nn.Conv2d(features, 2, kernel_size=3,
padding=1, bias=False))self.delta_gen1[2].weight.data.zero_()self.delta_gen2[2].weight.data.zero_()def bilinear_interpolate_torch_gridsample(self, input, size,
delta=0):out_h, out_w = sizen, c, h, w = input.shapes = 1.0norm = torch.tensor([[[[h/s,
w/s]]]]).type_as(input).to(input.device)w_list = torch.linspace(-1.0, 1.0, out_h).view(-1,
1).repeat(1, out_w)h_list = torch.linspace(-1.0, 1.0, out_w).repeat(out_h, 1)grid = torch.cat((h_list.unsqueeze(2),
w_list.unsqueeze(2)), 2)grid = grid.repeat(n, 1, 1,
1).type_as(input).to(input.device)grid = grid + delta.permute(0, 2, 3, 1) / normoutput = F.grid_sample(input, grid)return outputdef bilinear_interpolate_torch_gridsample2(self, input, size,
delta=0):out_h, out_w = sizen, c, h, w = input.shapenorm = torch.tensor([[[[1,
1]]]]).type_as(input).to(input.device)delta_clam = torch.clamp(delta.permute(0, 2, 3, 1) / norm,
-1, 1)grid =
torch.stack(torch.meshgrid(torch.linspace(-1,1,out_h),
torch.linspace(-1,1,out_w)), dim=-1).unsqueeze(0)grid = grid.repeat(n, 1, 1,
1).type_as(input).to(input.device)grid = grid.detach() + delta_clamoutput = F.grid_sample(input, grid)return outputdef forward(self, low_stage, high_stage): h, w = low_stage.size(2), low_stage.size(3)high_stage = F.interpolate(input=high_stage, size=(h, w)
mode='bilinear', align_corners=True)concat = torch.cat((low_stage, high_stage), 1)delta1 = self.delta_gen1(concat)delta2 = self.delta_gen2(concat)high_stage =
self.bilinear_interpolate_torch_gridsample(high_stage, (h, w),
delta1)low_stage =
self.bilinear_interpolate_torch_gridsample(low_stage, (h, w),
delta2) high_stage += low_stagereturn high_stage2.Semantic Flow for Fast and Accurate Scene Parsing
论文地址:
https://arxiv.org/abs/2002.10120v3
代码地址:
https://github.com/lxtGH/SFSegNets
同样只看配准部分。
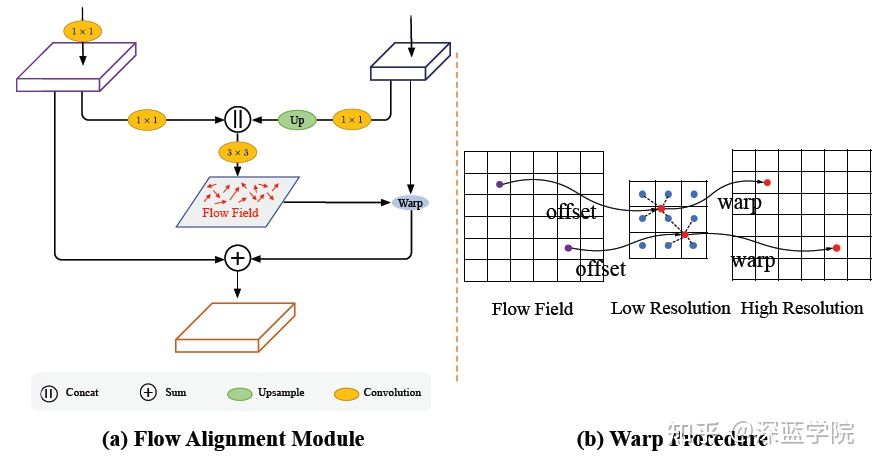
先各自经过一个1*1卷积到指定维数,再对低分辨率上采样,将两个分辨率特征相连,经过3×3卷积降到2维,分别代表x,y方向的offset map,再经过一个warp操作对低分辨率图进行纠正。
warp操作就是双线性插值,看起来比较复杂的代码就是grid的生成,可以固定h,w的大小,在python命令行里自己输入一下那几行语句,从维度和具体的值来加深这一过程的理解。
class AlignedModule(nn.Module):def __init__(self, inplane, outplane, kernel_size=3):super(AlignedModule, self).__init__()self.down_h = nn.Conv2d(inplane, outplane, 1, bias=False) self.down_l = nn.Conv2d(inplane, outplane, 1, bias=False) self.flow_make = nn.Conv2d(outplane*2, 2,
kernel_size=kernel_size, padding=1, bias=False)def forward(self, x):low_feature, h_feature = xh_feature_orign = h_featureh, w = low_feature.size()[2:]size = (h, w)low_feature = self.down_l(low_feature)h_feature= self.down_h(h_feature)h_feature = F.upsample(h_feature, size=size,
mode="bilinear", align_corners=True)flow = self.flow_make(torch.cat([h_feature, low_feature],
1)) h_feature = self.flow_warp(h_feature_orign, flow,
size=size)return h_featuredef flow_warp(self, input, flow, size):out_h, out_w = sizen, c, h, w = input.size()# n, c, h, w# n, 2, h, wnorm = torch.tensor([[[[out_w,
out_h]]]]).type_as(input).to(input.device)h = torch.linspace(-1.0, 1.0, out_h).view(-1, 1).repeat(1,
out_w)w = torch.linspace(-1.0, 1.0, out_w).repeat(out_h, 1)grid = torch.cat((w.unsqueeze(2), h.unsqueeze(2)), 2)grid = grid.repeat(n, 1, 1,
1).type_as(input).to(input.device)grid = grid + flow.permute(0, 2, 3, 1) / normoutput = F.grid_sample(input, grid)return output2.Semantic Flow for Fast and Accurate Scene Parsing
论文地址:
https://arxiv.org/abs/2002.10120v3
代码地址:
https://github.com/lxtGH/SFSegNets
同样只看配准部分。
先各自经过一个1*1卷积到指定维数,再对低分辨率上采样,将两个分辨率特征相连,经过3×3卷积降到2维,分别代表x,y方向的offset map,再经过一个warp操作对低分辨率图进行纠正。
warp操作就是双线性插值,看起来比较复杂的代码就是grid的生成,可以固定h,w的大小,在python命令行里自己输入一下那几行语句,从维度和具体的值来加深这一过程的理解。
class AlignedModule(nn.Module):def __init__(self, inplane, outplane, kernel_size=3):super(AlignedModule, self).__init__()self.down_h = nn.Conv2d(inplane, outplane, 1, bias=False) self.down_l = nn.Conv2d(inplane, outplane, 1, bias=False) self.flow_make = nn.Conv2d(outplane*2, 2,
kernel_size=kernel_size, padding=1, bias=False)def forward(self, x):low_feature, h_feature = xh_feature_orign = h_featureh, w = low_feature.size()[2:]size = (h, w)low_feature = self.down_l(low_feature)h_feature= self.down_h(h_feature)h_feature = F.upsample(h_feature, size=size,
mode="bilinear", align_corners=True)flow = self.flow_make(torch.cat([h_feature, low_feature],
1)) h_feature = self.flow_warp(h_feature_orign, flow,
size=size)return h_featuredef flow_warp(self, input, flow, size):out_h, out_w = sizen, c, h, w = input.size()# n, c, h, w# n, 2, h, wnorm = torch.tensor([[[[out_w,
out_h]]]]).type_as(input).to(input.device)h = torch.linspace(-1.0, 1.0, out_h).view(-1, 1).repeat(1,
out_w)w = torch.linspace(-1.0, 1.0, out_w).repeat(out_h, 1)grid = torch.cat((w.unsqueeze(2), h.unsqueeze(2)), 2)grid = grid.repeat(n, 1, 1,
1).type_as(input).to(input.device)grid = grid + flow.permute(0, 2, 3, 1) / normoutput = F.grid_sample(input, grid)return output2.总结
这两篇论文解决多尺度特征配准问题的方式大同小异,区别就在于AlignSeg分别估计了 不同分辨率的offset map,并分别进行了纠正,而SFsegNet只对低分辨率图进行了纠正。前 者解释说估计两个的原因是,配准靠单方面无法完成。
有趣的是这两篇论文第一版上arXiv的时间都是Mon, 24 Feb 2020。
作者:图拉
这篇关于语义分割中多尺度特征的配准问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







