本文主要是介绍D-Wave等研究团队在可编程2000量子比特一维伊辛模型中模拟量子相变,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

D-Wave 量子退火机在光刻芯片上使用数千个超导通量量子比特,悬浮在接近绝对零度的环境中。(图片来源:网络)
在处理一些复杂的任务时,量子计算机比经典计算机更具优势,但在充分发挥其潜力前,还需要克服许多挑战。物理学家和计算机科学家一直试图如实评估量子计算技术在不久的将来所拥有的实力。
量子模拟,即使用可编程模拟设备实现的量子系统,已被证明对于判断量子计算机的实用潜力特别有价值。可以使用量子模拟研究的一种方法是量子退火,这是一种基于工程量子涨落的优化过程。
D-Wave以及加拿大、美国和日本的研究人员最近在可编程的2,000量子比特一维伊辛模型中模拟了量子相变。他们的实验结果发表在《Nature Physics》,为未来的量子优化和模拟工作提供了重要价值。
实验研究人员之一Andrew D. King说:“相干退火是我们长期以来一直想要展示的东西。它使我们能将可编程量子系统的行为与理想的薛定谔动力学进行比较,提供了强有力的量子性证据与基准。对于经典方法通常无法解决的任务,一维链非常适合,因为它具有众所周知的闭合式解决方案,这意味着我们可以用经典方式解决,而无需详细模拟量子动力学。”
一维伊辛链的量子模拟之前已经由哈佛大学及其他研究团队完成。然而,King和他的同事进行的模拟是首次使用基于退火的量子计算机进行的。此外,研究人员能够实现更大、更强烈的相关状态。
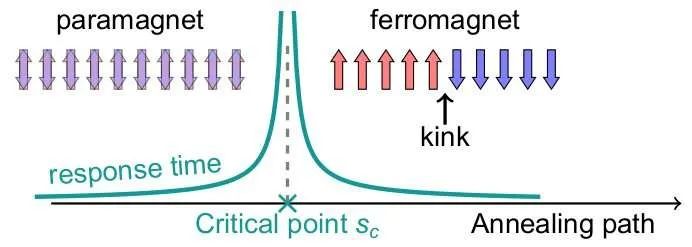
模拟从量子顺磁叠加态开始,并以不同的速度穿过量子相变。随着系统响应时间的增长,在向上或向下旋转的相反域之间形成“扭结”。这些扭结的密度和间距显示了量子临界动力学的特征。(图片来源:网络)
King解释说:“我们实验中的关键变量是退火时间,这是D-Wave处理器从其初始量子叠加态到计算的经典端点所需的时间。通常,系统会设置500纳秒的速度限制,以允许控制电路上的容差。然而,在这项工作中,我们的速度比这快了100倍。”
由于他们的系统达到了更高的速度,King和他的同事们对硬件的要求会更加严格,并且要使用新的软件方法。最终使他们能完美地同步系统中的数千个量子比特。
研究人员使用D-Wave系统创建的高度可编程处理器进行了模拟。为了更可靠地测试其有效性,他们选择模拟一个极其简单且易于理解的量子相变。
King说:“我们在实验中和没有环境影响的理想量子模型之间看到了高度一致性,这是量子退火领域的新发展。它不仅证明了该系统属于量子水平,而且我们可以将更复杂的系统编程到量子退火器中,它将遵循薛定谔方程的真实量子动力学,这通常不能被经典模拟。”
总之,该团队发现他们的模拟与量子理论的预测一致。在未来,他们的工作可以为研究不同的量子相变开辟新成果。在接下来的工作中,King和他的同事们希望使用可编程D-Wave处理器来模拟更多奇特的量子相变,这是使用经典计算机无法模拟的。
King 补充说:“大多数人希望将量子退火用于量子模拟,或者用于优化。我们在这项工作中研究的教科书式量子相变仅间接适用于优化,因此将这两个领域联系在一起很重要。我们已经知道量子退火器可以非常快速地解决优化问题。我们的下一项研究重点将是相干退火,以详细解释量子临界动力学在量子退火优化中的作用。”
文章参考链接:
https://phys.org/news/2022-10-coherent-simulation-quantum-phase-transition.html
编译:卉可
编辑:慕一
这篇关于D-Wave等研究团队在可编程2000量子比特一维伊辛模型中模拟量子相变的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









