本文主要是介绍【pywin32】python抽取word/PDF文档文本中转化为txt格式存储,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、环境说明
- 二、安装pywin32
- 三、测试
- 3.1 说明
- 3.2 结果
- 四、说明
- 4.1 注意事项
- 4.2 源码获取
- 五、PDF获取内容到存储到txt格式文本
- 5.1 测试文本说明
- 5.2 实验步骤
- 5.2 结果验证
- 5.3 源码获取
- 2019年11月20日凌晨12点更新
前言
无论是在机器学习、数据挖掘还是深度学习等等,首先要做的就是数据预处理,所以数据预处理这块还是很重要的,因此博主将学习一下关于数据预处理相关的知识。
关于数据预处理的基本概念知识,可查看博主此篇订阅号文章。
一、环境说明
博主所使用的环境是:
1、window10
2、anaconda4.6
3、python3.6
4、pycharm
二、安装pywin32
通过命令:pip install pywin32 安装即可,具体如下图所示 (这里可爱的博主之前安装过所以会有Requirement,相关提示)

安装方法也特别的简单和网上的教程也特别的多,这里就不在一一赘述了。
三、测试
3.1 说明
测试文件:如下图所示(至于里面的内容随便填写奥)

3.2 结果


四、说明
4.1 注意事项
基本没有什么难度,特别要注意的一点就是分割文件名:以下是博主通过fnmatch库获取的绝对路径下的文件名。
def Word2Txt(filePath,savePath=''):# 1、切分文件路径为文件目录和文件名dirs,filename = os.path.split(filePath)print('原始路径:',dirs)print('原始文件名:',filename)# 2、修改切分后的文件后缀new_name = "" #设置一个新的文件名if fnmatch.fnmatch(filename,'*.doc'): # 如果文件名后缀是以docx结尾的,则new_name = filename[:-4] + '.txt' # 截取直到倒数后四位,保留除后四位其余的内容elif fnmatch.fnmatch(filename,'*.docx'):new_name = filename[:-5] + '.txt' # 截取直到倒数后5位,保留除后五位其余的内容else:print('格式不正确,仅支持doc or docx 格式')return
以及获取测试文件路径要格外的注意:以下是我的测试文件存储路径,在pycharm中的一个相关路径
if __name__ == '__main__':filePath = os.path.abspath(r'../dataSet/Corpus/wordtotxt/test_word2.docx') # 获取绝对路径Word2Txt(filePath)# 函数实例化print('word信息抽取到txt格式中完成')
4.2 源码获取
此链接名为wordTotxt.py文件
到此处关于从word中抽取内容到存储到txt格式中就算完成了,接下来将学习关于从PDF中获取内容存储到txt格式中。
五、PDF获取内容到存储到txt格式文本
5.1 测试文本说明
随便准备一个pdf文件,例如,如下就是博主准备的测试文件

5.2 实验步骤
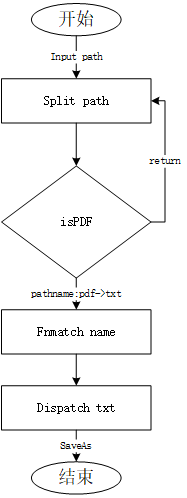
5.2 结果验证


基本和同word文档中抽取内容原理是一样的
5.3 源码获取
https://github.com/jiajikang-nlp/data_preprocess/tree/master/source_code此链接下名为pdf2txt.py文件
2019年11月20日凌晨12点更新
为了将抽取文档信息更为人性化,将多格式的文本信息抽取封装到一起,源码如下所示:
"""author:jjkdatetime:2019/11/19coding:utf-8project name:Pycharm_workstationProgram function: 多格式的文本信息抽取工具
"""import fnmatch,os
from win32com import client as wc
from win32com.client import Dispatch"""
功能描述:抽取多文档文本,默认保存在根目录下,支持自定义
参数描述:1、filePath:文件路径;2、savePath:保存路径
"""def Files2Txt(filePath,savePath=''):# 1、切分文件路径为文件目录和文件名dirs, filename = os.path.split(filePath)print('原文件路径:',dirs)print('原文件名:',filename)# 2、修改切分后的文件名后缀typename = os.path.splitext(filename)[-1].lower() # 切分文件名获取后缀print('typename=',typename)new_name = TranType(filename,typename) # 文件名,文件类型名# 3、设置新的文件保存路径if savePath =='':savePath =dirselse:savePath = savePathnew2txtPath = os.path.join(savePath,new_name)print('新的文件名:',new2txtPath)# 4、加载文本提取的处理程序wordapp = wc.Dispatch('Word.Application') # 启动应用程序mytxt = wordapp.Documents.Open(filePath) # 打开文件路径# 5、保存文本信息mytxt.SaveAs(new2txtPath,4)mytxt.close()"""
功能描述:根据文件后缀修改文件名
参数描述:1、filePath:文件路径;2、typename:文件后缀
返回数据:new_name 返回修改后的新的文件名
"""
def TranType(filename,typename):new_name = ''if typename == '.pdf':# pdf-->txtif fnmatch.fnmatch(filename,'*.pdf'):new_name = filename[:-4] + '.txt'else:returnelif typename == '.doc' or typename == '.docx': # word-->txtif fnmatch.fnmatch(filename,'*.doc'):new_name = filename[:-4] + '.txt'elif fnmatch.fnmatch(filename,'*.docx'):new_name = filename[:-5] + '.txt'else:returnelse:print('警告:您输入【',typename,'】数据不合法,本抽取工具仅支持doc/docx/pdf格式文件,请输入正确格式')returnreturn new_nameif __name__ == '__main__':filePath = os.path.abspath(r'../dataSet/Corpus/wordtotxt/test_word1.docx')Files2Txt(filePath)
源码获取
https://github.com/jiajikang-nlp/data_preprocess/tree/master/source_code此链接下名为extractTxt.py文件
这篇关于【pywin32】python抽取word/PDF文档文本中转化为txt格式存储的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




