本文主要是介绍Mindspore 公开课 - GPT,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
GPT Task
在模型 finetune 中,需要根据不同的下游任务来处理输入,主要的下游任务可分为以下四类:
- 分类(Classification):给定一个输入文本,将其分为若干类别中的一类,如情感分类、新闻分类等;
- 蕴含(Entailment):给定两个输入文本,判断它们之间是否存在蕴含关系(即一个文本是否可以从另一个文本中推断出来);
- 相似度(Similarity):给定两个输入文本,计算它们之间的相似度得分;
- 多项选择题(Multiple choice):给定一个问题和若干个答案选项,选择最佳的答案。
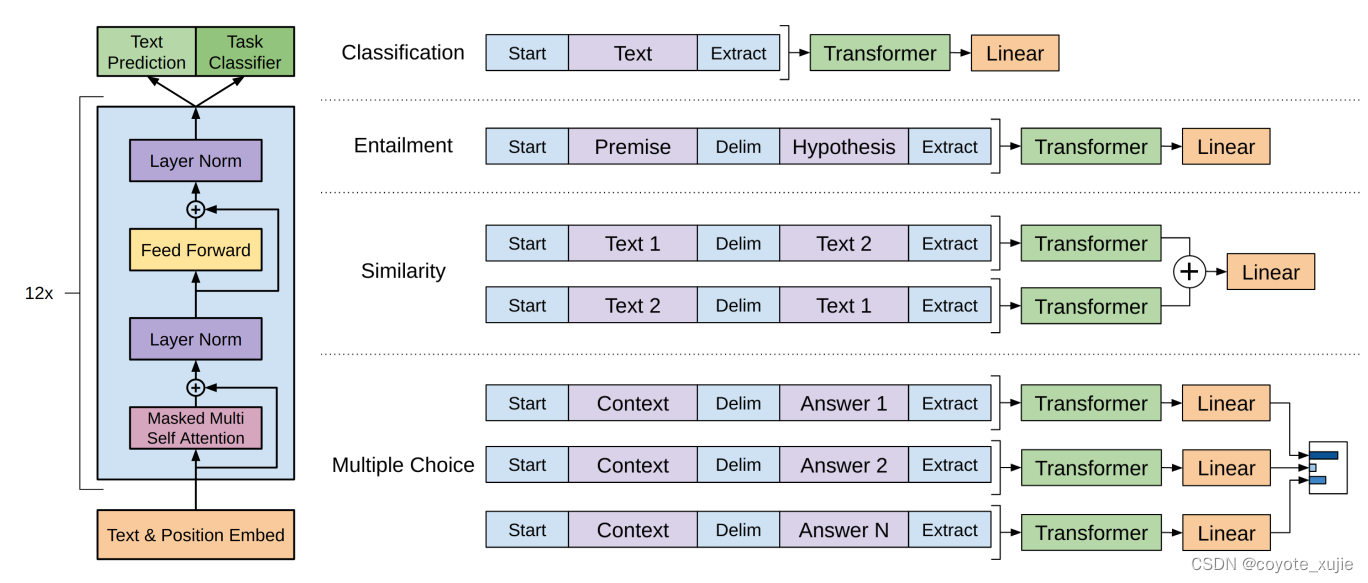
我们使用IMDb数据集,通过finetune GPT进行情感分类任务。
IMDb数据集是一个常用的情感分类数据集,其中包含50,000条影评文本,其中25,000条用作训练数据,另外25,000条用作测试数据。每个样本都有一个二元标签,表示影评的情感是正面还是负面。
import osimport mindspore
from mindspore.dataset import text, GeneratorDataset, transforms
from mindspore import nnfrom mindnlp import load_dataset
from mindnlp.transforms import PadTransform, GPTTokenizerfrom mindnlp.engine import Trainer, Evaluator
from mindnlp.engine.callbacks import CheckpointCallback, BestModelCallback
from mindnlp.metrics import Accuracy
数据预处理
# 加载数据集
imdb_train, imdb_test = load_dataset('imdb', shuffle=False)
通过load_dataset加载IMDb数据集后,我们需要对数据进行如下处理:
- 将文本内容进行分词,并映射为对应的数字索引;
- 统一序列长度:超过进行截断,不足通过占位符进行补全;
- 按照分类任务的输入要求,在句首和句末分别添加Start与Extract占位符(此处用 <bos>与 <eos>表示);
- 批处理。
import numpy as npdef process_dataset(dataset, tokenizer, max_seq_len=256, batch_size=32, shuffle=False):"""数据集预处理"""def pad_sample(text):if len(text) + 2 >= max_seq_len:return np.concatenate([np.array([tokenizer.bos_token_id]), text[: max_seq_len-2], np.array([tokenizer.eos_token_id])])else:pad_len = max_seq_len - len(text) - 2return np.concatenate( [np.array([tokenizer.bos_token_id]), text,np.array([tokenizer.eos_token_id]),np.array([tokenizer.pad_token_id] * pad_len)])column_names = ["text", "label"]rename_columns = ["input_ids", "label"]if shuffle:dataset = dataset.shuffle(batch_size)dataset = dataset.map(operations=[tokenizer, pad_sample], input_columns="text")dataset = dataset.rename(input_columns=column_names, output_columns=rename_columns)dataset = dataset.batch(batch_size)return dataset
加载 GPT tokenizer,并添加上述使用到的 <bos>, <eos>, <pad>占位符。
gpt_tokenizer = GPTTokenizer.from_pretrained('openai-gpt')special_tokens_dict = {"bos_token": "<bos>","eos_token": "<eos>","pad_token": "<pad>",
}
num_added_toks = gpt_tokenizer.add_special_tokens(special_tokens_dict)
由于IMDb数据集本身不包含验证集,我们手动将其分割为训练和验证两部分,比例取0.7, 0.3。
imdb_train, imdb_val = imdb_train.split([0.7, 0.3])dataset_train = process_dataset(imdb_train, gpt_tokenizer, shuffle=True)
dataset_val = process_dataset(imdb_val, gpt_tokenizer)
dataset_test = process_dataset(imdb_test, gpt_tokenizer)
模型训练
同BERT课件中的情感分类任务实现,这里我们依旧使用了混合精度。另外需要注意的一点是,由于在前序数据处理中,我们添加了3个特殊占位符,所以在token embedding中需要调整词典的大小(vocab_size + 3)。
from mindnlp.models import GPTForSequenceClassification
from mindnlp._legacy.amp import auto_mixed_precisionmodel = GPTForSequenceClassification.from_pretrained('openai-gpt', num_labels=2)
model.pad_token_id = gpt_tokenizer.pad_token_id
model.resize_token_embeddings(model.config.vocab_size + 3)
model = auto_mixed_precision(model, 'O1')loss = nn.CrossEntropyLoss()
optimizer = nn.Adam(model.trainable_params(), learning_rate=2e-5)metric = Accuracy()ckpoint_cb = CheckpointCallback(save_path='checkpoint', ckpt_name='sentiment_model', epochs=1, keep_checkpoint_max=2)
best_model_cb = BestModelCallback(save_path='checkpoint', auto_load=True)trainer = Trainer(network=model, train_dataset=dataset_train,eval_dataset=dataset_val, metrics=metric,epochs=3, loss_fn=loss, optimizer=optimizer, callbacks=[ckpoint_cb, best_model_cb], jit=True)trainer.run(tgt_columns="label")
模型评估
evaluator = Evaluator(network=model, eval_dataset=dataset_test, metrics=metric)
evaluator.run(tgt_columns="label")
这篇关于Mindspore 公开课 - GPT的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









