本文主要是介绍高级程序员必会的程序设计原则 ——唯一性原则,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
你是否经历过一个项目中存在大量同质化代码,在添加一个小功能时不得不修改全部代码的情况。或者你在调用某个7、8手代码时,列出几十个甚至上百个方法,不知道该调用哪个的情形。如果存在这种情况,那么你所在项目的开发周期一定会非常长,唯一性原则可以从架构和管理的层面保证项目周期和质量。
简记
每一种功能都必须在系统中有唯一并且容易被找到的实现,避免重复代码。每一种定义都必须在文档中有且只有一个明确和权威的解释。
唯一性原则是解决死亡行军项目的良药
唯一性原则要求在系统中的代码应当尽量精简,如果有两端代码实现了相同或类似的功能,应当抽取方法来避免后续维护时反复修改。重复带来的危害显而易见,比如我们有导出Excel文档的功能,但是POI我们没有做二次封装,每一次编写的时候都要重复写一遍转换,这里不仅仅是转换的规则会被编写多次,而且程序员不得不将反复面对POI原生API,增加了记忆和学习负担。
而从文档的角度来讲,以持久化层读取数据为例,如果有DAO.findBy(String column,Object value)、DB.findBy(String column,Object value)、Table.findBy(String column,Object value)三个类,实现相同功能的方法,则会让程序员不知道该调用哪一个API才能实现想要的功能。最有可能出现的场景是,程序员会拿着findBy作为关键字在文档中进行搜索,搜索到哪一个便使用哪一个功能,可DAO要求的column格式必须为“数据源编码.表名称.字段”,DB要求的column格式必须为“表名称.字段”,而Table要求的column格式为“字段”,如果拿到了错误的文档,便会产生时间的浪费和开发周期的延长。
不仅仅开发时要求唯一性,而且在运行时(或运维时)也要保证唯一性。从模型驱动设计角度出发,数据库的设计在代码和文档中应当有确定的定义,如果开发过程中定义了student表有id、name、age三个字段,到生产环境下本来运行的没有问题,但是由于运维过程中客户要求新增字段,于是生硬的加上了duty字段,并且在一个动态系统中注册并展现了这个字段。那么如果开发人员在这种情况下为客户做下一个需求时,修改了student表结构,那么开发人员是不知道duty字段存在的,假如在升级的过程中进行了导出数据->删除旧表->创建新表->导入数据,一定会因为新表中没有duty字段而导致升级失败。而这种失败对于软件和互联网公司而言是致命的。
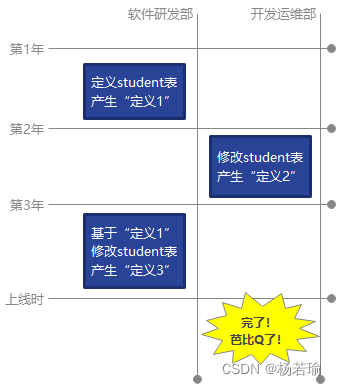
图1、由于未同步,导致未遵循唯一性的后果
所以被要求实现唯一性的代码、关键数据、定义和描述,都应在产品的全生命周期中保持唯一版本。
为了让项目符合唯一性原则,我们可以把有共性的代码抽取成函数、封装成类。或者是我们做一个通用的基类来完成绝大多数的通用功能。如果程序由于某些原因(比如Entity、Repository、Controller在未来要做扩展)而不得不采用多样性设计,那么我们可以将这一部分代码用代码生成的方式实现,并在生成器内部保存文件路径和哈希值,代码生成过程中如果发现哈希值与历史不符,则可以判定是下游使用过程中产生了歧义,可以手动来处理冲突,代码的规范性和生成标准的唯一性都由代码生成器负责。但是因为处理冲突将耗费大量的时间(可能更多的是沟通成本,代码冲突的背后是人与人设计思想的冲突,这解决起来会更耗时),也因此通常不建议考虑大量使用代码生成器来完成工作,代码生成带来的是架构扁平化,而扁平化会使架构设计人员、管理人员更为繁忙,不利于组织的发展。
因此尽管代码生成器所生成的代码符合了纯粹原则,但代码生成器本身并不符合纯粹原则的设计思想。每次重新生成代码便是一次对纯粹原则的挑战,你不得不因此而管理多个版本、多个分支。所以经过深思熟虑之后,既然能用到代码生成器,说明项目的规模并不小,也意味着复杂度是巨大的。折中的方式是仅用生成器来生成定义,而实现保持唯一,同时对插件开放二次开发的接口,这样可以在保证复杂度守恒的前提下尽可能让各个模块分散复杂度,而不是集中在代码生成器上。
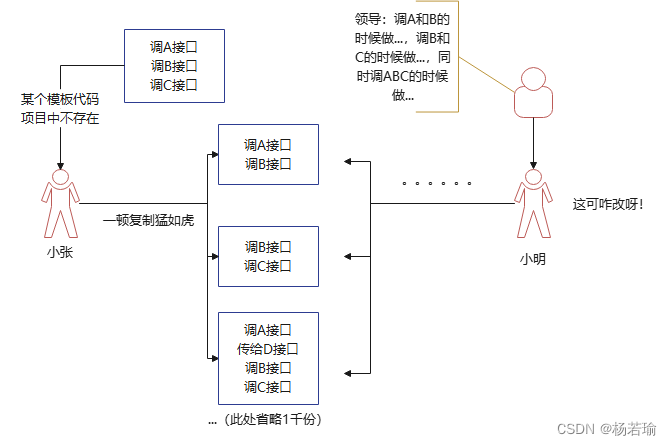
图2、CV工程师的挖坑操作,领导又视而不见的时候
在很多项目上,我们常常可见的是CV工程师在夜以继日的复制粘贴,但这样带来的结果是当你有几百个复制粘贴后并在各自功能上稍作改动的情况下,变量名可能会改,判断逻辑可能会有所不同,你将很难在这些代码里加入一些新的共性功能或修复共性缺陷。
唯一性原则是质量和开发速度的双重保障
我们知道在一个大型项目中,各个程序员的技术栈、背景是不同的,当每个人沿着自己的想法和构思去实现功能时,便会导致软件质量失控,QA对代码进行Review的时候很难去说究竟是谁对谁错:比如前端读取接口,有的人会习惯用jQuery,有的人会用axios,有的人会用XMLHttpRequest。也许会有人说用XMLHttpRequest太落伍了,回到上个世纪了;也许会有人说用jQuery有回调地狱,用Promise的Axios是最佳实践;还会有人说axios没有fetch更底层,一般用用还好。如果每一个类似的技术点都要浪费大量时间去协调、讨论,最后碍于情面把各种实现都保留下来,这时候软件质量将会极其堪忧,真的出现缺陷和事故时,熟悉jQuery的也许不会调axios的BUG,熟悉axios的不会调XMLHttpRequest的BUG。
解决这种争议的有效方法就是让架构师统一封装一个Ajax调用方法,并要求整个项目统一采用这个方法来调用接口,如果有不满足需求的地方,统一向架构师反馈。这里封装的Ajax调用方法便是整个项目符合唯一性原则的权威解释。而作为新加入的组员而言,第一时间是要在代码和文档中找寻这些符合唯一性原则的实现方法,并依赖这些方法进行开发,从而避免从头到尾再踩一遍坑。
如果作为一个开放平台,要允许不同的技术栈融汇在里面,这种架构被称作为各向异性架构,随着开发的推进,每一个领域、每一个模块都会在相同的功能上采用不同特性的实现方式。如果作为一个大型闭合平台,则会唯一指定技术栈和实现方式,这种架构被称作为各向同性架构,随着开发的推进,各个领域和模块在相同的功能上都依赖于相同的实现。
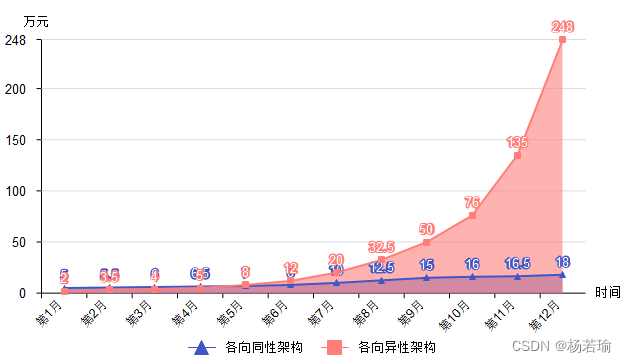
图3、各向同性架构和各向异性架构成本对比
维护各向异性架构的成本和耗时是呈指数级增长,这对于大型互联网开放平台是适用的,因为系统架构的设计者和研发团队并不是具体实现的开发角色,多出的成本可以让ISV承担,从局部来看,每一个团队在其自身的架构实现上呈现的是各向同性;而对于要快速实现某个特定领域项目的团队而言,架构设计和具体实现是同一个团队在做,各向同性架构可以保证成本和耗时呈线性增长。
总结
唯一性原则可以保证软件系统的鲁棒性,并且能有效提升软件开发质量和降低开发周期。其根本目的是在团队和项目内部消除歧义性,用一种能够普适性解决特定问题的方案来替代代码克隆(复制和粘贴)。无论是在推进开发进程、消除缺陷还是降低维护成本方面,都是大有裨益的。
这篇关于高级程序员必会的程序设计原则 ——唯一性原则的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



