本文主要是介绍实战 | 某电商平台类目SKU数获取与可视化展示,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、项目背景
最近又及年底,各类分析与规划报告纷至沓来,于是接到了公司平台类目商品增长方向的分析需求,其中需要结合外部电商平台做对比。我选择了国内某电商平台作为比较对象,通过获取最细层级前台类目下的SKU数以及结构占比,找出差异和可提升方向。
我的初步思路是:通过爬虫获取类目名称和链接——>获取SKU数——>可视化展现。
由于这个项目并不需要对商品信息和用户评论信息进行获取,难度比较低,不会遇到强力的反爬机制,因此可以用来日常练手,尤其是对于我这种退出爬虫界很久的同学来说是比较友好,毕竟谁都不想去踩缝纫机对不对(手动狗头)。
二、实现过程
(一)三层级类目及链接获取
下图是该电商平台前台展示的三层级类目。

1. 通过 f12 进入 JS 抓包
可以找到类目的真实地址:「https://dc.3.cn/category/get」,幸运的是返回的数据是 JSON 格式的,这样处理起来就简单了。
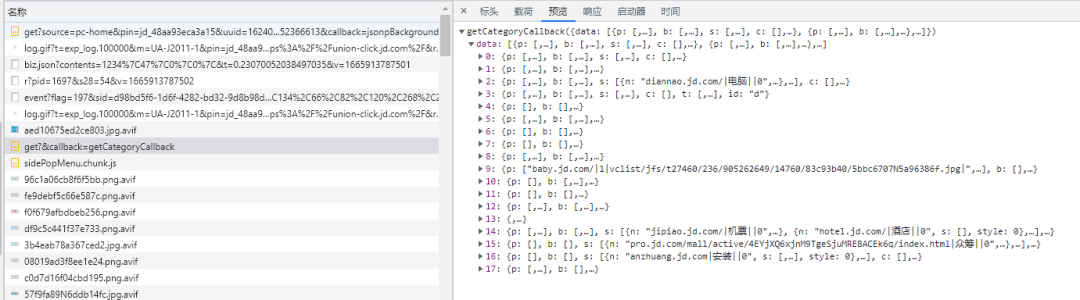

2. 通过观察返回的数据,可以发现一定的规律。
写爬虫就是这样,不断地找规律,仔细核对返回的数据,斗智斗勇的同时会觉得很有挑战乐趣,但也会觉得挺麻烦的。

-
分类信息格式
-
格式1:
-
-
1318-2628-12131|户外风衣||0
-
对应URL: https://list.jd.com/list.html?cat=1318,2628,12131
-
特点: 第一项为分类ID, 包含两个 -
-
-
-
格式2:
-
652-654|摄影摄像||0
-
对应的URL: https://channel.jd.com/652-654.html
-
特点:第一项是频道ID, 包含一个 -
-
-
格式3:
-
jiadian.jd.com|家用电器||0
-
特点: 第一项分类URL,第二项分类名称
-
-
3. 代码实现
import requests
import json
import pandas as pd
import warnings
warnings.filterwarnings('ignore')headers={'Content-Type':'application/json','User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',}url = 'https://dc.3.cn/category/get'
res = requests.get(url,headers=headers)
# 把传递过来的信息GBK进行解码
res.encoding='GBK'
json_data=json.loads(res.text)
# 取出"data" 键中分类列表
categorys = json_data['data']def get_category_item(category_info):# 使用 `|` 分割类型信息字符串categorys = category_info.split('|')# 类别的名称category_name = categorys[1]# 类别的URLcategory_url = categorys[0]# 获取 category_url 中 `-` 个数count = category_url.count('-')if category_url.count('xx.com') != 0:# 其他就是本身就是URL, 前面补一个协议头category_url = 'https://' + category_urlelif count == 1:# 如果包含一个 '-' 是二级分类的频道category_url = 'https://channel.xx.com/{}.html'.format(category_url)else:# 如果包含2个 '-' 是三级分类的列表# 1. 把 `-` 替换为 ','category_url = category_url.replace('-', ',')# 2. 生成具体列表的URLcategory_url = 'https://list.xx.com/list.html?cat={}'.format(category_url)return category_name, category_urlresult = pd.DataFrame()
df = dict()
# 遍历分类列表
for category in categorys:# 获取大分类,包含子分类; 注: 第一层的分类都在在0索引上;b_category = category['s'][0]# 获取大分类信息(分类URL,名称)b_category_info = b_category['n']# 解析大分类信息, 获取大分类名称和URLdf['大分类名'], df['大分类链接'] = get_category_item(b_category_info)# 获取中分类列表m_category_s = b_category['s']# 遍历第二层分类列表for m_category in m_category_s:# 获取中分类信息m_category_info = m_category['n']df['中分类名'], df['中分类链接'] = get_category_item(m_category_info)# 获取小分类列表s_category_s = m_category['s']# 遍历小分类分类列表for s_category in s_category_s:# 获取第三层分类名称s_category_info = s_category['n']# 获取三级分类信息df['小分类名'], df['小分类链接'] = get_category_item(s_category_info)print('{} 已爬取……'.format(df['小分类名']))table = pd.DataFrame.from_dict(df,orient='index').Tresult = pd.concat([result, table])
result.to_excel('./2. 输出类目表.xlsx',sheet_name='result',index=False)
print('爬取成功!!')
(二)小分类下SKU数获取
进入任一级页面,这个平台非常人性化,已经把大致的SKU数放在了页面上,只要通过 xpath 就能直接提取的到啦,轻松写意,直接放代码吧。

import requests
from lxml import etree
import pandas as pd
import time
from alive_progress import alive_bar
import warnings
warnings.filterwarnings('ignore')headers={'Content-Type':'application/json','User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',}df = pd.read_excel('./2. 输出类目表.xlsx',sheet_name='result')
datas=[]
urls = df['小分类链接']
with alive_bar(len(urls)) as bar: for url in urls:res = requests.get(url,headers=headers).textselector = etree.HTML(res)try:sku_count = selector.xpath('//*[@id="J_resCount"]/text()')[0]except IndexError:sku_count = '异常'data = {'url':url,'sku_count': sku_count.strip()}with open('SKU.txt','a') as f:f.write(str(data))datas.append(data)print(data)df_SKU = pd.DataFrame(datas)
df_result = pd.merge(df,df_SKU,left_on='小分类链接',right_on='url',how='inner')
df_result.to_excel('./4. 输出类目SKU原始数据.xlsx',sheet_name='result',index=False)
print('SKU数 爬取完成!!')
(三) 数据清洗
数据拼接完成后,需要对SKU数字段做一些处理。
-
爬取后原始格式
-
格式1:
-
以“万”为结尾
-
需要在原始数据上,去除“+”符号,乘以 10000
-
-
格式2:
-
小分类页面不是商品页,而是返回广告页,没有提供商品SKU数
-
处理成 0
-
-
格式3:
-
正常数据
-
需要在原始数据上,去除“+”符号
-
-
import pandas as pd
import xlwings as xw
import warnings
warnings.filterwarnings('ignore')df = pd.read_excel('./4. 输出类目SKU原始数据.xlsx',sheet_name='result')def transform(a,b):if a == '万':return float(b) * 10000elif a == '异常':return 0else:return float(b)df['基数'] = df['SKU数'].str.findall('[0-9.]').str.join('')
df['单位'] = df['SKU数'].str.findall('[\u4e00-\u9fa5 ;()]').str.join('')
df['转换后SKU数'] = df.apply(lambda x :transform(x['单位'],x['基数']), axis=1)
df = df[['大分类名', '大分类链接', '中分类名', '中分类链接', '小分类名', '小分类链接','转换后SKU数']]
df.to_excel('./6. 输出类目SKU转换后数据.xlsx',sheet_name='result',index=False)app = xw.App(visible=False,add_book=False)
workbook = app.books.open('./6. 输出类目SKU转换后数据.xlsx')for i in workbook.sheets:value = i.range('A1').expand() # 选择要调整的区域value.rows.autofit() # 调整列宽字符宽度value.columns.autofit() # 调整行高字符宽度value.api.Font.Name = '微软雅黑' # 设置字体value.api.Font.Size = 9 # 设置字号大小(磅数)value.api.VerticalAlignment = xw.constants.VAlign.xlVAlignCenter # 设置垂直居中value.api.HorizontalAlignment = xw.constants.HAlign.xlHAlignCenter # 设置水平居中for cell in value:for b in range(7,12):cell.api.Borders(b).LineStyle = 1 # 设置单元格边框线型cell.api.Borders(b).Weight = 2 # 设置单元格边框粗细value = i.range('A1').expand('right') # 选择要调整的区域value.api.Font.Size = 10value.api.Font.Bold = True # 设置为粗体
workbook.save()
workbook.close()
app.quit()print('数据清洗完成!!')
(四)可视化展现
可视化展示的环节,我这次没有选用之前一直使用的 pyecharts,而是使用了 plotly。
主要原因是 plotly 对于 pandas 的支持非常好,它的高级封装函数的写法非常简洁,使用起来方便,而且也能够支持交互和自定义颜色,集美观与实用于一身,应该会成为我今后的主力可视化工具。
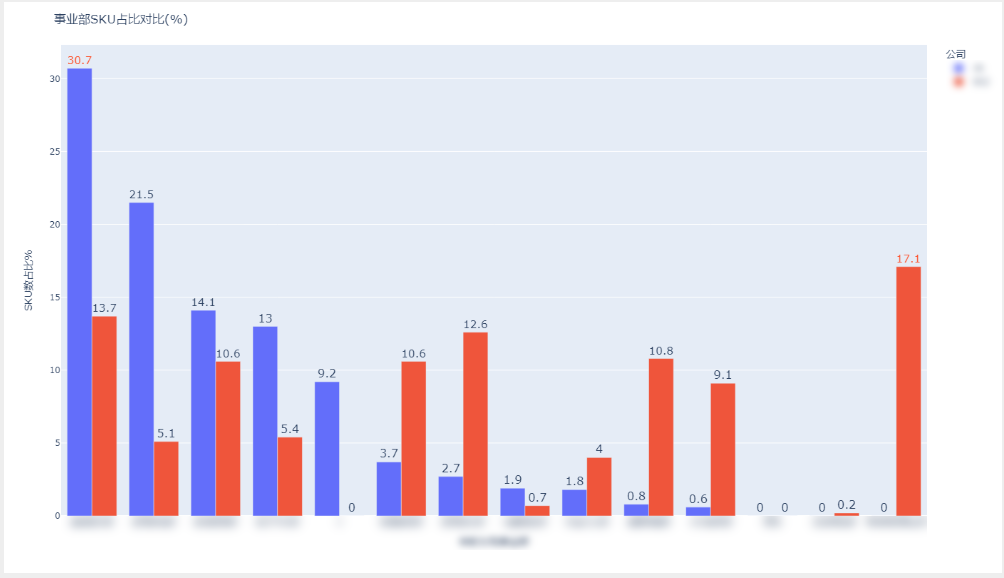
1. 将某平台和我司的类目SKU数占比进行对比
import plotly.io as pio
import plotly.express as px
import plotly.graph_objects as go
import plotly.figure_factory as ff
import pandas as pd
import numpy as npdf1 = pd.read_excel('./6. 输出类目SKU转换后数据.xlsx',sheet_name='result')df_xx = df1.groupby('映射我司事业部')['转换后SKU数'].sum().reset_index().sort_values(by='转换后SKU数',ascending=False)
df_xx['SKU数占比%'] = ((df_xx['转换后SKU数'] / df_xx['转换后SKU数'].sum()) * 100).round(1)
df_xx['公司'] = 'xx'
df_xx = df_JD[['公司','映射我司事业部','转换后SKU数','SKU数占比%']]
df_xx.loc[len(df_xx.index)] = ['xx', '商城商品事业部', 0, 0.0]df2 = pd.read_excel('./【资料】2022年购物公司商品0101-1013.xlsx',sheet_name='Sheet1')
df2 = df2[df2['订购数量']>0]df_yy = df2.groupby('事业部')['商品编号'].count().reset_index().sort_values(by='商品编号',ascending=False)
df_yy['SKU数占比%'] = ((df_yy['商品编号'] / df_yy['商品编号'].sum()) * 100).round(1)
df_yy.rename(columns={'事业部':'映射我司事业部', '商品编号':'转换后SKU数'}, inplace = True)
df_yy['公司'] = 'yy'
df_yy = df_yy[['公司','映射我司事业部','转换后SKU数','SKU数占比%']]
df_yy.loc[len(df_yy.index)] = ['yy', 0, 0, 0.0]
df_yy.loc[len(df_yy.index)] = ['yy', '团购', 0, 0.0]df_concat = pd.concat([df_xx,df_yy])# SKU类目占比对比(柱状图)
fig = px.bar(df_concat, x='映射我司事业部', y='SKU数占比%',barmode='group',color='公司',text='SKU数占比%')
fig.update_layout(title='事业部SKU占比对比(%)')
fig.update_traces(textposition='outside',textfont_size=16,textfont_color=['#FC5531'])
pio.write_html(fig,'事业部SKU占比对比.html')
pio.write_image(fig,'事业部SKU占比对比.png','png',width=1400,height=800)
2. 某平台类目SKU数量结构
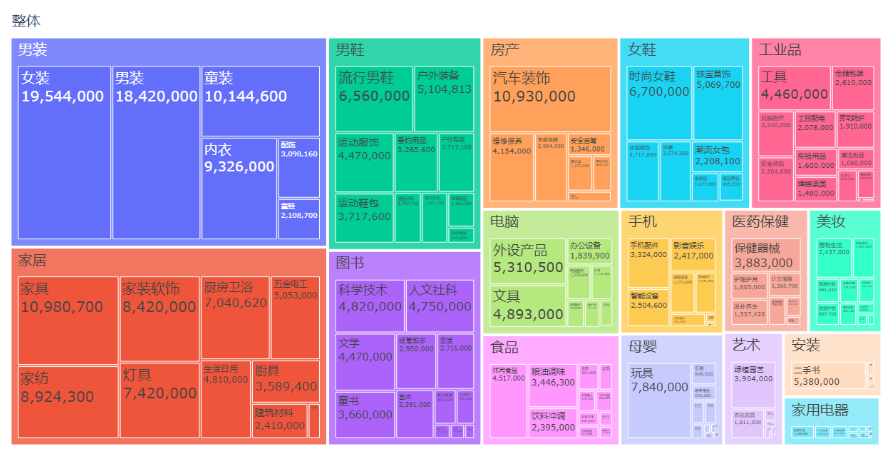
# 树状图
df1['整体'] = '整体'
fig1 = px.treemap(df1, path=['整体', '大分类名', '中分类名'], values='转换后SKU数', title='类目SKU占比树状图',# color='转换后SKU数',# color_continuous_scale='RdBu',# color_continuous_midpoint=df1['转换后SKU数'].mean())
fig1.update_traces(textinfo='label+value',textfont = dict(size = 20))
pio.write_html(fig1,'类目SKU占比树状图.html')
pio.write_image(fig1,'类目SKU占比树状图.png','png',width=1400,height=800)
3. 某平台
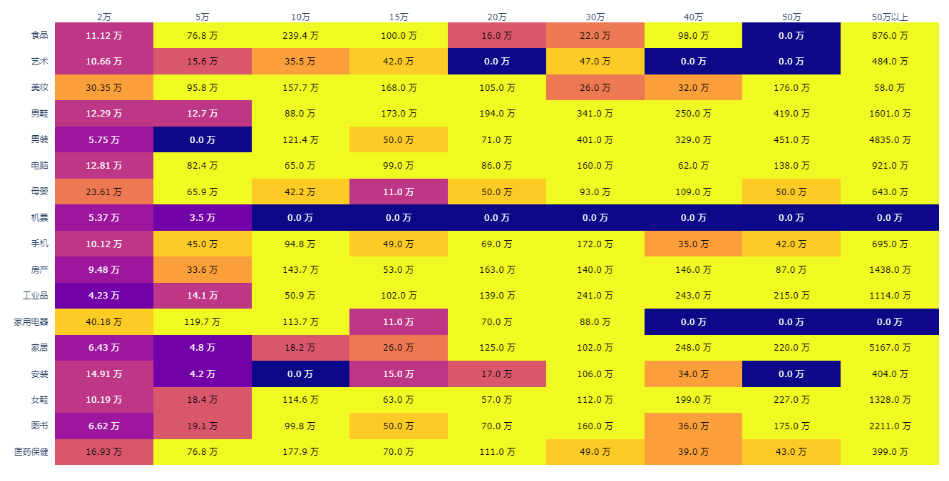
# 热力图
bins = [0,1,20000,50000,100000,150000,200000,300000,400000,500000,99999999999]
groups1 = ['0','2万','5万','10万','15万','20万','30万','40万','50万','50万以上']
groups2 = [.1,.2,.3,.4,.5,.6,.7,.8,.9,1.0]
df1['SKU数级别'] = pd.cut(df1['转换后SKU数'],bins,labels=groups1)
df1['SKU数级别'] = df1['SKU数级别'].fillna('0')data = df1.groupby(['大分类名','SKU数级别'])['转换后SKU数'].sum().reset_index()
data = pd.pivot(data,values='转换后SKU数',index='大分类名',columns='SKU数级别')data2 = data.apply(lambda x:pd.cut(x,bins,labels=groups2))
data2 = data2.fillna(.1)data = data.applymap(lambda x:str(round(x / 10000,2)) + ' 万')data.drop(index='众筹',columns='0',inplace=True)
data2.drop(index='众筹',columns='0',inplace=True)x = list(data.columns)
y = list(data.index)
z = data2.values.tolist()
z_text = data.fillna('').values.tolist()# 自定义色卡
# colorscale = [[0.0,'rgb(0,153,102)'],
# [.1,'rgb(211,207,99)'],
# [.3,'rgb(255,153,51)'],
# [.4,'rgb(204,97,51)'],
# [.5,'rgb(102,0,153)'],
# [1.0,'rgb(126,0,35)']]fig2 = ff.create_annotated_heatmap(z,x=x,y=y,annotation_text=z_text,# colorscale=colorscale)
fig2.update_layout(title='类目SKU占比热力图')
fig2.update_xaxes(side='top')
pio.write_html(fig2,'类目SKU占比热力图.html')
pio.write_image(fig2,'类目SKU占比热力图.png','png',width=1400,height=800)三、可提升方向
以上只是实际工作项目中的一部分,接下来还要对自己公司的数据进行分析,不方便给出更详细的说明,但是本文使用的方法是相通的,不管是对自己公司还是外部平台,都可以按照类似的步骤进行处理、分析与展示。
进行项目的过程中还有一些值得提升的地方,
-
plotly.express 尚未支持多子图的呈现,目前只能使用 plotly.graph_objs 来实现,代码较为繁琐
-
plotly 的很多配置项细节需要梳理和掌握,毕竟才真正接触这个库两三天的时间,来日方长
-
遇到反爬之后,反反爬的成本很高,影响效率,在不花钱的情况下,现在爬虫的 ROI 已经很低,不太值得去做,以我现在的水平有越来越多的网站过不了
-
遇到海量不同口径的数据(比如类目),有什么样的方法能够快速对齐统一,目前还没有头绪,靠人工肯定不现实,数据清洗是真的让人头大啊

数海随记
喜欢作者
这篇关于实战 | 某电商平台类目SKU数获取与可视化展示的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





