本文主要是介绍matlab读取gamit解算的met文件,获取ZTD、ZWD、PWV、ZHD等数据(附matlab代码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0. 码字不易,点赞加关注(公众号:WZZHHH,后期代码将在公众号可以下载),使用请注明出处(根据我的研究方向,我会不断更新代码)。
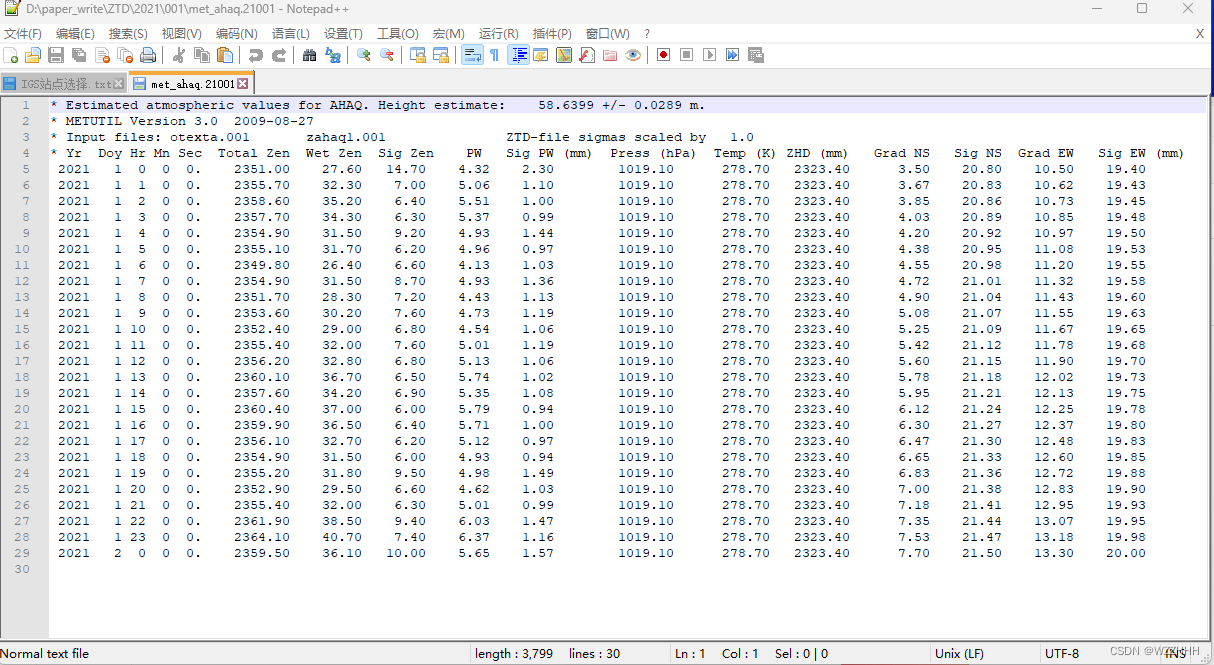
1. 读取gamit解算的met文件,根据前缀met_读取相应文件下met文件,met文件的列分别为1为year、2为doy(年积日)、3为小时、4为分钟、5为秒、6为ZTD、7为ZWD、8不知道、9为PWV、11为气压、12为温度、13为ZHD。
2. 下图为具体的met文件,对照上面列,找到自己需要的。
3. 我按照年积日存放的met文件,存放方式不同的,记得修改代码。我的存放方式如下图。
4. 下面是我的代码,可能没大佬写得好,凑合看吧,能用。
我用的ZTD数据是第六列,其他数据可在第84行更改列即可。
function load_ZTD_file
% 读取gamit解算的met文件
% 我按照年积日存放的met文件
% 存放方式不同的,记得修改
% 根据前缀met—读取相应文件下ztd文件清单,再根据需要更改列
% 我用的ZTD数据是第六列。其他数据可在第84行更改
% met文件的列分别为1为year、2为doy(年积日)、3为小时、4为分钟、5为秒、
% 6为ZTD、7为ZWD、8不知道、9为PWV、11为气压、12为温度、13为ZHD。clc,clear;
% met文件路径,2021年数据为例
ypath = 'D:\paper_write\ZTD\2021\';
% 提取数据后,存放路径
save_path= 'D:\paper_write\paper_code\2\mat\ztd\2021ztddata.mat';
%% ---------------------找到存在met的站点名字---------------------------% 遍历文件夹,看总共有几个站点
ydata = dir(ypath);station = {}; % station 站点
for i=3:size(ydata,1)% 遍历年积日文件夹dpath = [ypath ydata(i).name '\'];ddata = dir(dpath);for ii=3:size(ddata,1)% i=3是第一天,第一天初步建立站点名称if i==3station = [station;{ddata(ii).name(5:8)}];else% 后面增加的站点加入到station中if ~contains(ddata(ii).name(5:8),station)station = [station;{ddata(ii).name(5:8)}];endendendend%% -----------------------------提取gamit解算的met文件------------------% 这个部分本可以和上面合在一起,为了便于理解,,所以分开写ztd_all = {};
parfor i = 3:size(ydata,1)dpath = [ypath ydata(i).name '\'];% 避免文件夹有其他文件,只读取met_开头List = dir(fullfile(dpath,'/','met_*'));for I = 1:size(List,1)% 站点名称stn = List(I).name(5:8);% 读取met文件filename = [dpath,List(I).name];fid = fopen(filename,'r');% 提取met文件的ztdztd = [];% 逐行读取while ~feof(fid)line = fgetl(fid);% 依次读取每行,met文件带*的删除,剩下就是想要的数据if ~contains(line,'*')ztd = [ztd;str2num(line)]; %#ok<ST2NM>endend% 我使用的是1小时时间分辨率% 避免个别时间可能会缺失,缺少数据为nanztd = hours(ztd);fclose(fid);% cellstr:char转cell、num2cell:double转cellstn = repmat(cellstr(stn),24,1);% 第六列是ztd,我只需要这个ztd_all = [ztd_all;[stn num2cell([ztd(:,1:3) ztd(:,6)])]];end
end
% ztd_2:把ztd相同测站放在一起,相同测站按照日期排列更好计算
% ztd_2就是排列好的ztd_all% 按照station名称排列站点数据
ztd = [];
for I =1:size(station)flag = contains(ztd_all(:,1),(station(I,:)));ztd_1 = ztd_all(flag,:);ztd = [ztd;ztd_1];
endsave(save_path,'ztd');
endfunction [ztd] = hours(ztd)
% 25行证明数据齐全,没有的为nan
if size(ztd,1)==25% 第25行为下一天的0时,对其删除ztd = ztd(1:24,:);
else% 年月日时,后面为0的数组ztdz = nan(24,14);yearz = repmat(ztd(1,1:2),24,1);hour = (0:1:23).';ztdz = [yearz hour ztdz];% 将存在的数据进行填充% ztd第3列为小时0-23,把存在数据的小时填充到ztdz中for i=1:size(ztd,1)ztdz(ztd(i,3)+1,:) = ztd(i,:);endztd = ztdz;
endend这篇关于matlab读取gamit解算的met文件,获取ZTD、ZWD、PWV、ZHD等数据(附matlab代码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




