本文主要是介绍NLP论文阅读记录 - WOS | 2023 TxLASM:一种新颖的与语言无关的文本文档摘要模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 0、论文摘要
- 一、Introduction
- 1.1目标问题
- 1.2相关的尝试
- 1.3本文贡献
- 二.文献综述及相关工作
- 三.本文方法
- 四 实验效果
- 4.1数据集
- 4.2 对比模型
- 4.3实施细节
- 4.4评估指标
- 4.5 实验结果
- 4.6 细粒度分析
- 五 总结
- 思考
前言

TxLASM: A novel language agnostic summarization model for text documents(2312)
0、论文摘要
在自然语言处理(NLP)领域,大多数自动文本摘要方法依赖于所摘要文本的语言和/或领域的先验知识。这种方法需要依赖于语言的词性标注器、解析器、数据库、预结构化词典等。
在这项研究中,我们提出了一种新颖的自动文本摘要模型,文本文档 - 语言无关摘要模型(TxLASM),它能够以与语言/领域无关的方式执行提取文本摘要任务。 TxLASM 取决于所概括的文本主要元素的具体特征,而不是其领域、上下文或语言,因此不需要依赖于语言的预处理工具、标记器、解析器、词典或数据库。在 TxLASM 中,我们提出了一种新颖的技术来编码主要文本元素(段落、句子、n-gram 和单词)的形状;
此外,我们提出了独立于语言的预处理算法来规范化单词并执行相对词干或词形还原。这些算法及其形状编码技术使 TxLASM 能够提取文本元素的内在特征并对它们进行统计评分,然后提取独立于文本语言、领域和上下文的代表性摘要。
TxLASM 应用于英语和葡萄牙语基准数据集,并将结果与最近文献中提出的 12 种最先进的方法进行了比较。此外,该模型还应用于法国和西班牙新闻数据集,并将结果与标准商业摘要工具获得的结果进行了比较。 TxLASM 的性能优于所有 SOTA 方法以及所有四种语言的商业工具,同时保持其与语言和领域无关的性质。
一、Introduction
1.1目标问题
互联网的快速发展和网络文本数据的大规模指数增长给文本管理、分类和信息检索相关的任务带来了巨大的挑战。因此,自动文本摘要(ATS)正在成为解决这一问题的极其重要的手段。ATS倾向于挖掘原文的主旨,然后自动生成简洁易读的摘要,反映文本中的核心重要信息。因此,开发高效的文本摘要模型对于信息检索、知识推理、文本处理以及后续分类和理解的降维至关重要。
随着计算技术的最新进展,自然语言处理(NLP)领域通过采用人工智能的模型和方法而获得了巨大的优势。在本研究中,我们专注于开发与语言无关的摘要模型,旨在通过提出一系列与领域和语言无关的工具来提高 NLP 领域的泛化性能。
1.2相关的尝试
目前对人类皮层句子处理的描述区分了三个语言处理阶段(Friederici,2002)。第一个处理阶段基于句子级别的词类别信息。第二阶段计算句子中的句法和语义关系,其中涉及检测动词与其参数之间的关系,以及随后的主题角色分配。这些步骤导致了兼容解释和理解的第三阶段(Friederici,2011)。因此,为了实现书面文本的有效摘要任务,首先应提取相关单词和句子,然后与主题理解或上下文相关,以获得类似人类的理解。单词本身应分为停用词、命名实体(名词、具体概念等)以及动词,介词等
因此,对所概括文本的语言和/或领域的先验知识是大多数 ATS 模型的关键要求。在文本的语言或领域未知或快速变化的情况下,这可能会受到限制。
1.3本文贡献
在这项研究中,我们的目标是以与语言无关的方式实现类似水平的文本理解,避免提取需要语言和/或其上下文先验知识的动词、名词或其他句法关系。相反,我们使用新颖且完全与语言/领域无关的工具提取突出的短语以形成提取摘要。
正如下一节(文献综述和相关工作)中将详细讨论的,ATS 可以使用多种方法和技术来执行。其中绝大多数依赖于预结构化词典、数据库、词性标注器和解析器,这些都依赖于语言。换句话说,这种方法需要对要总结的文本语言以及在某些情况下其上下文领域的先前知识。当模型面对新的语言和/或领域时,这样的先决条件可能会影响模型的泛化性能。此外,高效的词性标注器或解析器并不总是可用于特定语言,而且词典大多是上下文相关的,因此,为所有语言准备和完善特定领域的词典被认为是语言研究人员面临的一大挑战。
除了预处理工具的语言依赖性和词典的上下文依赖性之外,获得有效的代表性摘要可能还需要提取或识别命名实体(NE)和具体概念(CC),因为它们对摘要质量的影响。此类任务本质上严重依赖于先前对要总结的文本的语言和/或上下文的检测。
因此,本研究的主要目标是提出一种能够以独立于语言和领域的方式执行有效的提取文本摘要的模型。因此,我们提出了一种新颖的提取文本摘要模型,即文本文档 - 语言无关摘要模型(TxLASM),它能够以完全与语言和领域无关的方式执行提取文本摘要,从而避免准备语言/领域的需要特定工具和/或语料库。
所提出的模型取决于所概括的文本主要元素的具体特征,而不是其领域、上下文或语言,因此排除了对语言相关预处理工具、标记器、解析器、词典或数据库的需要。在 TxLASM 中,我们提出了一种新颖的技术来编码主要文本元素(段落、句子、n-gram 和单词)的形状;此外,我们提出了独立于语言的预处理算法来规范化单词并执行相对词干或词形还原。这些算法及其形状编码技术使 TxLASM 能够提取主要文本元素的内在特征,对它们进行统计评分,并识别有影响力的标记(NE 和 CC),以提取独立于文本语言和/或其上下文域的代表性摘要。
总之,我们的贡献如下:
a)我们提出了一种简单但高效的、与语言和领域无关的文本文档摘要模型,名为“TxLASM”。
b) TxLASM 是一个完全无监督的模型,在提取 NE 和 CC 等有影响力的代币方面。
c)我们开发了一种新颖的形状编码技术,将文档元素编码为少数不同形状的类别,这反过来又反映了它们对生成的摘要的重要性和影响。此外,
d)我们开发了与语言无关的预处理算法,用于词干提取和停用词删除。
二.文献综述及相关工作
自动文本摘要(ATS)可分为三种主要方法: 提取,用于提取要摘要的文本中最有影响力的句子(Rahimi,Mozhdehi,&Abdolahi,2017);抽象依赖于语义来创建由新单词集组成的新代表句子(Alomar、Idris、Sabri 和 Alsmadi,2022);和混合方法(Hsu 等人,2018)。
查看 ATS 的另一种方法是考虑要总结的文本的维度。 ATS 可应用于单文档摘要或多文档摘要,这通常涉及摘要属于同一主题的一组文档,同时保持相关性并避免冗余(Tomer & Kumar,2022)。
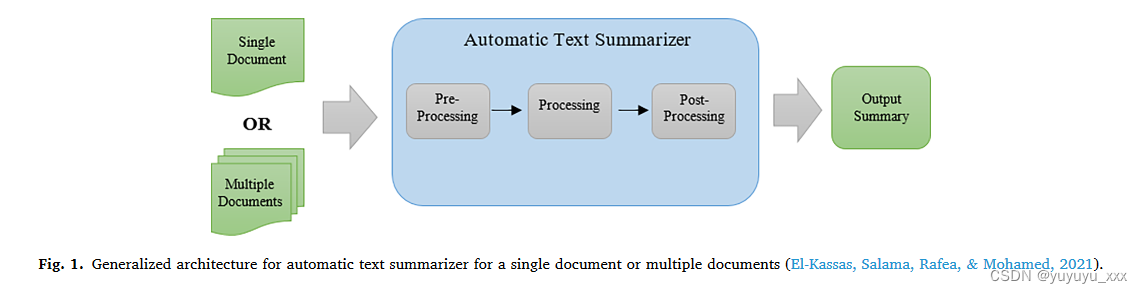
从架构角度来看,El-Kassas、Salama、Rafea 和 Mohamed(2021)将 ATS 分为三个不同的步骤:预处理、处理和后处理,如图 1 所示。其中,预处理步骤(Smelyakov、 et al., 2020)包括句子分割、标记化、词干提取、词形还原(Bergmanis & Goldwater, 2018)、标记(Warjri, Pakray, Lyngdoh, & Maji, 2021)、停用词删除(Kaur & Buttar, 2018)等.虽然处理步骤意味着应用摘要技术本身,但最后,后处理步骤侧重于通过解决问题和面对挑战来完善摘要。另一方面,还开发了基于神经网络的抽象ATS的通用框架。
三.本文方法
四 实验效果
4.1数据集
4.2 对比模型
4.3实施细节
4.4评估指标
4.5 实验结果
4.6 细粒度分析
五 总结
在本文中,提出了一种新颖的文本文档与语言无关的摘要模型(TxLASM),以与语言和领域无关的方式执行提取文本摘要。当针对同一文本的人类生成的摘要进行评估时,TxLASM 会生成高效的语言和领域独立的提取摘要。 TxLASM 使用创新技术对主要文本元素(段落、句子、n-gram 和单词)的特定特征进行编码和提取这些元素的形状。形状编码技术是通过使用一组代码对文本元素进行编码,并对这些形状进行规范化以适应相对较少数量的编码类来执行的。这些类别的丰富/稀有反映了编码标记的重要性程度。所提出的模型不需要任何特定的语言相关的预处理工具,因为它能够消除停用词(不重要的单词)的影响,而无需使用根据定义语言和/或上下文相关的停用词词典。此外,该模型包括一个预处理算法,该算法将单词派生词分组在一起,其步骤与词干提取非常相似,而无需使用语言词典和/或手动编码的词干分析器工具。因此,TxLASM 保留了潜在文本元素的相对重要性,能够提取有影响力的关键短语,而无需任何对语言相关数据库或语料库的某种依赖。 TxLASM 在英语、葡萄牙语、法语和西班牙语编写的新闻数据集上进行了测试。使用 ROUGE-1 和 ROUGE-2 指标根据人类生成的摘要对获得的结果进行评估。就英语和葡萄牙语而言,结果与最近文献中列出的 18 个最先进的模型和系统进行了比较,这些模型代表了 ATS 任务的五个类别。同时,将法语和西班牙语的结果与 Apple macOS 12 集成摘要器以及在线自动摘要器获得的结果进行了比较。
TxLASM 在所有四种语言中都取得了比其他工具更好的性能,而无需使用任何特定领域或语言相关的词典、解析器或语料库,这证明了所提议贡献的质量。这种性能归因于模型能够根据编码形状和形式的稀有性来识别有影响力的术语和文本元素,而不管文本的语言、领域、主题和/或副主题。使用 TxLASM 的未来研究可以解决以下问题:i)扩展模型的边界以解决多个文档摘要任务。 ii) 多文档摘要可以扩展并应用于包含混合语言或上下文的长文本或文档集,例如科学论文和语言书籍。此外,c)扩展模型的应用领域,包括阿拉伯语、波斯语等东方语言。
思考
这篇关于NLP论文阅读记录 - WOS | 2023 TxLASM:一种新颖的与语言无关的文本文档摘要模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






