本文主要是介绍Time Series Data and Recent Imputation Techniques for Missing Data: A Review,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

Abstract
多感官系统的发展和数据收集技术的持续应用都促进了时间序列数据的爆炸式增长。然而,由于多种因素的影响,经常会遇到不希望的数据点缺失。无法对缺失数据进行分析和建模极大地阻碍了分类和预测活动。处理时间序列数据的传统技术经常会增加偏差,并对底层数据创建过程做出重大假设,这可能导致预测或分类模型的开发不准确。在应用正确的插补方法之前,需要充分理解时间序列数据的特征。本研究旨在简要介绍时间序列数据的类型和缺失数据机制,并回顾几种方便时间序列数据填补数据空白的方法。该综述重点介绍了单变量和多变量时间序列数据的数据预处理阶段处理缺失值的当前方法,以及用于评估插补方法性能的方法。它实际上包括这些方法的一些优点和缺点。结果提供了可用于进一步开发新的插补方法的信息。
I. INTRODUCTION
时间序列数据在数据挖掘和分析中非常有价值,但它通常会带来数据部分稀疏的问题,这种问题在许多领域的现实数据集中经常出现。这一普遍存在的问题通常会提供不准确和有偏见的结果,从而损害数据分析的性能。丢失数据点的原因可能有五 (5) 个主要原因:数据输入不完整 [1]–[3][4]、测量错误 [5]、设备故障、通信和传输问题 [6]、[7]、或天气状况。
时间序列插补是预处理阶段涉及的最重要的活动之一。质量和 该过程的精度将直接影响估计的时间序列的质量。这是数据驱动建模中反复出现的问题;因此,必须从原始数据中估算缺失值,以提高时间序列分析的准确性。
通过对新提出的数据插补方法的调查和分析,可以发现准确性、性能和所需时间方面的显着改进。本研究的目的是为研究人员提供 2019 年至 2022 年出版物的参考,以熟悉用于估算时间序列数据缺失值的最新技术。本文的主要贡献总结如下:
1.它对时间序列数据的类型给出了启示。
2. 它解释了缺失数据的类型。
3.它强调了用于归档时间序列数据缺失数据的新兴方法。
4.它总结了先前工作中已实施的插补绩效衡量方法。
本文的其余部分分为五 (5) 个主要部分,从第二部分开始,A 部分概述了时间序列数据的类型。B 部分提供了时间序列组件的描述。接下来的 C 部分解释了缺失数据的类别。第三节提供了综述的正文,然后按照用于单变量时间序列(UTS)数据和多变量时间序列(MTS)数据插补的方法类型将其分为几个小节。第四节总结了用于衡量插补性能的方法,最后第五节解释了研究结果并强调了当前用于时间序列数据插补的主要方法。接下来是正在进行的研究领域以及对该领域应用的方法的一些建议 。
本文的其余部分分为五 (5) 个主要部分,从第二部分开始,A 部分概述了时间序列数据的类型。B 部分提供了时间序列组件的描述。接下来的 C 部分解释了缺失数据的类别。第三节提供了综述的正文,然后按照用于单变量时间序列(UTS)数据和多变量时间序列(MTS)数据插补的方法类型将其分为几个小节。第四节总结了用于衡量插补性能的方法,最后第五节解释了研究结果并强调了当前用于时间序列数据插补的主要方法。接下来介绍了正在进行的研究领域以及对该领域应用的方法的一些建议。
2.TIME SERIES DATA
时间序列数据是随着时间的推移连续测量产生的信息的集合。它是通过持续监测而获得的观察结果的集合。由于时间是所有可观察现象的组成部分,时间序列数据无处不在,使我们能够开发更智能的系统,提高几乎所有运营的效率,并实时预测未来事件。收集和分析时间序列数据的能力在商业世界中变得越来越重要,并且作为技术领域创新的驱动力。
A. Types of Time Series Data
在大多数情况下,预计时间序列是按规则的时间间隔创建的;因此,这些时间序列被称为常规时间序列。时间戳可以明确地包括在数据中,或者可以从生成数据的间隔推断出来。无论哪种方式,都可以使用该数据。规则时间序列的逆序列称为不规则时间序列。时间序列后面跟着时间序列中的数据,尽管测量可能不会在整个序列中以一致且规则的时间间隔进行。例如,地震数据经常沿着空间坐标不规则且稀疏地收集。在时态数据库领域,重点放在与特定时期相关的数据,或者在特定时间范围内有效的数据[8]。它可能并不全年有效,仅在特定时间段内有效。时态数据库按时间顺序存储,分析操作必须考虑整个时间序列,而不是单个时间点存储的值。处理规则和不规则时间序列数据需要不同的过程。
除此之外,时间序列数据集可以测量一个或多个变量。根据时间序列中有多少个变量以及它们之间的关系,时间序列数据可以分为三 (3) 组之一;单变量时间序列 (UTS)、多变量时间序列 (MTS) 或多重,并总结在图 1 的图表中:
1.UTS 数据由随时间推移重复测量单个变量组成。
2.MTS 由随时间推移收集的多个关联变量的连续测量值组成。双变量时间序列包含两个变量,也被视为 MTS 数据。在 MTS 中,每个变量都以某种方式与其他变量相连。
3.多个时间序列数据包含同一时间段内多个单独实体的测量值。也可以说是包含多个单变量时间序列数据的数据集。
B. Types of Time Series Components
时间序列数据有四个组成部分,即趋势、季节性、周期性和随机变化:
1.趋势部分:数据将呈现出长期的峰值、上升和下降的趋势测量和监测。在大多数情况下,它只是一次性发生,之后就不再出现任何痕迹。
2.季节性成分:该成分经历可预测且一致的变化,并且每年在同一时间发生。考虑了区间内波动,这表明一年内存在重复模式。例如,它可以是一周、一个月或一年内的模式。这些波峰和波谷可以在时间序列的不同点找到。术语“季节性”是指可以预测并且在一年中定期发生或重复发生的任何变化或趋势。
3.周期性成分:该数据与季节性成分数据类似,只是测量和监测时间超过一年。
4.随机变化成分:该成分具有不可预测的模式。它不显示一段时间内的高峰和低点以及波动的趋势。
C. Categories of Missing Data
数据测量是在许多不同的条件下进行的,丢失数据自然是不可避免的。缺失数据可分为三 (3) 种所谓的“缺失机制”;完全随机缺失(MCAR)、随机缺失(MAR)和非随机缺失(NMAR)[9]、[10]。缺失机制的说明如图 2 所示。

1.随机缺失 (MAR):数据点缺失的倾向与缺失数据无关,但与某些观察到的数据有关。
2.完全随机缺失 (MCAR):特定值的缺失与其预期值或其他变量的值无关。
3.非随机缺失 (MNAR):两种可能的解释是缺失值取决于假设值,或者缺失值取决于另一个变量的值。
对于时间序列数据,最好使用连续数据进行插补。准确的模型开发和验证通常需要相同形状和分辨率的连续数据集,这既是研究的障碍,也是研究的动力。已经采取了几种方法 提出根据缺失值的机制来修复缺失值,从传统的方法到更现代的处理缺失值的方法。
3. RECENT IMPUTATION METHODS
已经进行了大量研究来检查丢失数据点的各种过程以及处理不同数据类型的适当方法。迄今为止,已经发表了大量关于缺失数据估算的研究。估算缺失数据最简单和最常用的方法是均值估算,例如使用均值、众数或中位数数据来替换缺失数据点。另一种是线性插值、多项式插值或样条插值,最后是最后观察结转(LOCF)[11]-[13]。然而,这些方法不适合处理多种类型的数据缺口,尤其是大数据缺口。它最适用于一些连续缺失值或短数据间隙。因此,关于使用自回归积分移动平均 (ARIMA) 算法来估算数据差距的经典方法的研究很少。 [14]、[15]和Hotdeck[1]、[16]考虑了分析的统计特征。
缺失值的插补过程可以是单一插补(仅提供一种可能的响应来填充缺失值),也可以是多重插补。单一插补包括均值插补、套牌操作、回归、期望最大化和删除等。单一插补是一步过程,而多重插补是一个多阶段过程,包括插补、分析和合并。它通过反复尝试填充缺失值的空白来生成大量完整的数据集。
最近,提出的用于估算时间序列数据的方法已被用来取代和改进传统和经验方法,以更有效地解决过去十年中的缺失值问题。数据插补的性能很大程度上取决于针对缺失数据类型选择适当的插补方法。因此,在这项工作中,插补方法根据这两 (2) 种数据类型(UTS 和 MTS)进行分类。
A. Imputation for Univariate Time Series Data (UTS)
填充 UTS 数据中的缺失值(一维值)是一项极具挑战性的工作,尤其是当它是非线性且随机类型的数据缺失时。用于分析和建模的可用数据可能非常有限。大多数已发现的可用插补方法都适用于 MTS 数据。然而,本节分享了关于 UTS 数据的可用研究,这是一种对未来工作有用的单一时间相关变量插补程序。
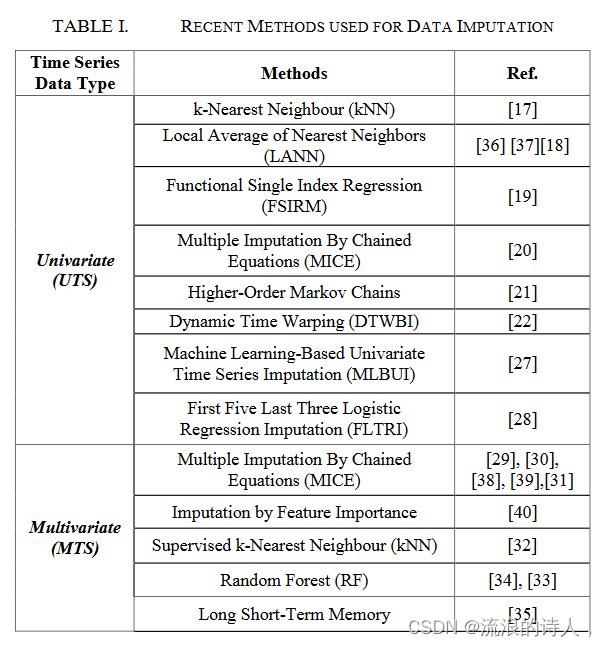
最常用的方法之一是 k 最近邻算法 (kNN)。 kNN 已经针对许多不同的领域进行了一些改进和修改。 Dubey A.和Rasool A.已经使用top k-NN来估算生物信息学中的微阵列基因表达数据,在top kNN之前几乎没有局部估算方法[17]。它使用图相似性结合 K 均值聚类技术来提供不完整数据的近似值,该数据采用顶级 kNN 技术进行,并将按聚类的加权函数放在一起。它适用于缺失数据集范围从 0.02% 到48.05%。另一方面,Anibal Flores 等人[18]针对 UTS 算法中气象时间序列数据集的短间隙,提出了两种从 kNN 改进的算法。第一个是最近邻局部平均 (LANN) 算法基于两个最近邻的平均值,而 LANN+ 基于缺失值或 NA 的四 (4) 个最近邻的平均值。
N. Ling等人[19]使用单指数模型来降低解释变量的复杂性并避免多元回归中的维数灾难。他们使用核方法构建了该模型的估计量,并在一些通用环境下建立了均匀的几乎完全收敛率和渐近分布。另一方面,Denitsa Grigorova 等人 [20] 强调了多重插补(MI)中的两种通用方法,一种是同时从多元分布中获取所有不充分变量的不完整数据,另一种是通过链式方程进行多元插补( MICE)使用一系列单变量条件分布,通过基于模型中其他变量获取单变量密度来估计缺失数据。专注于对缺失单变量数据的大差距进行插补的两种方法是高阶马尔可夫链 [21],它使用单变量插补方法和多元插补方法,另一种是 T.T.H Phan 等人 [22] 使用的 (DTWBI),通过发现类似的方法插补间隙之前窗口期内的子序列数据。
Yuehua Liu等人[23]提出的如何处理较大数据间隙的方法被应用于UTS的物联网数据。为了计算缺失点的最准确值,该研究使用了称为 It-MSSTLecImp 的多个分段稀疏迭代。间隙最初被分成不同的部分开始,然后继续进行间隙重组和间隙合成。单变量数据类型的一个不同类别是季节性数据类型,其中 Zhou Y. 等人 [24] 和 J. Park 等人 [25] 研究了合适的插补方法。 Zhou Y. 重点介绍了更多关于估算时间动态时间序列数据的内容。 Zhou Y.还强调,循环神经网络(RNN)[26]仅适用于短间隙。 Park 等人使用深度学习 (DL) 和多层感知器 (MLP) 方法来处理长时间连续丢失的数据点。
T. Phan [27] 试验的基于机器学习的单变量时间序列插补 (MLBUI) 方法将单变量时间序列转换为多变量,并使用单变量的所有可用值来预测缺失的值。引入了一种新的单一插补方法,称为“前五后三逻辑回归插补”(FTLRI),以便在空气质量测量中获得更有效的离散缺失数据插补。该技术将传统的回归模型与“前五后三”结合起来,可以解释时间和属性之间的关系[28]。
据观察,尽管机器学习(ML)和深度学习方法最近被添加到插补方法池中,但他们的经验方法仍然适用于 UTS 数据。接下来,我们看看应用于 MTS 数据的插补方法。
B. Imputation for Multivariate Time Series Data (MTS)
用于估算 MTS 数据的方法之一是 MICE,用于估算时空数据中的缺失值。将 MICE 与 R 完成的其他插补方法相结合。Wu [29] 将长时间连续缺失数据插补的准确性提高了 23%。 Y. Luo [30] 是应用 MICE 的其他一些研究,他讨论了绝大多数临床数据集是纵向设计的,并且经常缺少数据,目前常用的大多数插补算法并不直接处理纵向临床时间系列。 MICE 还用于填补铜价的缺口 [31],并提供非常低的 RMSE 和 MAPE 测量值。
MTS 的回归插补已使用监督 kNN 实现,[32] 将其与超向量回归 (SVR) 和通用回归神经网络 (GRNN) 进行比较,以插补缺失的地面电磁数据。结果发现,SVR 将缺失的数据点改善了高达 80%。随机森林 (RF) 算法也用于使用各个全值的平均值来处理 MTS 数据。然后,该算法通过利用邻近数据点来重复改进缺失数据插补[33]。 Yu Gu 等人[34] 完成了一个临时 RF,为了提供新数据的准确预测,收集每棵树的插补,然后取平均值。使用射频可以自然地确定哪些因素最重要。 [7]、[35] 使用的长短期记忆 (LSTM) 方法发现,该方法对于各种不同的缺失模式很有用,并且比当前可用的其他技术提供更准确的预测。
总之,众所周知,MTS 数据使用 MICE、kNN、RF 和其他深度学习方法(例如 LSTM)来处理缺失数据。表 1 列出了所收集研究的摘要。
4.IMPUTATION PERFORMANCE MEASUREMENT USED
为了评估一系列估算数据的性能,使用了多种方法并将其性能与其他可用的现有或创新方法进行比较。在总结的所有插补技术中,70%其中使用均方根误差(RMSE)作为性能衡量标准,同时结合一到两种其他方法,如绝对百分比误差(MAPE)、平均绝对误差(MAE)、对称平均绝对百分比误差(SMAPE)、均方对数误差 (MSLE)、标准差 (SD) 和百分比偏差 (PB)。
5.CONCLUSION
时间序列数据的插补方法可以分为两类: UTS 和 MTS 缺失数据。对于UTS,可以使用的方法包括但不限于单变量时间序列算法。单变量时间序列数据的著名方法有 LANN、MICE、kNN 和回归。而MTS,大多采用MICE、kNN和RF的方法。然而,通过方法的组合和创新,可以探索出很多方法来评估针对特定领域的特定数据类型的最有效方法。一般来说,大多数方法都使用回归来识别数据模式并估计新数据以填补现有空白。 RMSE 是用于评估估算数据的准确性和所用方法性能的必须测量。
这篇关于Time Series Data and Recent Imputation Techniques for Missing Data: A Review的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




