本文主要是介绍史上最细,自动化测试框架-数据驱动实战总结,一文概全...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录:导读
- 前言
- 一、Python编程入门到精通
- 二、接口自动化项目实战
- 三、Web自动化项目实战
- 四、App自动化项目实战
- 五、一线大厂简历
- 六、测试开发DevOps体系
- 七、常用自动化测试工具
- 八、JMeter性能测试
- 九、总结(尾部小惊喜)
前言
1、自动化测试框架概念
随着时代高速发展,面对市场强大的竞争,研发的产品需要快速完成研发和测试。面对质量和快速的交付双重压力下,我们需要让代码替代人工完成日益多CASE检查,自动化测试框架孕育而生。
自动化测试框架是一套包含测试case、测试结果、测试方法等一些实现对测试软件进行测试的解决方法。
对于一个刚刚起步的测试团队,选择一款自动化测试框架,它们帮我们提前定义好概念和CASE编写方法等集合,能在项目中产生收益。
2、关键字驱动
什么是关键字驱动?
键字驱动,又称为表格驱动,是一种独立于应用程序的自动化框架。
关键字驱动框架下将测试用例分为四个部分:
Test Step:测试步骤
Test Object: 测试步骤对象
Action:测试对象执行的动作
Test Data:测试对象需要的数据
关键字驱动特点:
关键字驱动的核心思想是把编码从测试用例和测试步骤分离出,对于不会编码的测试人也会编写自动化脚本
测试人员可参与:框架建立完成后,手工测试和非技术人员都可以编写个性化自动化脚本
易维护:开发人员只需要维护关键字开发,系统更新等工作,不用涉及到具体的测试
组件复用:关键字驱动模块化,提供代码框架的复用性
关键字驱动应用:
可以对行业里流行的selenium、APPium、uiautomator库进行二次封装成关键字
以关键字驱动的框架:Robotframework
3、数据驱动
什么是数据驱动?
数据驱动主要解决测试海量数据,而测试步骤固定的场景而产生的设计模式。
数据驱动是相同的测试脚本使用不同的测试数据执行,测试数据和测试行为完全分离。
数据驱动框架主要分为两部分:
测试步骤:通常结合关键字驱动来执行
测试数据:通常存储在数据库或者Excel表格中
数据驱动特点:
代码和数据分离
通常与关键字驱动结合组成自动化流程
4、PO模式
什么是PO模式?
PO 是 Page Object 缩写。PO模式是一种常见的设计模式。
PO模式把待测页面当成一个页面对象:
一个页面对象包含元素对象的定位和元素操作方法
将页面对象和真实的网站页面一一映射起来
PO 模式一般包名四层架构:
page_locator:页面对象的元素定位
page_object:页面对象操作方法
test_case:测试用例
bage_page:封装页面中的公共的方法
OP模式页面返回的原则:
返回SELF,应为操作完成页面停留在现在的页面
返回其他模块的对象,因为操作完成后页面跳转到其他的页面当中
返回元素定位信息或者元素属性
PO模式特点:
易维护:业务层和d功能层实现隔离
复用性高:对关键库进行封装和提取公共方法
代码可读性强:将不同内容进行不同封装,整体代码阅读性提升
代码耦合度低
PO模式应用:
PO模式通常应用在WEB-UI自动化测试应用上
5、混合模式
可以结合实际需求和不同模式的优缺点结合使用,搭建个性化自动化框架。
目前流行自动化框架所用到的库有:
web测试:selenium、watir、Robotframework
app测试:Appium
桌面程序:QTP、AutoRunner
安卓程序:UIautomator
6、数据驱动测试实战
参数化:
输入数据的不同从而产生不同的测试结果(简单来说就是将输入的数据作为变量传入)。
比如搜索商品,不同的搜索关键字和搜索条件作为入参,就会得到不同的搜索结果。
数据驱动:
测试数据的改变驱动自动化测试的执行,产生不同的测试结果,数据驱动本质上是高级的参数化。
对于测试数据,我们可以将其存放在代码的数据结构中(比如数组、集合),也可以存放在外部文件(比如json、csv、yaml、Excel)或数据库中,通过相应的读取技术拿到测试数据实现数据驱动测试。
各大语言测试框架都有对应的功能,比如Python的Unitest,Java的TestNG/Junit
如TestNG有提供DataProvider注解实现数据驱动测试
方式一:将测试数据保存到代码中(数组)
//指定数据提供者,注入测试数据到测试方法中实现数据驱动测试
@Test(dataProvider="getDatasFromArray")
public void test(String name,String phone,String pwd) {//TODO
}//从二维数组中获取数据驱动测试所需的测试数据(包含入参和期望值)
@DataProvider
public Object [][] getDatasFromArray(){Object [][] datas = {{"13323234545","123456","登录成功"},{"133232345451","123456","手机号码格式不正确"},{"13323234545","","密码不能位空"}};return datas;
}
方式二:将数据保存到外部的文件中(Excel)
//指定数据提供者,注入测试数据到测试方法中实现数据驱动测试
//需要注意的是:此时数据提供者返回的是一维数组,数组里元素类型是ExcelData对象,所以方法这里需要通过ExcelData类型接收
@Test(dataProvider="getDatasFromExcel")
public void test(ExcelData excelData) {//TODO
}//从外部文件(Excel)中获取数据驱动测试所需的测试数据
@DataProvider
public Object [] getDatasFromExcel(){//读取指定Sheet List<ExcelData> list = EasyExcel.read("filePath").head(ExcelData.class).sheet("Sheet1").doReadSync();//将集合转换为数组return list.toArray;}
数据驱动测试的优点:
1)相似的测试步骤只需要编写一条用例,可以直接通过多条测试数据驱动执行,提高了测试脚本的复用性
2)测试数据和测试脚本分离,提高后期脚本可维护性
无论是将测试数据保存在代码或者文件,又或者数据库中都可以。至于保存在哪里取决于测试数据量大小和使用场景
少量的数据,比如账号相关的信息,可以直接写入代码中进行维护;
数据的量级在几十~几千之间,可以通过外部的文件进行管理,比如Excel
当数据量级特别大的情况下,通过数据库这样方式的管理数据相对比较高效
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
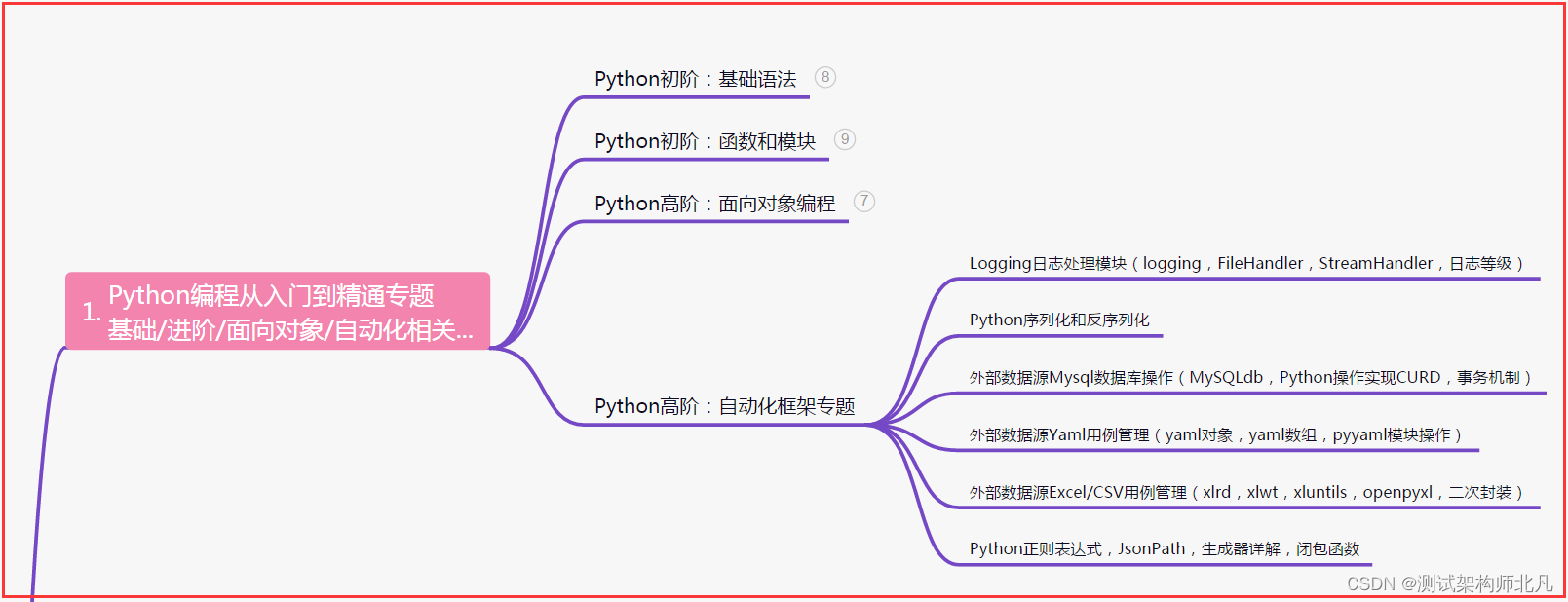
一、Python编程入门到精通
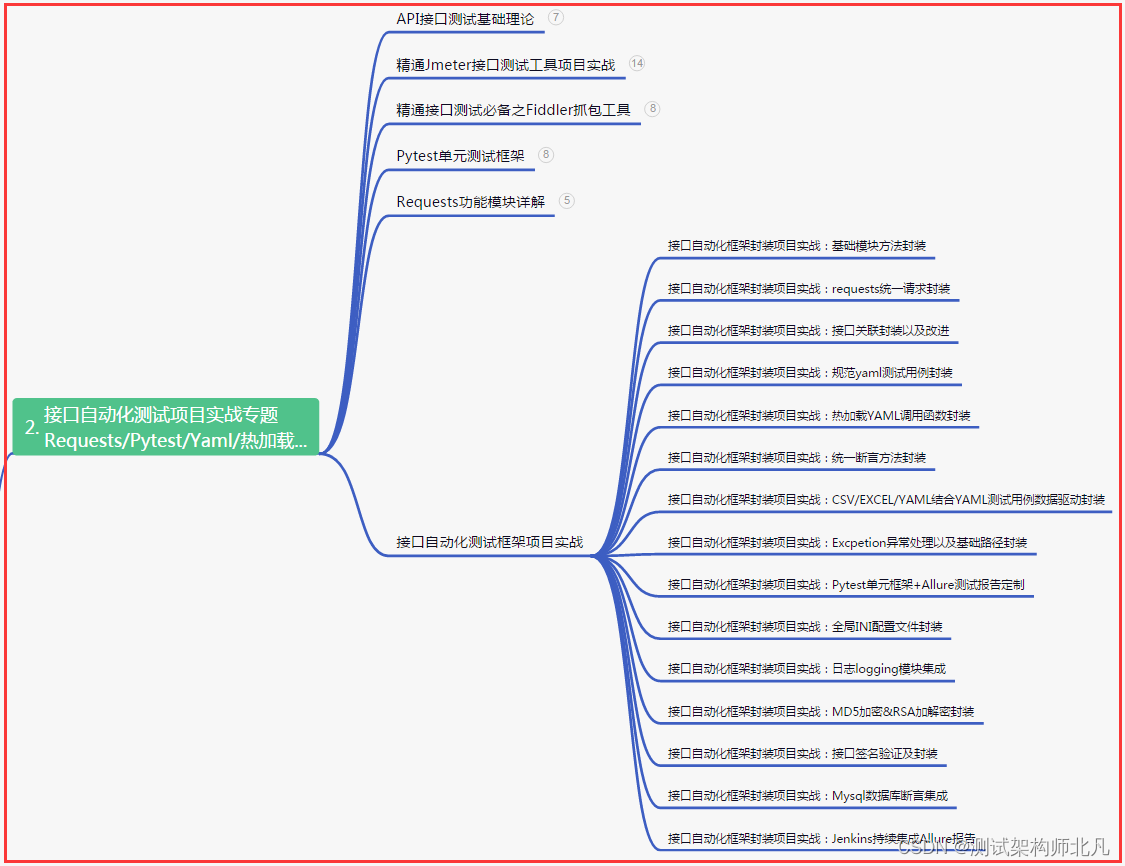
二、接口自动化项目实战
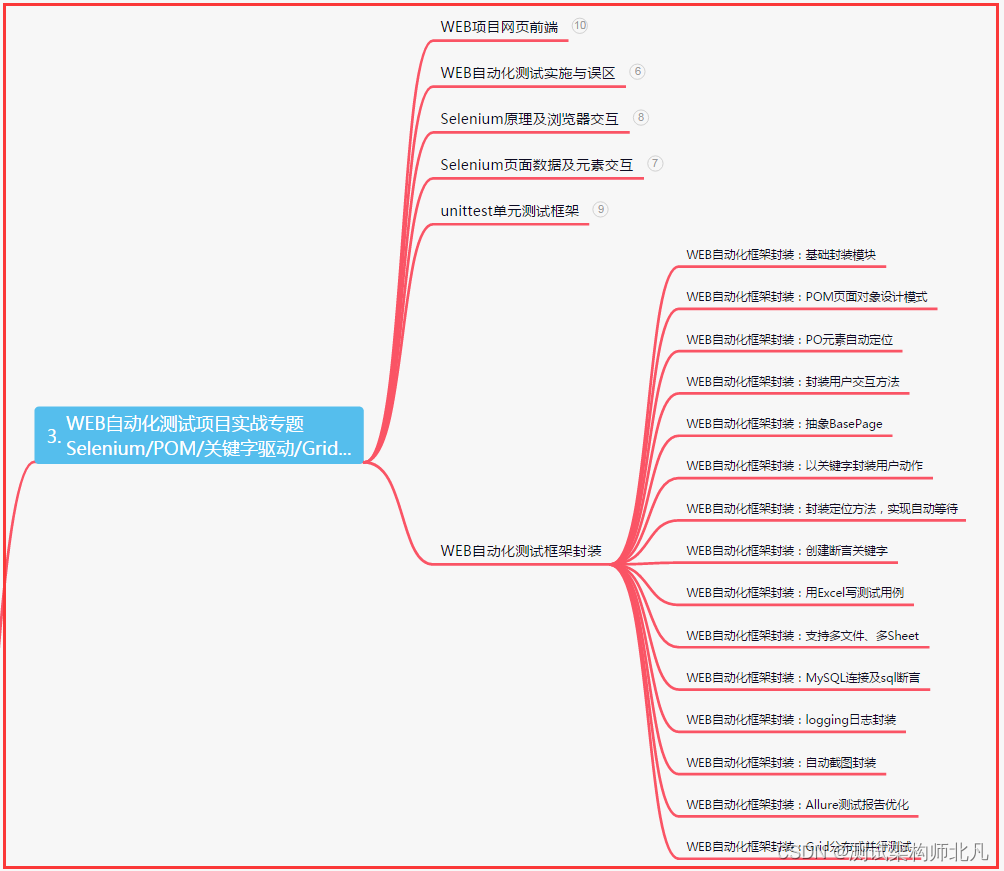
三、Web自动化项目实战
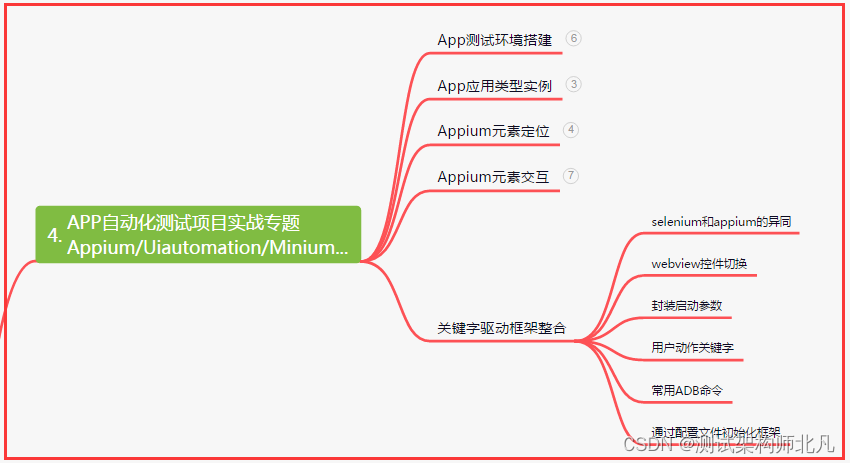
四、App自动化项目实战
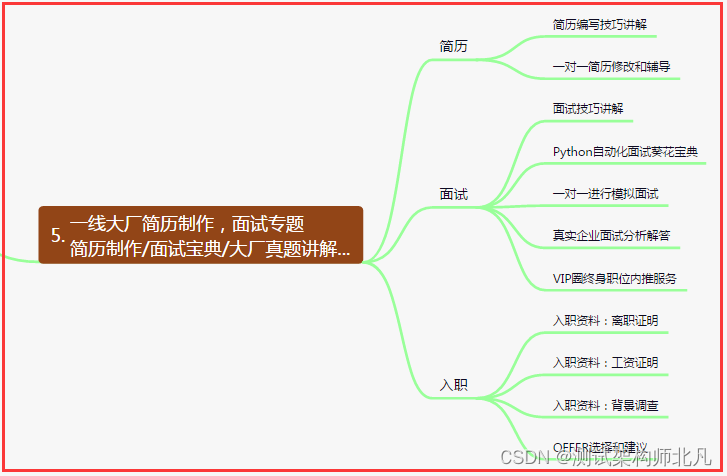
五、一线大厂简历
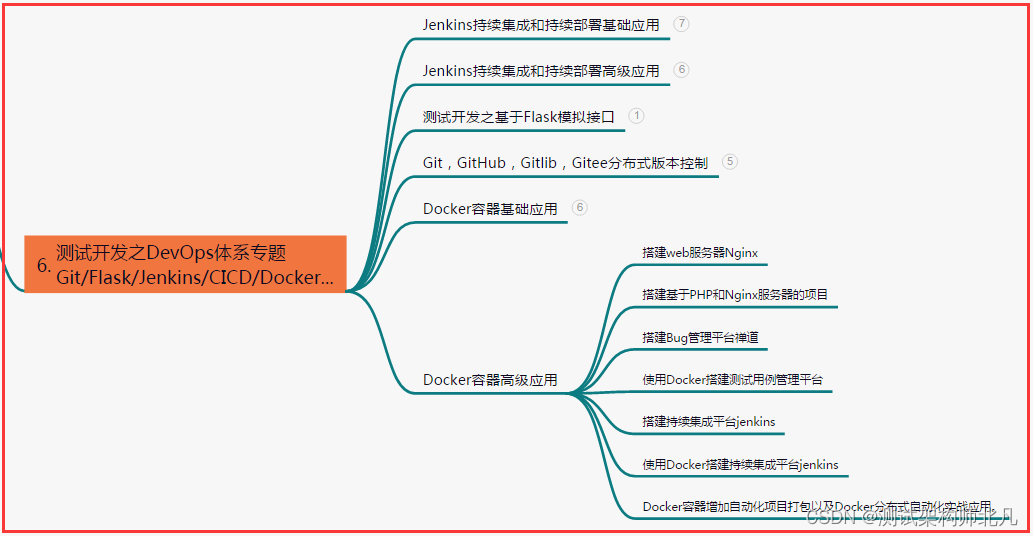
六、测试开发DevOps体系
七、常用自动化测试工具

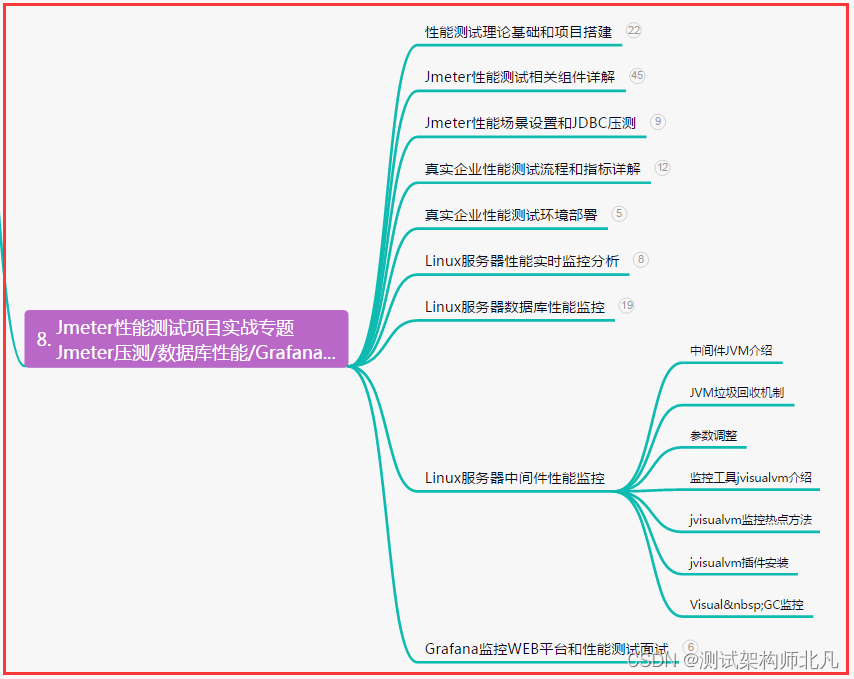
八、JMeter性能测试
九、总结(尾部小惊喜)
奋斗的道路上充满挑战,但正是因为挑战,我们才能成就非凡。相信自己的力量,不畏困难,追逐梦想的脚步绝不止步!
每一次努力,都是为了超越昨天的自己。坚持不懈,奋斗不止,勇往直前,相信自己的力量,你将创造属于自己的辉煌!
不要害怕失败,因为失败是通往成功的必经之路。只要坚持不懈,执着追求,一定能够创造属于自己的辉煌人生!
这篇关于史上最细,自动化测试框架-数据驱动实战总结,一文概全...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




