本文主要是介绍【Kafka】Leader丢失导致的Consumer挂起故障解决,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
现象
最近发现线上的Kafka Consumer Client频繁出现无法消费的情况,导致offset积压。但是在重启Kafka Broker之后又正常了。 而Cloudera Manager在重启之前,我们发现三台broker中并没有KakfaController。让人很是不解。
排查步骤
检查Topic的状态
目前已经没办法复现当时的场景,我们简单描述下,通过命令
kafka-topics --zookeeper hadoop02 --desc检查Topic的状态如下:
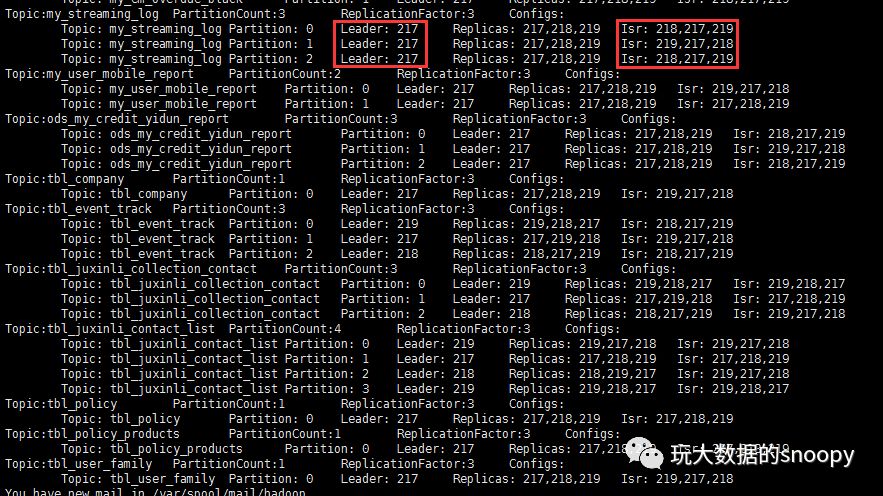
这张图是后续补的,当时的现象是Leader的值均为-1,Isr的值也均为-1
至此我们猜测是因为KakfaController丢失导致的partition leader为-1,进而导致的Consumer端无法正常消费。
查看Leader的选举方式
在这里我们需要先看下KafkaController,KafkaServer.startup()的时候会新建KafkaController,而KafkaController在启动时,启动了Controller的Elector
def startup() = {inLock(controllerContext.controllerLock) {info("Controller starting up");registerSessionExpirationListener()isRunning = truecontrollerElector.startupinfo("Controller startup complete")}
}我们再点进去查看下Controller是怎么elect出来的:
def elect: Boolean = {val timestamp = SystemTime.milliseconds.toStringval electString = Json.encode(Map("version" -> 1, "brokerid" -> brokerId, "timestamp" -> timestamp))leaderId = getControllerID /* * We can get here during the initial startup and the handleDeleted ZK callback. Because of the potential race condition, * it's possible that the controller has already been elected when we get here. This check will prevent the following * createEphemeralPath method from getting into an infinite loop if this broker is already the controller.*/if(leaderId != -1) {debug("Broker %d has been elected as leader, so stopping the election process.".format(leaderId))return amILeader}try {createEphemeralPathExpectConflictHandleZKBug(controllerContext.zkClient, electionPath, electString, brokerId,(controllerString : String, leaderId : Any) => KafkaController.parseControllerId(controllerString) == leaderId.asInstanceOf[Int],controllerContext.zkSessionTimeout)info(brokerId + " successfully elected as leader")leaderId = brokerIdonBecomingLeader()} catch {case e: ZkNodeExistsException =>// If someone else has written the path, thenleaderId = getControllerID if (leaderId != -1)debug("Broker %d was elected as leader instead of broker %d".format(leaderId, brokerId))elsewarn("A leader has been elected but just resigned, this will result in another round of election")case e2: Throwable =>error("Error while electing or becoming leader on broker %d".format(brokerId), e2)resign()}amILeader
}从上面的选举代码中我们可以看出在Kafka集群刚启动时,默认Broker谁先启动则默认为Controller,后续若/controller节点发生变化,会触发Leader变更监听程序LeaderChangeListener,执行变更操作或者重新选举
inLock(controllerContext.controllerLock) {debug("%s leader change listener fired for path %s to handle data deleted: trying to elect as a leader".format(brokerId, dataPath))if(amILeader)onResigningAsLeader()elect
}我们知道kafka消费的时候需要和Leader通信,而Leader不存在导致的没办法消费很容易理解,那么为什么Controller丢失会导致partition的leader不正常呢?我们来看下面一张图片(图片来自CSDN博主:happy19870612):
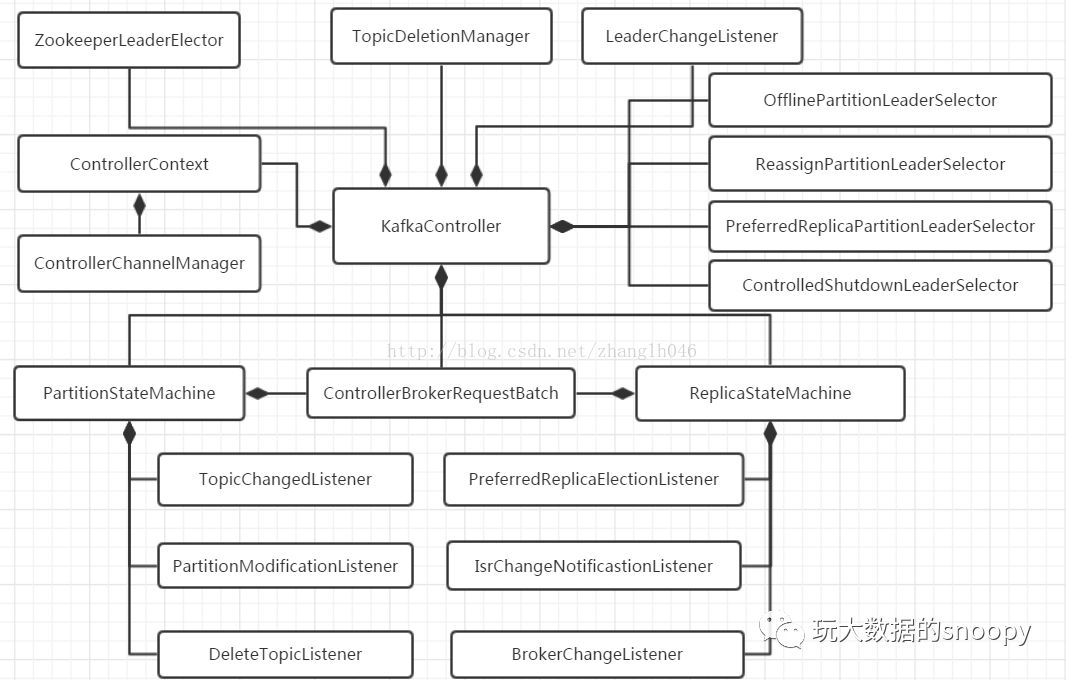
val replicaStateMachine = new ReplicaStateMachine(this)我们可以发现Replica的状态机管理是在KafkaController中完成的,也就是说Controller丢失的情况下,也就失去了与Zookeeper交互的能力。默认情况下Leader必须从ISR列表中选择,我们发现列表为空(经过排查发现是Kafka的bug,在Controller和Zookeeper通信过程中出现问题时,可能导致leader丢失而无法通信的情况,这个可能性是很大的,因为zookeeper在高并发环境是容易超时,这就是为什么在kafka 0.8.2.1之后更建议我们使用kafka topic的方式存储offset而不是存储在zookeeper中。
检查系统日志
当然一般情况下我们会先检查系统日志是否有报异常,这种定位问题效率最高。我们来看看kafka的server log是不是有和zookeeper相关的异常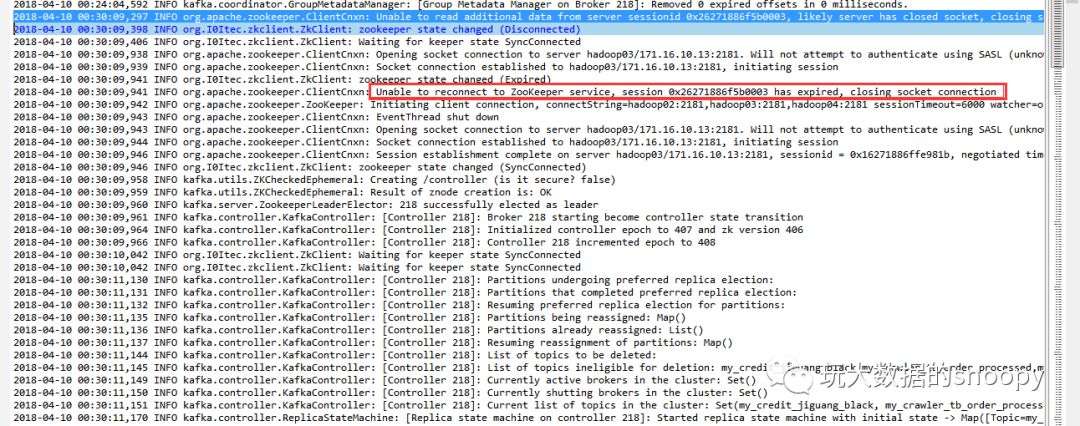
从图上可以发现,的确存在zookeeper连接失败的情况,另外我们发现一个比较诡异的事情:
2018-04-10 00:30:11,149 INFO kafka.controller.KafkaController: [Controller 218]: Currently active brokers in the cluster: Set()所有的broker都临时下线了,然后我查看了其他broker的server log发现所有机器在同一时间均出现了zookeeper连接超时的情况,导致了后续一连串的ERROR: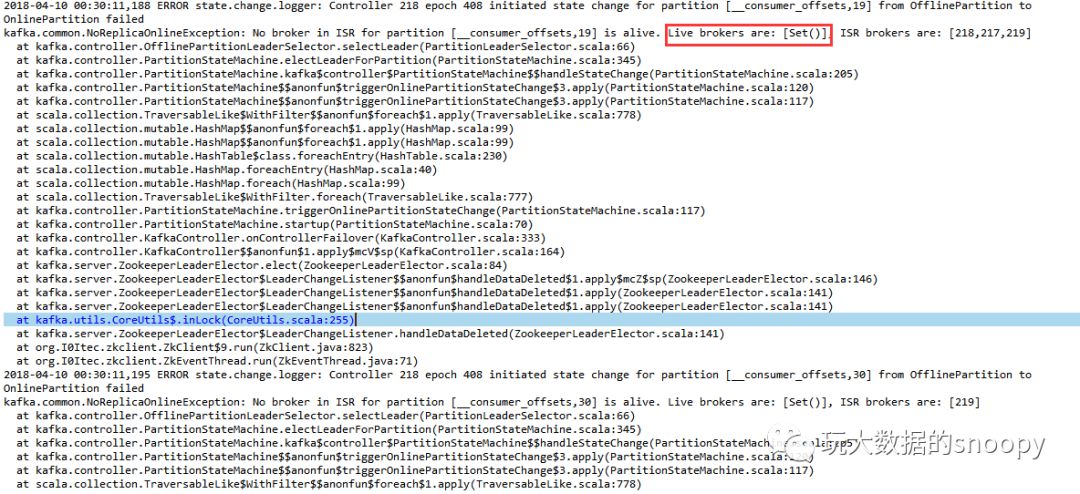
解决方式
那么问题已经很明了了,我们又检查了下凌晨的网络IO: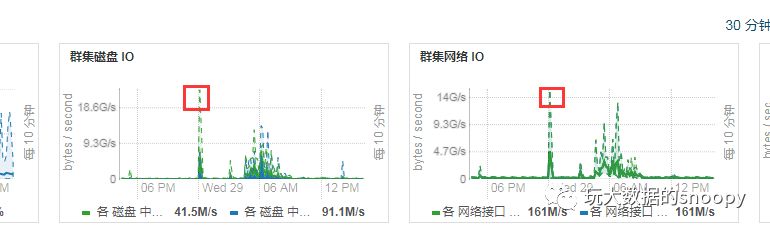
发现凌晨的时候出现了流量高峰。可见主要原因还是当时系统IO压力大导致的连接超时,于是我们适当调大了zookeeper.session.timeout.ms=12,再也没有出现过超时的情况。实际上这是kafka的bug,在0.10版本中已经解决了。另一方面在我们集群中出现这个问题,有一部分原因在于,我们的kafka集群和zookeeper集群是在不同的机房,不同的网络中。在后来的排查中我们发现有一台交换机网口有问题导致的带宽不稳定,特别是在大规模计算的时候尤为明显。
PS:当zookeeper服务器端和客户端版本不一致的时候也会导致连接超时的情况。
这篇关于【Kafka】Leader丢失导致的Consumer挂起故障解决的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








