本文主要是介绍【Databend】行列转化:数据透视和逆透视,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 数据准备
- 数据透视
- 数据逆透视
- 总结
数据准备
学生学科得分等级测试数据如下:
drop table if exists fact_suject_data;
create table if not exists fact_suject_data
(student_id int null comment '编号',subject_level varchar null comment '科目等级',subject_level_json variant null comment '科目等级json数据'
);
insert into fact_suject_data(student_id, subject_level,subject_level_json) values (12,'china e,english d,math e','{"china": "e","english": "d","math": "e"}');
insert into fact_suject_data(student_id, subject_level,subject_level_json) values (2,'china b,english b','{"china": "b","english": "b"}');
insert into fact_suject_data(student_id, subject_level,subject_level_json) values (3,'english a,math c','{"english": "a","math": "c"}');
insert into fact_suject_data(student_id, subject_level,subject_level_json) values (4,'china c,math a','{"china": "c","math": "a"}');
insert into fact_suject_data(student_id, subject_level,subject_level_json) values (5,'china d,english a,math c','{"china": "d","english": "a","math": "c"}');
insert into fact_suject_data(student_id, subject_level,subject_level_json) values (6,'china c,english a,math d','{"china": "c","english": "a","math": "d"}');
insert into fact_suject_data(student_id, subject_level,subject_level_json) values (7,'china a,english e,math b','{"china": "a","english": "e","math": "b"}');
insert into fact_suject_data(student_id, subject_level,subject_level_json) values (8,'china d,english e,math e','{"china": "d","english": "e","math": "e"}');
insert into fact_suject_data(student_id, subject_level,subject_level_json) values (9,'china c,english e,math c','{"china": "c","english": "e","math": "c"}');
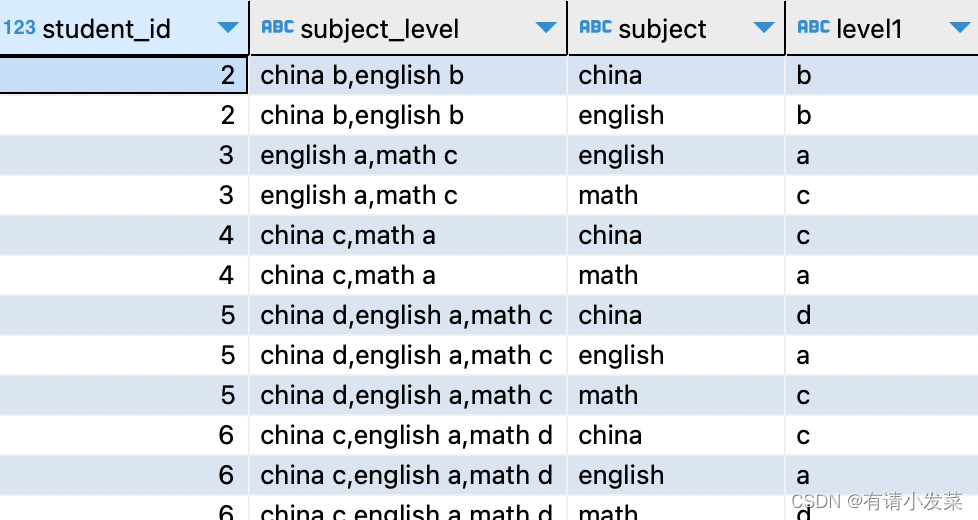
利用上一篇 【Databend】行列转化:一行变多行和简单分列 文章一行变多行,得到如下效果数据:
select t1.student_id, t1.subject_level, split_part(unnest(split(t1.subject_level, ',')), ' ', 1) as subject, split_part(unnest(split(t1.subject_level, ',')), ' ', 2) as level1
from fact_suject_data as t1
order by t1.student_id;
数据透视
Databend 中的 pivot 功能可以轻松实现数据透视,使用语法如下:
select ...
from ...pivot ( <aggregate_function> ( <pivot_column> )for <value_column> in ( <pivot_value_1> [ , <pivot_value_2> ... ] ) )
[ ... ]
参数解释如下:
- <aggregate_function>:用于组合来自 <pivot_column> 的分组值的聚合函数。
- <pivot_column>:将使用指定的 <aggregate_function> 聚合的列。
- <value_column>:其唯一值将成为数据透视结果集中的新列。
- <pivot_value_N>:来自<value_column>的唯一值,将成为透视结果集中的新列。
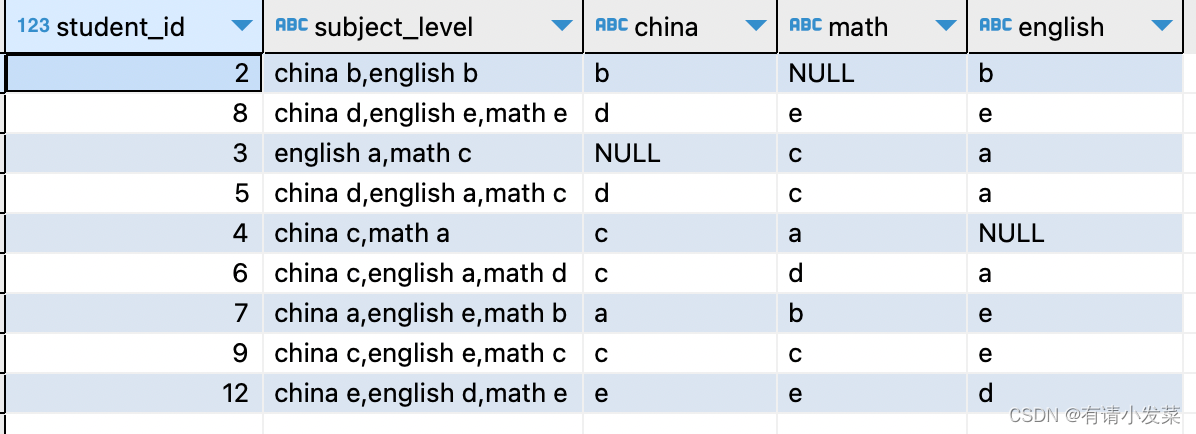
with a as(select t1.student_id, t1.subject_level, split_part(unnest(split(t1.subject_level, ',')), ' ', 1) as subject, split_part(unnest(split(t1.subject_level, ',')), ' ', 2) as level1from fact_suject_data as t1order by t1.student_id)
select *
from a pivot (max(level1) for subject in ('china','math','english'));
数据逆透视
Databend 中 unpivot 功能通过将列转换为行,起到数据逆透视效果。它是一个关系运算符,接受两列(来自表或子查询)以及列列表,并为列表中指定的每列生成一行。使用语法如下:
select ...
from ...unpivot ( <value_column>for <name_column> in ( <column_list> ) )
[ ... ]
参数解释:
- <value_column>:将存储从<column_list>中列出的列中提取的值的列。
- <name_column>:将存储提取值的列名称的列。
- <column_list>:要旋转的列列表,用逗号分隔。
利用数据透视的结果,使用 unpivot 恢复原样实现数据逆透视。
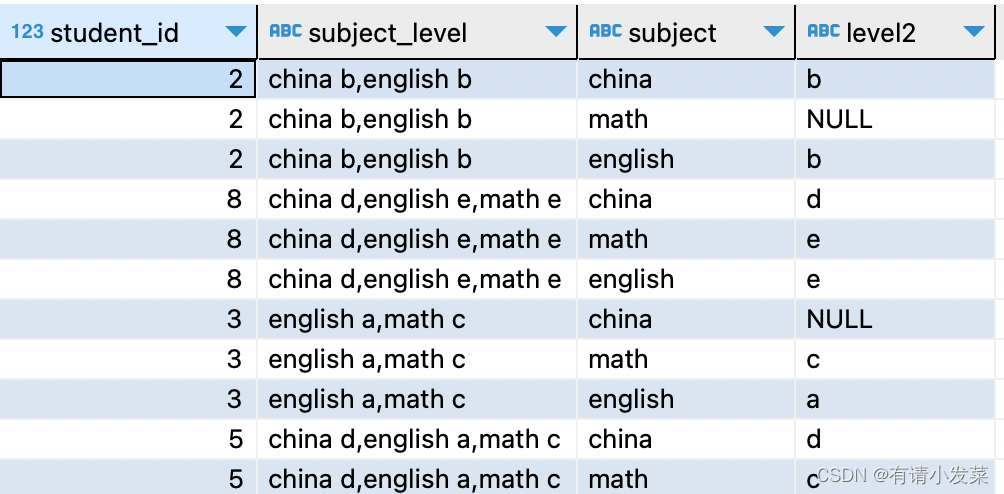
with a as(select t1.student_id, t1.subject_level, split_part(unnest(split(t1.subject_level, ',')), ' ', 1) as subject, split_part(unnest(split(t1.subject_level, ',')), ' ', 2) as level1from fact_suject_data as t1order by t1.student_id),b as(select *from a pivot (max(level1) for subject in ('china','math','english')) )
select *
from b unpivot (level2 for subject in (`china`,`math`,`english`));
总结
Databend 的 pivot 和 unpivot 功能更好地实现数据的透视和逆透视,并且非常易读和分析大量数据,相较于 Mysql 实现数据透视 (case …when…) 和逆透视 (union all) 来说更简单易读,方法不闲多主要是解决实际问题,学习了解更多方法和工具,在面对问题时也能更好的应对,赶紧实操起来,当遇到也能很自信地说“这题我会”。
参考资料:
- Mysql 行列变换《你想要的都有》:https://blog.csdn.net/weixin_50357986/article/details/134161183
- Databend Query Pivot:https://docs.databend.com/sql/sql-commands/query-syntax/query-pivot
- Databend Query UnPivot:https://docs.databend.com/sql/sql-commands/query-syntax/query-unpivot
- Databend 行列转化:一行变多行和简单分列:https://blog.csdn.net/weixin_50357986/article/details/135568736
这篇关于【Databend】行列转化:数据透视和逆透视的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





