本文主要是介绍【论文阅读笔记】MobileSal: Extremely Efficient RGB-D Salient Object Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.介绍
MobileSal: Extremely Efficient RGB-D Salient Object Detection
MobileSal:极其高效的RGB-D显著对象检测
2021年发表在 IEEE Transactions on Pattern Analysis and Machine Intelligence。
Paper Code
2.摘要
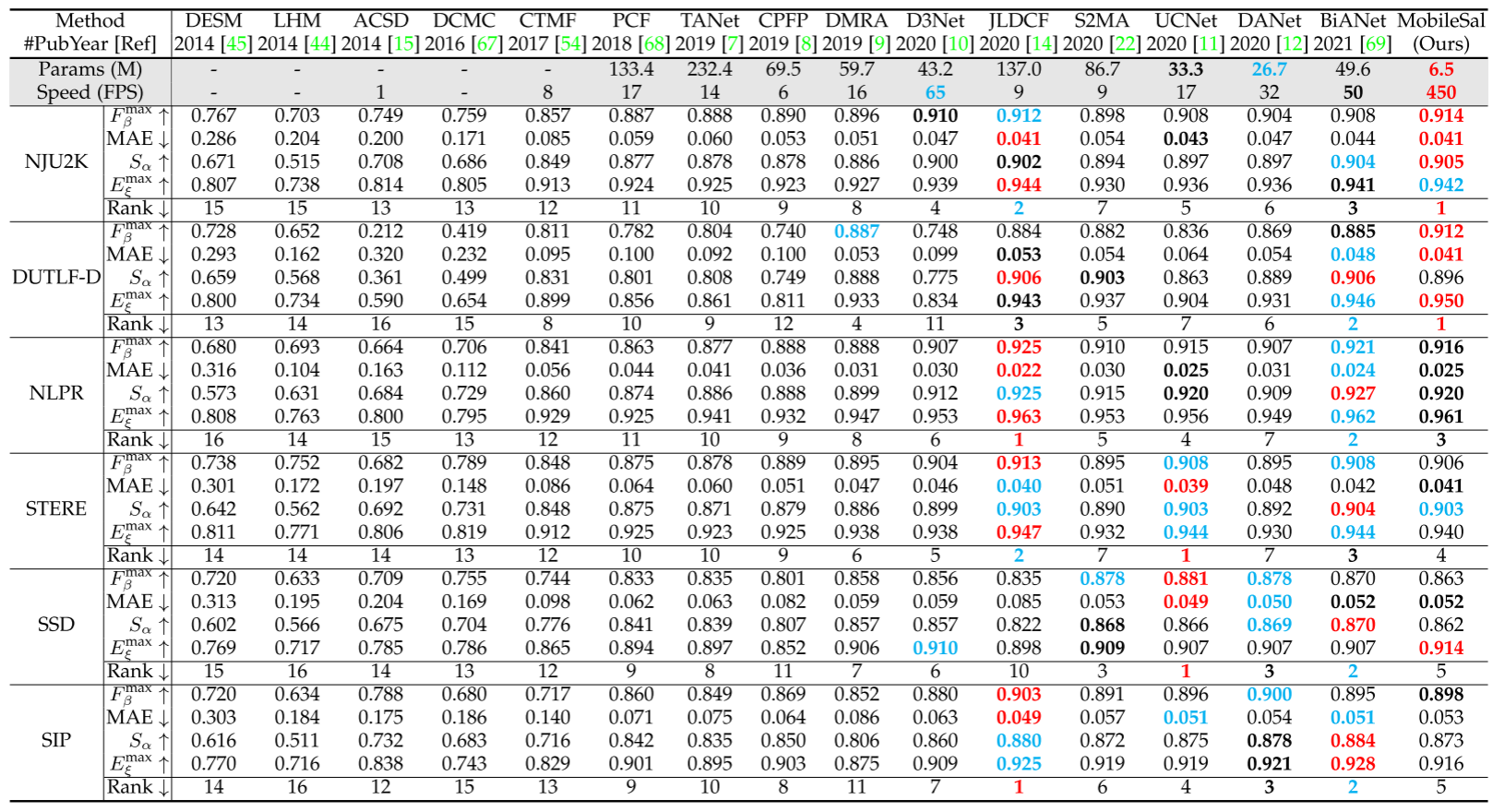
神经网络的高计算成本阻碍了RGB-D显着对象检测(SOD)的最新成功,使其无法用于现实世界的应用。因此,本文介绍了一种新的网络MobileSal,它专注于使用mobile networks进行深度特征提取的高效RGB-D SOD。然而,mobile networks在特征表示方面不如笨重的网络强大。为此,我们观察到,彩色图像的深度信息可以加强与SOD相关的特征表示,如果利用得当。因此,我们提出了一种隐式深度恢复(IDR)技术,以加强mobile networks的RGB-D SOD的特征表示能力。IDR只在训练阶段采用,在测试过程中省略,因此它是计算自由的。此外,我们提出了紧凑的金字塔细化(CPR)高效的多层次特征聚合,以获得清晰的边界显着的对象。通过整合IDR和CPR,MobileSal在六个具有挑战性的RGB-D SOD数据集上与最先进的方法相比表现良好,速度更快(320 × 320的输入大小为450 fps),参数更少(6.5M)。
Keywords:mobile network,深度信息,SOD
3.Introduction
显著目标检测(SOD)的目的是定位和分割自然图像中最引人注目的目标。它是图像理解中的一个基本问题,并且是许多计算机视觉任务的初步步骤,例如视觉跟踪,内容感知图像编辑和弱监督学习。目前的SOD方法主要是针对RGB图像开发的、,这些图像通常受到无法区分的前景和背景纹理的阻碍。虽然卷积神经网络(CNN)在RGB-D SOD上取得了辉煌的成就,但它们的高精度往往是以高计算成本和大模型尺寸为代价的。这种情况已经阻止了最近的最先进的方法被应用于现实世界的应用,特别是对于那些在移动的设备上的应用,这些设备是深度可访问的,具有非常有限的能量开销和计算能力。因此,设计高效的网络以实现精确的RGB-D SOD是至关重要的。实现这一目标的一个简单的解决方案是采用轻量级的主干,如MobileNets和ShuffleNets进行深度特征提取,而不是常用的笨重主干。问题在于,轻量级网络在特征表示学习方面通常不如笨重的网络强大。
为了克服这一挑战,本文指出,如果适当利用彩色图像的深度信息,可以加强RGB-D SOD的特征表示。与一些显式利用深度信息的现有研究不同,本文提出了一种隐式深度恢复(IDR)技术来加强轻量级骨干网络的特征表示学习,以确保RGB-D SOD在有效设置中的准确性。更重要的是,IDR只在训练阶段采用,在测试阶段被省略,因此在推理阶段是计算自由的。具体来说,本文强制模型从高级别骨干网络恢复深度图(生成深度图),通过该特征,轻量级骨干的表示学习变得更加强大,并对深度流进行重要监督。除了IDR模块之外,还提出了另外两个组件来确保高效率:i)仅在粗粒度级别进行RGB和深度信息融合,因为这样小的特征分辨率(即,1/32比例)是降低计算成本的关键; ii)提出了一个紧凑的金字塔细化(CPR)模块,以有效地聚合多尺度深度特征,以获得具有清晰边界的准确SOD。
以MobileNetV2为骨干网络,MobileSal在单个NVIDIA RTX 2080 Ti GPU上实现了450 fps,输入尺寸为320 × 320,NJU 2K [15]和DUTLF [9]数据集上的最大F测量分别为91.4%和91.2%,参数较少(6.5M)。如此高的效率、良好的精度和小的模型尺寸将有利于许多现实世界的应用。
4.模型结构解析
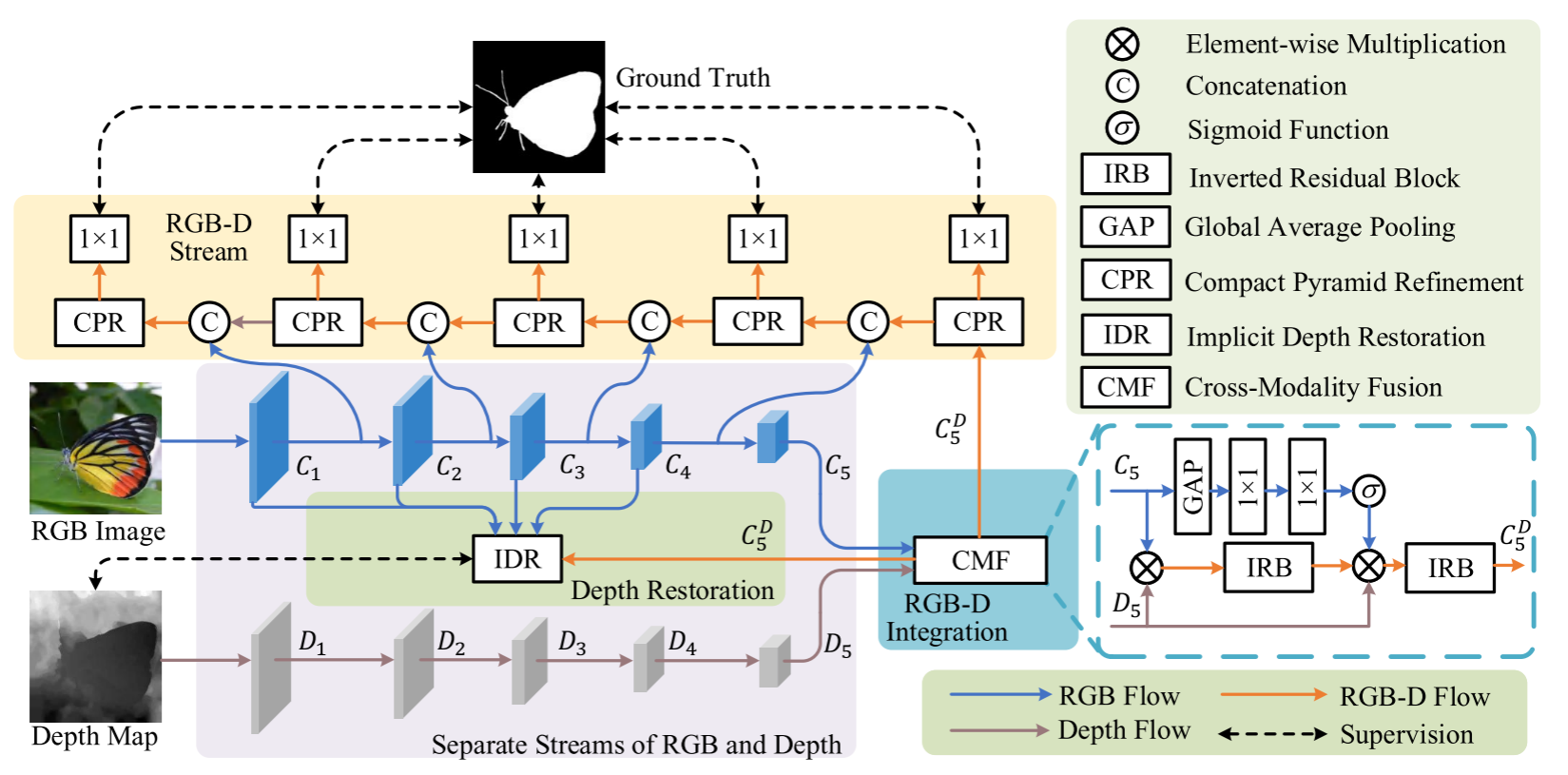
上图是模型整体结构,使用RGB和深度流进行单独的特征提取。
RGB流。采用MobileNetV2作为方法的骨干网络。为了使其适应SOD任务,从骨干中删除了全局平均池化层和最后一个全连接层。对于RGB流,每个阶段之后是步长为2的卷积层,因此特征图在每个阶段之后被下采样为半分辨率。为了方便起见,将五个阶段的输出特征图分别表示为C1、C2、C3、C4、C5,步长分别为2、 2 2 2^2 22、 2 3 2^3 23、 2 4 2^4 24、 2 5 2^5 25。
深度流:与RGB流类似,深度流也有五个具有相同步幅的阶段。由于深度图包含的语义信息比相应的RGB图像少,因此构建了一个轻量级的深度网络,其卷积块比RGB流少。每个阶段只有两个反向残差块(IRB)【MobileNetV2: Inverted residuals and linear bottlenecks】。这样的设计降低了计算复杂度。在每个IRB中,首先通过1 × 1卷积沿通道维度将特征图沿着扩展M倍,然后是具有相同数量的输入和输出通道的深度可分离的3 × 3卷积。然后,通过另一个1×1卷积将特征通道压缩到1/M。在这里,每个卷积后面都是批归一化(BN)和ReLU层,除了最后一个只有BN层的1 × 1卷积。反向残差块的最终输出是初始输入和由上述三个顺序卷积生成的输出的逐元素和。对于每个阶段中的第一层,深度可分离卷积的步幅被设置为2,并且如果需要,隐藏特征通道的数量被增加。深度流的五个阶段的输出特征图被表示为D1、D2、D3、D4、D5,其中前四个阶段分别具有16、32、64、96个通道。D5和C5具有相同的通道数和相同的步幅。
如图所示,利用RGB和深度流的输出,首先融合提取的RGB特征C5和深度特征D5以生成RGB-D特征 C 5 D C^D_5 C5D。所提出的IDR技术从C1、C2、C3、C4、 C 5 D C^D_5 C5D恢复深度图,其由输入深度图监督以加强特征表示学习。对于显著性预测,设计了一个轻量级的解码器使用CPR模块作为基本单元。解码器在底部阶段的输出是最终预测的显著图。更多细节可参见以下章节。
RGB和深度特征的跨模态融合 CMF
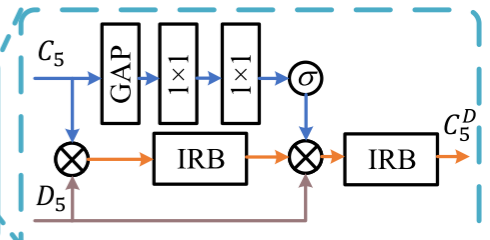
深度图揭示了彩色图像的空间线索,有助于区分前景对象和背景,特别是对于纹理复杂的场景。本文不是在多个级别进行融合,只在粗略级别融合RGB和深度特征,因为小的特征分辨率计算成本低。根据上述分析,仅融合RGB特征图C5和深度特征图D5。为此,设计了一个轻量级的跨模态融合(CMF)模块。直观上,语义信息主要存在于RGB图像中。深度图传达近似表示完整物体或材料的形状和结构的深度平滑区域的先验(深度图传达了对形状和结构完整的物体或材料的近似表示,并且在深度图中存在一些平滑区域,这些区域对应着深度的连续性,形成了一种先验(先验知识或先验信息))因此,采用像门这样的深度特征来通过乘法增强RGB语义特征,这可以被视为一种强正则化。但按元素添加或连接只能通过平等对待特征来聚合两个特征图,这与本文目标正交(不吻合),所以乘了。
具体地,首先将RGB和深度特征通过IRB(反向残差块)组合以获取转换的RGB-D特征图T,其可以被公式化为

其中, ⊗ \otimes ⊗是逐元素乘法运算符。同时,对C5全局平均池化(GAP)以获得特征向量,然后是两个完全连接的层来计算RGB注意力向量v,如:

其中FC和ReLU分别表示全连接层和ReLU层。FC1和FC2的输出通道数与输入相同。σ表示标准sigmoid函数。在计算出T和v的情况下,v、T和D5的乘积被馈送到IRB中,如:

其中 C 5 D C^D_5 C5D是CMF模块的输出特征图。注意,v在乘法之前被复制为与T相同的形状。上式通过乘以D5再次过滤RGB语义特征,并且通道注意力v用于重新校准融合的特征。在RGB和深度特征的融合之后,可以导出骨干特征,包括RGB特征C1、C2、C3、C4和融合的RGBD特征 C 5 D C^D_5 C5D。
隐式深度恢复 IDR

深度图传达了通常表示对象、对象部分或平滑背景的深度平滑区域,因为直观地说,对象或连接的填充区域通常具有相似的深度。所以使用深度图作为指导表征学习的额外监督源,这将有助于mobile networks抑制对象或连接的填充区域内的纹理变化并突出它们之间的差异。通过这种方式,显著对象与背景之间的对比也将得到加强。基于这一思想,设计了一种隐式深度恢复(IDR)技术。在这里,使用“隐式”一词,因为IDR仅在训练阶段采用,在测试期间省略,使其在实际部署中无需计算。
如上图所示,IDR的流水线是简单的,即,只是将多层次的特征图连接起来,然后将它们融合。具体来说,首先应用1 × 1卷积将C1、C2、C3、C4、 C 5 D C^D_5 C5D压缩到相同数量的通道。然后,将得到的特征图调整为与C4相同的大小,然后将它们连接起来。1 × 1卷积将级联特征图从1280通道改变为256通道,以节省计算成本。接下来,四个顺序IRBs之后,融合多层次的功能,使我们可以获得强大的多尺度功能。最后,一个简单的1 × 1卷积将融合后的特征映射转换为单通道。使用标准的sigmoid函数和双线性上采样,可以获得与输入大小相同的恢复深度图。IDR的训练损失采用公知的SSIM度量[65]来测量恢复的深度图Dr和输入的深度图Dg之间的结构相似性,其可以写为
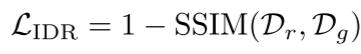
其中,SSIM使用默认设置。请注意,在测试期间省略了上述操作,以使IDR空闲。
紧凑的金字塔细化 CPR
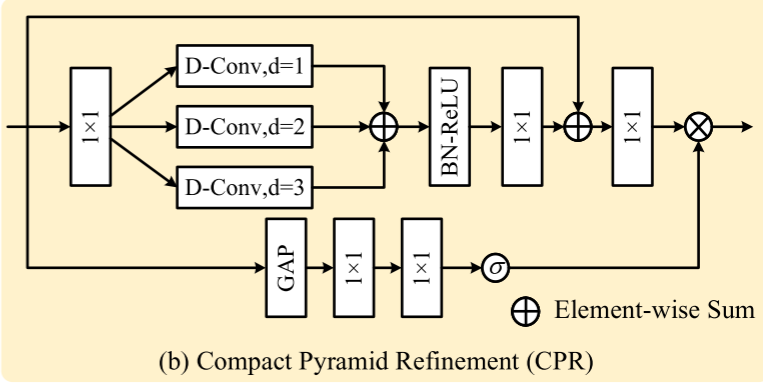
我们的解码器不仅要有效地融合多层次特征,而且要尽可能地高效,即紧凑的金字塔细化(CPR)模块作为基本单元。为了提高效率,CPR使用1×1和深度可分离卷积,而不是以前方法中的vanilla卷积[A single stream
network for robust and real-time RGB-D salient object detection]。由于多层次特征表现出多尺度表示,高层次对应于粗尺度,反之亦然,多尺度学习将是必要的多层次特征融合。因此,CPR采用轻量级的多尺度学习策略来增强这种融合。假设CPR模块的输入是X。如上图所示,CPR首先应用1 × 1卷积以将通道数量扩展M倍。然后,将3个膨胀率分别为1,2,3的3 × 3深度可分卷积并行连接(膨胀率是卷积核内元素之间的间隔。增加膨胀率会导致卷积核内元素之间的距离增加,这可以扩大卷积核的感受野),进行多尺度融合。这可以表述为
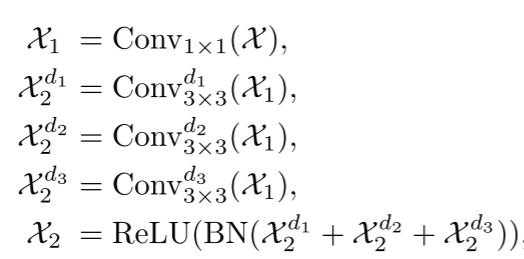
其中d1、d2和d3是膨胀率,即,分别是1,2,3。BN是batch normalization的缩写。1 × 1卷积用于将通道压缩到与输入相同的数量,即,

其使用残差连接以实现更好的优化。注意力机制应用于X以计算注意力向量v’,因此我们有

它使用全局上下文信息来重新校准融合的特征。
如网络结构图所示,在每个解码器阶段,来自顶部解码器和相应编码器阶段的两个特征映射首先分别使用1× 1卷积将其通道数量减少到一半。然后将结果连接起来,然后是用于特征融合的CPR模块。通过这种方式,我们的轻量级解码器从上到下聚合多级特征。
混合损失函数
在每个解码器阶段,我们通过顺序地将具有单个通道的1×1卷积、S形函数和双线性上采样添加到CPR模块的输出来预测显著性图。因此,我们可以分别导出五个阶段的预测显著性图Pi(i = 1,2,…,5)。假设地面实况显著性图为G。每个侧输出的损失可以计算为
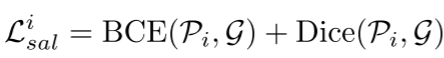
BCE表示二进制交叉熵损失函数:

其中“·”表示点积运算。Dice表示Dice损失: || · ||表示n = 1范数。在深度监督和IDR的情况下,训练损失可以公式化为
|| · ||表示n = 1范数。在深度监督和IDR的情况下,训练损失可以公式化为
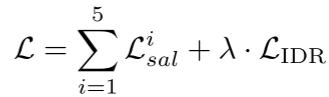
其中λ是平衡权重。在测试阶段,P1是最终预测的显著图。
5.实验结果
我们使用MobileNetV2 作为我们的骨干网。深度流、CPR和IDR中的M值分别被设置为4、4和6。我们将RGB和深度图像调整为320 × 320。我们使用水平翻转和随机裁剪作为消融研究的默认数据增强。在冻结设计和参数之后,我们应用多尺度训练,即,每个图像在训练中被调整为[256,288,320],但我们保持测试图像的大小不变。我们使用单个RTX 2080 Ti GPU进行训练和测试。初始学习率lr为0.0001,批量大小为10。我们训练我们的网络60个epoch。应用多学习率策略,使得每个epoch cur epoch的实际学习率为(1-cur epoch 60)power × lr,其中power为0.9。Adam优化器用于优化我们的网络,动量,权重衰减,β1和β2分别设置为0.9,0.0001,0.9和0.99。

6.总结
轻量化:mobile network提取特征,利用深度图作为辅助监督提高性能,但又不在推理阶段生成深度图进行特征表征,深度图与RGB的特征融合都是轻量化的:只融合高级特征(即分辨率小的),使用反向残差块进行RGBD特征融合。对于最终的不同层次特征进行融合,本文也采用使用1×1和深度可分离卷积,先把通道缩减再操作。
这篇关于【论文阅读笔记】MobileSal: Extremely Efficient RGB-D Salient Object Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







