本文主要是介绍Zookeeper使用详解(进阶篇),满满的干货~,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
创作不易,如果觉得这篇文章对你有帮助,欢迎各位老铁点个赞呗,您的支持是我创作的最大动力!
本系列主要总结下Zookeeper的基础使用,笔者准备写四篇文章:
| 博文内容 | 资源链接 |
|---|---|
| Linux下搭建Zookeeper运行环境 | https://blog.csdn.net/smilehappiness/article/details/105933433 |
| Zookeeper入门,一篇就够啦 | https://blog.csdn.net/smilehappiness/article/details/105933292 |
| Zookeeper客户端ZkClient、Curator的使用,史上最详细的教程来啦~ | https://blog.csdn.net/smilehappiness/article/details/105938058 |
Zookeeper使用详解(进阶篇) | https://blog.csdn.net/smilehappiness/article/details/105938119 |
文章目录
- 1 前言
- 2 Zookeeper集群部署
- 2.1 为什么需要集群部署
- 2.2 Zookeeper集群特点
- 2.3 Zookeeper集群角色分工
- 2.3.1 Zookeeper中的事务(非事务)请求
- 2.3.2 Zookeeper集群中的角色
- 2.3.2.1 Leader角色
- 2.3.2.2 Follower角色
- 2.3.2.3 Observer角色
- 2.3.3 Zookeeper集群配置
- 2.3.4 Zookeeper集群配置Observer模式
- 2.3.5 Zookeeper中Observer角色作用
- 3 Zookeeper之ACL
- 3.1 什么是ACL
- 3.2 Zookeeper节点权限模式
- 3.3 Zookeeper节点操作权限
- 3.4 设置Zookeeper节点权限
- 3.4.1 命令行操作方式
- 3.4.1.1 命令行操作第一种方式(推荐)
- 3.4.1.2 命令行操作第二种方式
- 3.4.2 使用代码操作设置节点权限
- 3.4.2.1 设置节点权限
- 3.4.2.2 使用有权限的用户访问
- 3.5 设置Zookeeper节点超级用户权限
- 3.5.1 背景
- 3.5.2 对超级用户的密码加密
- 3.5.3 超级用户加入到服务端启动参数
- 3.5.4 在命令行客户端使用超级用户登陆
- 4 Zookeeper的Leader选举
- 4.1 服务器初始化启动的时候进行Leader选举
- 4.1.1 选举过程分析
- 4.1.2 集群服务状态说明
- 4.2 服务器运行期间的Leader选举
- 5 分布式系统生成全局唯一ID
- 5.1 背景
- 5.2 解决方案
- 5.2.1 UUID方案
- 5.2.2 数据库自增ID方案
- 5.2.3 Redis方案(推荐)
- 5.2.4 基于Twiitter的snowflake算法
- 5.2.5 基于MongoDB的ObjectID
- 5.2.6 基于Zookeeper的方案(推荐)
- 5.2.6.1 通过持久化的顺序节点实现全局唯一Id
- 5.2.6.2 基于Zookeeper节点版本号实现全局唯一Id
- 5.3 小结
- 6 总结
1 前言
上一篇,主要介绍了几种zk客户端的使用,可以方便操作Zookeeper的zNode节点,本文是Zookeeper系列的最后一篇文章了,将主要介绍一些Zookeeper的高级使用,以及一些Zookeeper使用场景的总结,希望对老铁们有所帮助。
2 Zookeeper集群部署
2.1 为什么需要集群部署
Zookeeper作为一个服务,由于网络、机器等原因,服务本身也可能发生故障,所以我们需要将Zookeeper进行集群,避免单点故障问题,以保证zookeeper本身的高可用性;
2.2 Zookeeper集群特点
zookeeper有两种工作的模式,一种是单机方式,另一种是集群方式。
Zookeeper集群特点:
集群中,只要有超过半数的zk集群服务是正常工作的,那么整个集群对外就是可用的。
也就是说如果有2个zookeeper,那么只要有1个故障了,zookeeper就不能用了,因为可用数1没有过半,所以2个zookeeper不是高可用的,因为不能容忍任何1台发生故障。
同理,如果部署了3台zookeeper服务,一个服务故障了,还剩下2个正常的服务,这时候正常的服务2个,超过半数了(1.5),所以3个zookeeper服务才是高可用的,因为能容忍1台服务发生故障。
如果是4台、5台、6台呢?那么分别能容忍1,2,2 台发生故障。
经过一系列推算,得出结论:
Zookeeper服务集群,需要奇数(3,5,7,9…)台服务器实现,太少了不能集群,太多了造成资源浪费。
2.3 Zookeeper集群角色分工
Zookeeper集群有以下三个角色:
一个leader(领导者),一个follower(跟随者),一个observer(观察者),zk服务通过不同的角色,来执行不同的任务。
2.3.1 Zookeeper中的事务(非事务)请求
介绍三个角色之前,先补充两个概念:
- 事务请求
在zk中,那些会改变服务器状态的请求称为事务请求(比如说:创建节点、更新数据、删除节点、创建zk连接会话等等) - 非事务请求
从zk读取数据,但是不对状态进行任何修改的请求称为非事务请求
2.3.2 Zookeeper集群中的角色
2.3.2.1 Leader角色
Zookeeper服务器中Leader是zk集群工作的核心,其主要工作有两个:
- 事务请求的唯一调度者和处理者,保证集群事务处理的顺序性
- 集群内部各个zk服务之间的调度者
2.3.2.2 Follower角色
Follower是Zookeeper集群的跟随者,其主要工作有三个:
- 处理客户端非事务性请求,转发事务请求给Leader服务器(事务请求都由Leader处理)
- 参与事务请求的投票,这里
事务请求的投票指的是Leader事务操作后,会通知所有的Follower服务,只有过半的服务接收成功后,该次Leader的事务操作才有效,也即是保证了数据的一致性 - 参与Leader选举投票
2.3.2.3 Observer角色
Observer充当观察者角色,是一种特殊的跟随者,主要工作:
- 观察zk集群的最新状态变化,并将这些状态同步过来
- 对于非事务请求可以进行独立的处理,对于事务请求,则会转发给Leader服务器进行处理
- Observer不会参与任何形式的投票,包括事务请求的投票和Leader选举的投票
2.3.3 Zookeeper集群配置
一般情况下,业务量不是很大的情况下,配置一台Leader,两台Follow,两台Observer就足够了。
部署3台Zookeeper:
没有安装Zookeeper服务的童鞋们,可以参考本系列文章中的第一节Linux下搭建Zookeeper运行环境进行基础环境的配置。
-
每台zookeeper服务中,conf目录下的zoo_sample.cfg配置文件复制一份,改名为zoo.cfg并配置:
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/usr/local/apache-zookeeper-3.6.1-01/data # the port at which the clients will connect clientPort=2191 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1## Metrics Providers # # https://prometheus.io Metrics Exporter #metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider #metricsProvider.httpPort=7000 #metricsProvider.exportJvmInfo=true#zookeeper内嵌的server服务器的端口,默认是8080 admin.serverPort=3181server.1=localhost:2666:3666 server.2=localhost:2777:3777 server.3=localhost:2888:3888以上配置,比单机版Zookeeper服务,做了以下几个修改:
dataDir=/usr/local/apache-zookeeper-3.6.1-01/data clientPort=2191#zookeeper内嵌的server服务器的端口,默认是8080 #admin.serverPort=3181 (zookeeper从3.5.x版本开始会占用8080端口,通过此配置修改掉默认的8080,避免和tomcat端口冲突) admin.serverPort=3181# 如果是同一台服务器部署三个Zookeeper服务,需要设置不同的端口(2666表示与集群中的Leader服务器交换信息的端口(因为只有一个Leader,所以2666/2777/2888三个端口中,只会有一个端口被占用),3666表示Leader服务宕机时,专门用来进行选举Leader的端口) server.1=localhost:2666:3666 server.2=localhost:2777:3777 server.3=localhost:2888:3888当然了,如果你是在三台Linux机器部署的Zookeeper服务,端口可以重复:
server.1=LinuxOneIP:2666:3666 server.2=LinuxTwoIP:2666:3666 server.3=LinuxThreeIP:2666:3666以上参数说明:
server.A = B:C:D # 可以使用下面的方式表达 server.serverid = serverhost:leader_listent_port:quorum_portA是一个数字,用来表示这个是第几台服务器或者第几台zk服务
B表示这个服务器的ip地址
C表示该端口用于集群成员的信息交换,表示的是该服务器与集群中的Leader服务器交换信息的端口
D是在Leader服务宕机时,专门用来进行选举Leader的端口 -
每台zk服务中,分别创建一个dataDir目录,比如我创建的目录如下(自己根据情况设置即可):
/usr/local/apache-zookeeper-3.6.1-01/data /usr/local/apache-zookeeper-3.6.1-02/data /usr/local/apache-zookeeper-3.6.1-03/data -
每个zk服务的data目录中,都创建一个名为
myid的文件,3个文件的内容写入1、2、3,表示分别对应前边的server.1、server.2和server.3如果你这个dataDir目录下原来运行有产生数据,最好删除一下,否则可能出现未知问题
最后,附上笔者集群测试时的三个zk服务的配置:
dataDir=/usr/local/apache-zookeeper-3.6.1-01/dataclientPort=2191#zookeeper内嵌的server服务器的端口,默认是8080#admin.serverPort=3181 (zookeeper从3.5.x版本开始会占用8080端口,通过此配置修改掉默认的8080,避免和tomcat端口冲突)admin.serverPort=3181# 如果是同一台服务器部署三个Zookeeper服务,需要设置不同的端口(2666表示与集群中的Leader服务器交换信息的端口,3666表示Leader服务宕机时,专门用来进行选举Leader的端口)server.1=localhost:2666:3666server.2=localhost:2777:3777server.3=localhost:2888:3888
dataDir=/usr/local/apache-zookeeper-3.6.1-02/dataclientPort=2192admin.serverPort=3182server.1=localhost:2666:3666server.2=localhost:2777:3777server.3=localhost:2888:3888
dataDir=/usr/local/apache-zookeeper-3.6.1-03/dataclientPort=2193admin.serverPort=3183server.1=localhost:2666:3666server.2=localhost:2777:3777server.3=localhost:2888:3888
至此一个zookeeper的集群就搭建完成。
验证集群:
zk服务启动后,使用以下命令查看服务的状态:
./zkServer.sh status



出现以上截图所示,有一个Leader,两个Follower,说明集群配置成功。
2.3.4 Zookeeper集群配置Observer模式
新部署两台Zookeeper服务,并设置为观察者Observer角色,在任何想变成observer模式的配置文件中加入如下配置:
peerType=observer
另外,在所有其他的zk server的conf配置文件中,配置成observer模式的server的那行配置追加:observer,例如:
peerType=observerserver.1=localhost:2666:3666
server.2=localhost:2777:3777
server.3=localhost:2888:3888
server.4=localhost:2999:3999:observer
现在最终版的zk配置,五台Zookeeper集群服务配置如下:
dataDir=/usr/local/apache-zookeeper-3.6.1-01/dataclientPort=2191#zookeeper内嵌的server服务器的端口,默认是8080#admin.serverPort=3181 (zookeeper从3.5.x版本开始会占用8080端口,通过此配置修改掉默认的8080,避免和tomcat端口冲突)admin.serverPort=3181# 如果是同一台服务器部署三个Zookeeper服务,需要设置不同的端口(2666表示与集群中的Leader服务器交换信息的端口,3666表示Leader服务宕机时,专门用来进行选举Leader的端口)server.1=localhost:2666:3666server.2=localhost:2777:3777server.3=localhost:2888:3888server.4=localhost:2999:3999:observerserver.5=localhost:2901:3901:observer
dataDir=/usr/local/apache-zookeeper-3.6.1-02/dataclientPort=2192admin.serverPort=3182server.1=localhost:2666:3666server.2=localhost:2777:3777server.3=localhost:2888:3888server.4=localhost:2999:3999:observerserver.5=localhost:2901:3901:observer
dataDir=/usr/local/apache-zookeeper-3.6.1-03/dataclientPort=2193admin.serverPort=3183server.1=localhost:2666:3666server.2=localhost:2777:3777server.3=localhost:2888:3888server.4=localhost:2999:3999:observerserver.5=localhost:2901:3901:observer
dataDir=/usr/local/apache-zookeeper-3.6.1-04/dataclientPort=2194admin.serverPort=3184peerType=observerserver.1=localhost:2666:3666server.2=localhost:2777:3777server.3=localhost:2888:3888server.4=localhost:2999:3999:observerserver.5=localhost:2901:3901:observer
dataDir=/usr/local/apache-zookeeper-3.6.1-05/dataclientPort=2195admin.serverPort=3185peerType=observerserver.1=localhost:2666:3666server.2=localhost:2777:3777server.3=localhost:2888:3888server.4=localhost:2999:3999:observerserver.5=localhost:2901:3901:observer
2.3.5 Zookeeper中Observer角色作用
通过以上内容的介绍,可以知道Zookeeper的zNode节点的变更,是要过半数投票通过才可以变更成功(保证数据的一致性),随着机器的添加,因为网络消耗等原因必定导致投票成本增加,从而导致写性能的下降。
Observer是一种新型的Zookeeper节点,能够帮助解决上述问题,提供ZooKeeper的可扩展性。
Observer不參与投票,仅仅是简单的接收投票结果。因此我们添加再多的Observer,也不会影响集群的写性能。
除了这个区别,其它的和Follower基本上一样。
比如:zkClient都能够连接到他们(Observer),而且都能够发送读写请求给他们,收到写请求都会上报到Leader。
Observer优势:
由于它不參与投票,所以他们不属于ZooKeeper集群的关键部位,即使他们Failed宕机了,或者从集群中断开,也不会影响zk集群的高可用性。
3 Zookeeper之ACL
3.1 什么是ACL
访问控制列表(ACL)是一种基于包过滤的访问控制技术,它可以根据设定的条件对接口上的数据包进行过滤,允许其通过或丢弃。访问控制列表被广泛地应用于路由器和三层交换机,借助于访问控制列表,可以有效地控制用户对网络的访问,从而最大程度地保障网络安全。 百度百科
ACL (Access Control List),Zookeeper作为一个分布式协调框架,其内部存储的都是一些关于分布式系统运行时状态的元数据,默认情况下,所有应用都可以读写任何节点,在现如今复杂的网络应用中,这很明显不太安全,任何应用都会有一些用户权限,来保证系统的安全访问,所以,Zookeeper也通过ACL访问控制机制,来解决访问权限问题。
3.2 Zookeeper节点权限模式
Zookeeper节点权限模式,即是Scheme。
开发中,最多使用的有以下四种节点权限模式:
-
ip:ip模式通过ip地址粒度进行权限控制模式,例如配置了:192.168.1.101,即表示权限控制都是针对这个ip地址的(实际开发中用的比较少) -
digest:digest是最常用的权限控制模式,也是开发中用的最多的一种Scheme方式。
该方式采用username:password形式的权限标识进行权限配置,ZK会对形成的权限标识先后进行两次加密处理,分别是SHA-1加密算法和Base64编码 -
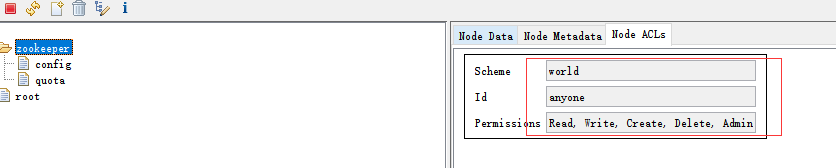
world:world是一种最开放的权限控制模式,也是默认的权限模式,这种模式可以看做特殊的digest,它仅仅是一个标识而已,有个唯一的id。 anyone表示所有人。
-
auth:不使用任何id,代表任何已认证的用户
3.3 Zookeeper节点操作权限
Zookeeper节点操作权限:
权限,就是指那些通过权限校验后,才可以被允许执行的操作,在ZK中,对数据的操作权限分为以下五大类:create,delete,read,write和admin
也就是 增、删、改、查、管理权限,这5种权限简写就是cdrwa(每个单词的首字符缩写)
各权限含义说明:
create:创建子节点的权限delete:删除节点的权限read:读取节点数据的权限write:修改节点数据的权限admin:设置子节点权限的权限
3.4 设置Zookeeper节点权限
3.4.1 命令行操作方式
对命令行操作不熟悉的童鞋们,可以参考我的博文https://blog.csdn.net/smilehappiness/article/details/105933292 5.2节 命令行客户端 脑补一下。
首先需要使用命令行连接Zookeeper:
./zkCli.sh -server ip:2181
如果对节点设置了权限,访问时会没有权限,如:
Authentication is not valid : /root
所以需要以下方式,才能进行节点的操作。
3.4.1.1 命令行操作第一种方式(推荐)
这种方式,是使用明文的方式创建节点用户权限。
在命令行,使用以下命令:
-
创建hello节点:
create /hello -
增加一个认证用户
语法:addauth scheme auth
如:addauth digest zhaoliu:123456789 -
设置权限
语法:setAcl [-s] [-v version] [-R] path acl(setAcl /path auth:用户名:密码明文:权限)
如:setAcl /hello auth:zhaoliu:123456789:cdrwa -
查看Acl设置
语法:getAcl [-s] path
如:getAcl /root
3.4.1.2 命令行操作第二种方式
这种方式,是使用密文的方式创建节点用户权限。
生成密文:
DigestAuthenticationProvider.generateDigest("wangwu:123456")//wangwu:HVn0+DK8rXzHTPwF2BhajA/Cn1M=
在命令行,使用以下命令:
-
创建test节点:
create /test -
设置权限
setAcl /test digest:用户名:密码密文:权限
如:setAcl /test digest:wangwu:HVn0+DK8rXzHTPwF2BhajA/Cn1M=:cdrwa
这里的加密规则是先SHA1加密,然后base64编码 -
使用wangwu用户,明文密码的方式登录
addauth digest wangwu:123456 -
查看Acl设置
语法:getAcl [-s] path
如:getAcl /test
3.4.2 使用代码操作设置节点权限
使用代码的方式,可以在创建节点的时候设置节点权限,也可以修改节点权限的归属,下面,举一些示例,帮助老铁们理解。
3.4.2.1 设置节点权限
开始连接Zookeeper客户端对象时,不设置用户权限,然后通过以下代码设置节点用户访问权限后,再次连接时,就不能访问了(NoAuthException: KeeperErrorCode = NoAuth for /root),此时需要设置权限,才可以连接客户端。
-
在创建节点的时候设置节点权限:
【代码示例】Id zhangsan = new Id("digest", DigestAuthenticationProvider.generateDigest("zhangsan:123456")); Id lisi = new Id("digest", DigestAuthenticationProvider.generateDigest("lisi:654321"));List<ACL> aclList = new ArrayList<>(); //赋值权限(可选值:READ、WRITE、CREATE、DELETE、ADMIN、ALL,即:cdrwa) aclList.add(new ACL(ZooDefs.Perms.ADMIN, zhangsan)); aclList.add(new ACL(ZooDefs.Perms.READ, lisi));//创建节点时,就指定节点所属用户和权限 String node = client.create().creatingParentsIfNeeded().withACL(aclList).forPath(nodePath, data.getBytes()); System.out.println(node); -
修改节点权限的归属:
【代码示例】Id wangwu= new Id("digest", DigestAuthenticationProvider.generateDigest("wangwu:123456")); Id zhaoliu= new Id("digest", DigestAuthenticationProvider.generateDigest("zhaoliu:654321"));List<ACL> aclList = new ArrayList<>(); //赋值权限(可选值:READ、WRITE、CREATE、DELETE、ADMIN、ALL,即:cdrwa) aclList.add(new ACL(ZooDefs.Perms.ALL, wangwu)); aclList.add(new ACL(ZooDefs.Perms.WRITE, zhaoliu));//把ROOT_NODE节点设置两个用户的权限,修改该节点所属用户以及权限 client.setACL().withACL(aclList).forPath(ROOT_NODE);
3.4.2.2 使用有权限的用户访问
上面步骤设置完权限之后,不设置用户,就不能访问到刚才那个节点了
连接zk客户端对象时,需要设置节点用户权限:
/*** <p>* 创建Curator连接对象* <p/>** @param* @return* @Date 2020/6/21 12:29*/public static void connectCuratorClient() {//创建zookeeper连接client = CuratorFrameworkFactory.builder().connectString(ZK_ADDRESS).sessionTimeoutMs(10000).connectionTimeoutMs(15000).retryPolicy(retry)//用户认证.authorization("digest", "zhangsan:123456".getBytes()).build();//启动客户端(Start the client. Most mutator methods will not work until the client is started)client.start();System.out.println("zookeeper初始化连接成功:" + client);}
- 完整代码示例如下:
package cn.smilehappiness.acl;import org.apache.commons.lang3.StringUtils;
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.RetryNTimes;
import org.apache.zookeeper.ZooDefs;
import org.apache.zookeeper.data.ACL;
import org.apache.zookeeper.data.Id;
import org.apache.zookeeper.data.Stat;
import org.apache.zookeeper.server.auth.DigestAuthenticationProvider;import java.security.NoSuchAlgorithmException;
import java.util.ArrayList;
import java.util.List;/*** <p>* Curator客户端ACl权限访问控制* <p/>** @author smilehappiness* @Date 2020/6/21 20:58*/
public class ZookeeperCuratorAcl {/*** 客户端连接地址*/private static final String ZK_ADDRESS = "ip:2181";/*** 客户端根节点*/private static final String ROOT_NODE = "/root";/*** 客户端子节点*/private static final String ROOT_NODE_CHILDREN = "/hello/children";/*** 创建zookeeper连接实例*/private static CuratorFramework client = null;/*** 重试策略* n:最多重试次数* sleepMsBetweenRetries:重试时间间隔,单位毫秒*/private static final RetryPolicy retry = new RetryNTimes(3, 2000);static {// 创建Curator连接对象connectCuratorClient();}/*** <p>* 创建Curator连接对象* 针对设置过权限的节点,需要使用用户登录,否则会没有权限(org.apache.zookeeper.KeeperException$NoAuthException: KeeperErrorCode = NoAuth for /hello/children)* <p/>** @param* @return* @Date 2020/6/21 12:29*/public static void connectCuratorClient() {//创建zookeeper连接client = CuratorFrameworkFactory.builder().connectString(ZK_ADDRESS).sessionTimeoutMs(50000).connectionTimeoutMs(100000).retryPolicy(retry)//用户认证.authorization("digest", "zhangsan:123456789".getBytes()).build();//启动客户端(Start the client. Most mutator methods will not work until the client is started)client.start();System.out.println("zookeeper初始化连接成功:" + client);}public static void main(String[] args) throws Exception {//打印密文//printPwd();//创建节点createNode(ROOT_NODE_CHILDREN, "root data");//使用权限最大的zhangsan用户,把/hello/children节点,给zhaoliu用户设置读的权限,修改该节点所属用户以及权限,这样zhaoliu就可以读取节点了/*Id zhaoliu = new Id("digest", DigestAuthenticationProvider.generateDigest("zhaoliu:123456789"));List<ACL> aclList = new ArrayList<>();//赋值权限(可选值:READ、WRITE、CREATE、DELETE、ADMIN、ALL,即:cdrwa)aclList.add(new ACL(ZooDefs.Perms.READ, zhaoliu));aclList.add(new ACL(ZooDefs.Perms.WRITE, zhaoliu));client.setACL().withACL(aclList).forPath(ROOT_NODE_CHILDREN);*///获取节点数据(zhaoliu只有写的权限,只有zhangsan用户,有所有的权限,可以读写改删)getNode(ROOT_NODE_CHILDREN);//设置(修改)节点数据(lisi用户没有修改权限:NoAuthException: KeeperErrorCode = NoAuth for /hello/children)updateNode(ROOT_NODE_CHILDREN, "update curator data");//删除指定节点(这个在原生zk里面,是不能直接删除有子节点的数据的)deleteNode(ROOT_NODE_CHILDREN);}/*** <p>* 打印密文* <p/>** @param* @return void* @Date 2020/6/21 22:13*/private static void printPwd() throws NoSuchAlgorithmException {System.out.println(DigestAuthenticationProvider.generateDigest("wangwu:123456"));//wangwu:HVn0+DK8rXzHTPwF2BhajA/Cn1M=}/*** <p>* 创建节点,并支持赋值数据内容* <p/>** @param nodePath* @param data* @return void* @Date 2020/6/21 12:39*/private static void createNode(String nodePath, String data) throws Exception {if (StringUtils.isBlank(nodePath)) {System.out.println("节点【" + nodePath + "】不能为空");return;}//对节点是否存在进行判断,否则会报错:【NodeExistsException: KeeperErrorCode = NodeExists for /root】Stat exists = client.checkExists().forPath(nodePath);if (null != exists) {System.out.println("节点【" + nodePath + "】已存在,不能新增");return;} else {System.out.println(StringUtils.join("节点【", nodePath, "】不存在,可以新增节点!"));}//创建节点,并为当前节点赋值内容if (StringUtils.isNotBlank(data)) {List<ACL> aclList = new ArrayList<>();Id zhangsan = new Id("digest", DigestAuthenticationProvider.generateDigest("zhangsan:123456789"));Id lisi = new Id("digest", DigestAuthenticationProvider.generateDigest("lisi:123456789"));Id zhaoliu = new Id("digest", DigestAuthenticationProvider.generateDigest("zhaoliu:123456789"));//赋值权限(可选值:READ、WRITE、CREATE、DELETE、ADMIN、ALL,即:cdrwa)aclList.add(new ACL(ZooDefs.Perms.ALL, zhangsan));aclList.add(new ACL(ZooDefs.Perms.READ, lisi));aclList.add(new ACL(ZooDefs.Perms.WRITE, zhaoliu));//创建节点时,就指定节点所属用户和权限String node = client.create().creatingParentsIfNeeded().withACL(aclList).forPath(nodePath, data.getBytes());System.out.println(node);}}/*** <p>* 获取节点数据* <p/>** @param nodePath* @return void* @Date 2020/6/21 13:13*/private static void getNode(String nodePath) throws Exception {//获取某个节点数据byte[] bytes = client.getData().forPath(nodePath);System.out.println(StringUtils.join("节点:【", nodePath, "】,数据:", new String(bytes)));}/*** <p>* 设置(修改)节点数据* <p/>** @param nodePath* @param data* @return void* @Date 2020/6/21 13:46*/private static void updateNode(String nodePath, String data) throws Exception {//指定版本号,更新节点,更新的时候如果指定数据版本的话,那么需要和zookeeper中当前数据的版本要一致,-1表示匹配任何版本Stat stat = client.setData().withVersion(-1).forPath(nodePath, data.getBytes());System.out.println(stat);}/*** <p>* 删除指定节点* <p>* <p/>** @param nodePath* @return void* @Date 2020/6/21 13:50*/private static void deleteNode(String nodePath) throws Exception {//级联删除节点(如果当前节点有子节点,子节点也可以一同删除)client.delete().deletingChildrenIfNeeded().forPath(nodePath);}}
3.5 设置Zookeeper节点超级用户权限
因为测试的时候,有个/root节点,设置了权限,然后忘记了是哪个用户了,死活就删除不掉了,只能设置一个超级用户权限,来进行节点的操作。
3.5.1 背景
Zookeeper管理员会因为某些客户端对某些节点设置了权限,而导致在紧急的情况下无法修改这些节点感到困扰。在这种情况下,管理员可以通过Zookeeper超级用户模式访问这些节点,一旦设置了超级权限访问节点,使用超级用户登录后,后续的操作就不需要Check ACL了。
使用超级用户模式,可以通过Zookeeper的zookeeper.DigestAuthenticationProvider.superDigest参数开启。
3.5.2 对超级用户的密码加密
使用org.apache.zookeeper.server.auth.DigestAuthenticationProvider生成superDigest:
public void generate() { try { System.out.println(DigestAuthenticationProvider.generateDigest("super:superpw")); } catch (NoSuchAlgorithmException e) { // TODO Auto-generated catch block e.printStackTrace(); }
}
输出super:superpw对应的加密参数为: super:g9oN2HttPfn8MMWJZ2r45Np/LIA=
3.5.3 超级用户加入到服务端启动参数
在zookeeper服务端的zkEnv.sh环境变量中加入以下参数,开启超级用户,重启zookeeper服务端:
SERVER_JVMFLAGS="-Dzookeeper.DigestAuthenticationProvider.superDigest=super:g9oN2HttPfn8MMWJZ2r45Np/LIA= $SERVER_JVMFLAGS"
3.5.4 在命令行客户端使用超级用户登陆
使用客户端登陆到zookeeper服务端:
zkCli.sh -server ip:2181
然后执行命令切换到超级用户:
addauth digest super:superpw
获取Acl设置:
getAcl /root
'digest,'zhangsan:jA/7JI9gsuLp0ZQn5J5dcnDQkHA=: a
'digest,'lisi:c86tNrln9GqhiYsCu/4W34U1vt4=: r
这样就可以删除带有权限控制的节点了:
delete /root 或者 deleteall /root
注意: 这两种方式,都不能删除拥有子节点的那个节点,如果有子节点,必须先删除子节点,再删除父节点。
原文链接:https://www.jianshu.com/p/373d52375a65
4 Zookeeper的Leader选举
Zookeeper集群时,肯定会进行master、follower节点的选择,那么,zk的选举机制是怎么样的呢?
Leader选举是保证分布式数据一致性的关键所在,当Zookeeper集群中的一台服务器出现以下两种情况之一时,会进行Leader选举。
- 服务器初始化启动的时候
- 服务器运行期间无法和Leader保持连接(也即是Leader宕机了)
下面对每种类型的选举进行分析。
注:这里的分析以上边第二节的集群示例进行分析。
4.1 服务器初始化启动的时候进行Leader选举
进行Leader选举的基础条件: 需要有两个及以上的zookeeper,下面以3台机器组成的zookeeper集群为例进行分析。
在集群初始化阶段,当有一台服务器zookeeper1启动时,其单独无法进行Leader选举
当第二台服务器zookeeper2启动时,此时两台机器(超过半数)可以相互通信,每台机器都试图找到Leader,于是进入Leader选举过程,此时即使可以构成集群,但是不是高可用的,因为一旦一台机器挂了,Zookeeper服务就不可用了,至少3台,才可以构成有效的集群。
4.1.1 选举过程分析
-
每个zookeeper服务都会发起一个投票,由于是启动初始化的情况,zookeeper1服务和zookeeper2服务都会将自己作为Leader服务器来进行投票,每次投票会包含所推选的服务器的
myid(集群时创建的myid)和ZXID(全局节点事务id),使用(ZXID,myid)来表示,此时zookeeper1的投票为 (0, 1),zookeeper2的投票为 (0, 2),然后各自将这个投票信息发送给集群中其他机器。 -
集群中的每台服务器收到投票后,首先判断该投票的有效性,如:
检查是否是本轮投票、是否来自LOOKING状态的服务器。 -
处理投票,针对每一个投票,服务器都需要将别人的投票和自己的投票进行PK。
PK规则如下:
优先检查ZXID,ZXID比较大的服务器优先作为Leader(开始的时候ZXID相等,都是0,后续节点被操作后,ZXID会变化)。如果ZXID相同,那么就比较myid,myid大的服务器作为Leader服务器;对于zookeeper1而言,它的投票是 (0, 1),接收zookeeper2的投票为 (0, 2),首先会比较两者的ZXID,初始值相等,ZXID都是0,然后比较myid,此时zookeeper2的myid最大,zookeeper2成为leader,同时每个zookeeper更新自己的投票为 (0,2),
然后重新投票(这里需要看是否过半数,是否有效),对于zookeeper2而言,其无须更新自己的投票,只是再次向集群中所有机器发送上一次投票信息即可。 -
统计投票,每次投票后,服务器都会统计投票信息,
判断是否已经有过半机器接受到相同的投票信息,对于zookeeper1、zookeeper2而言,都统计出集群中已经有两台机器接受了 (0,2) 的投票信息, 此时便认为已经选出了Leader -
改变服务器状态,一旦确定了Leader,每台服务器就会更新自己的状态,如果是
Follower,那么就变更为FOLLOWING,如果是Leader,就变更为LEADING。
4.1.2 集群服务状态说明
-
LOOKING
寻找leader状态,当前服务器处于该状态时,它会认为当前集群中没有leader,因此需要进入leader选举状态 -
FOLLOWING
跟随者状态,表示当前服务器的角色是Follower角色 -
LEADING
领导者状态,表示当前服务器是Leader -
OBSERVING
观察者状态,表示当前服务器角色是Observer
4.2 服务器运行期间的Leader选举
在Zookeeper运行期间,Leader与非Leader服务器各司其职,如果有非Leader服务器宕机或新加入,此时不会影响Leader,但是一旦Leader服务器宕机,那么整个集群将暂停对外服务,进入新一轮Leader选举,其过程和启动时期的Leader选举过程基本一致。
假设正在运行的有zookeeper1、zookeeper2、zookeeper3三台服务器,当前Leader是zookeeper3,若某一时刻Leader宕机了,此时便开始Leader选举,选举过程如下:
-
变更状态,Leader宕机后,余下的服务器都会将自己的服务器状态变更为
LOOKING,然后开始进入Leader选举过程 -
每个zookeeper会发出一个投票,在运行期间,每个服务器上的ZXID可能不同,此时假定zookeeper1的ZXID为100,zookeeper2的ZXID为101。在第一轮投票中,zookeeper1和zookeeper2都会将票投给自己,产生投票(100, 1),(101, 2),然后各自将投票信息发送给集群中的其他机器。
-
接收来自各个服务器的投票,与自己的投票进行PK比较,此过程与启动时相同
-
处理投票,与启动时过程相同,此时(zookeeper2将会成为Leader)
-
再次投票统计投票信息,统计出集群中是否有一半以上的机器接受了(101,2) 的投票信息,这个与始化启动时过程相同
-
改变服务器的状态,与始化启动时过程相同
5 分布式系统生成全局唯一ID
5.1 背景
在大型分布式系统中,我们经常需要生成全局唯一标识,来保证系统单号的唯一性,比如:银行中商户订单号,银行支付接口时唯一编号、红包、优惠券等等。
系统中生成分布式ID的要求:
全局唯一,不能重复(基本要求)- 递增,下一个ID大于上一个ID(有些需求)
- 信息安全,非连续ID,避免恶意用户/竞争对手发现ID规则,从而猜出下一个ID或者根据ID总量猜出业务总量
- 高可用,不能故障,可用性4个9或者5个9(99.99%、99.999%)
- 高QPS,性能不能太差,否则容易造成线程堵塞
- 平均延迟尽可能低
5.2 解决方案
解决方案有很多,本文主要介绍下基于Zookeeper的解决方案,其他的几种,后续有机会再详细介绍。
5.2.1 UUID方案
可以使用UUID的方式,生成全局唯一Id,可以线程安全的。
使用UUID的方法:
UUID.randomUUID()
这种方式虽然可以生成安全的全局唯一Id,但是,也只能满足一般的场景:
- UUID太长,很多场景不适用
- 有些场景希望id是数字的,UUID就不适用(有时候需要全局唯一编号是有序的)
- 可读性不好
5.2.2 数据库自增ID方案
- 数据库自增ID
- 在创建表结构的时候,可以使用auto_increment标识生成自增的主键id(MySQL数据库)
- 可以基于序列,生成自增的主键id(Oracle数据库)
这种方式也是可以的,但是有一些弊端:
- 这种基于数据库的ID生成方案,比较依赖数据库单机的读写性能;(高并发条件下性能不是很好,数据库服务响应慢)
- 对数据库依赖较大,数据库易发生性能瓶颈问题
5.2.3 Redis方案(推荐)
这种方案还是不错的,目前互联网公司使用的还是比较多的,后续会详细介绍这种方案,本文主要还是以Zookeeper为主线,实现全局唯一Id。
简单说下思路:
通过Redis原子操作命令INCR和INCRBY(redis自增)实现递增,同时可使用Redis集群提高吞吐量,集群后每台Redis的初始值为1,2,3,4,5,步长为5
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
5.2.4 基于Twiitter的snowflake算法
https://github.com/twitter/snowflake
这里不详细介绍,有兴趣的童鞋们,可以去看一些,网上有教程,可以百度一下。
5.2.5 基于MongoDB的ObjectID
基于MongoDB,也可以实现,后续有机会,会更新完善下。
5.2.6 基于Zookeeper的方案(推荐)
ZooKeeper作为一个分布式的,开放源码的分布式应用程序协调服务,实现这种全局唯一Id,自然是比较容易的。
基于Zookeeper,大概有两种方案:
- 通过持久化的顺序节点实现
- 通过节点版本号
下面,基于Zookeeper,详细介绍下如何实现全局唯一Id的生成。
5.2.6.1 通过持久化的顺序节点实现全局唯一Id
思路: 每次创建节点时,创建一个带有序列号的,持久化的节点,这样,就可以实现全局惟一的编号。
代码示例如下:
package cn.smilehappiness.generatorID;import com.google.common.util.concurrent.ThreadFactoryBuilder;
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.RetryNTimes;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.data.Stat;import java.util.concurrent.*;/*** <p>* 分布式下,基于Zookeeper生成全局唯一Id(基于Zookeeper序列号,通过持久化的顺序节点实现)* <p/>** @author smilehappiness* @Date 2020/6/21 17:14*/
public class GeneratorIdSequential {/*** 客户端连接地址*/private static final String ZK_ADDRESS = "ip:2181";/*** 创建zookeeper连接实例*/private static CuratorFramework client = null;/*** 客户端根节点*/private static final String ROOT_NODE = "/root";/*** 客户端子节点*/private static final String ROOT_NODE_CHILDREN = "/root/uniqueId/id";/*** 重试策略* n:最多重试次数* sleepMsBetweenRetries:重试时间间隔,单位毫秒*/private static final RetryPolicy retry = new RetryNTimes(3, 2000);static {// 创建Curator连接对象connectCuratorClient();}/*** <p>* 创建Curator连接对象* <p/>** @param* @return* @Date 2020/6/21 12:29*/public static void connectCuratorClient() {//创建zookeeper连接client = CuratorFrameworkFactory.newClient(ZK_ADDRESS, retry);//启动客户端(Start the client. Most mutator methods will not work until the client is started)client.start();System.out.println("zookeeper初始化连接成功:" + client);}private static String idGenerator() throws Exception {Stat stat = client.checkExists().forPath(ROOT_NODE_CHILDREN);//如果节点不存在if (null == stat) {String node = client.create().creatingParentsIfNeeded().withMode(CreateMode.PERSISTENT_SEQUENTIAL).forPath(ROOT_NODE_CHILDREN);//System.out.println("node = " + node);//避免占用zookeeper空间,可以再返回有序节点,并处理完之后,把当前节点删除一下//client.delete().guaranteed().forPath(node);return node.replace(ROOT_NODE_CHILDREN, "");}return null;}/*** <p>* 全局唯一id生成方法测试-单线程* <p/>** @param* @return void* @Date 2020/6/21 18:12*/private static void testGeneratorIdSingle() throws Exception {for (int i = 0; i < 10; i++) {//通过生成器,生成唯一idString uniqueId = idGenerator();System.out.println("uniqueId = " + uniqueId);}}/*** <p>* 全局唯一id生成方法测试-多线程* <p/>** @param* @return void* @Date 2020/6/21 18:30*/private static void testGeneratorIdMultiThread() {//循环次数int count = 10;ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("uniqueId-generator-%d").build();ExecutorService executorService = new ThreadPoolExecutor(4, 2 * 4 + 1, 30, TimeUnit.SECONDS, new LinkedBlockingDeque<>(1000), threadFactory);//设置倒计数器CountDownLatch downLatch = new CountDownLatch(count);for (int i = 0; i < count; i++) {executorService.execute(() -> {try {//通过生成器,生成唯一idString uniqueId = idGenerator();System.out.println("当前线程名称:【" + Thread.currentThread().getName() + "】,生成的全局唯一uniqueId:【" + uniqueId + "】");//每生成一次,就减一downLatch.countDown();} catch (Exception e) {e.printStackTrace();}});}try {downLatch.await();} catch (InterruptedException e) {e.printStackTrace();}System.out.println("全局唯一id生成成功啦...");executorService.shutdown();}public static void main(String[] args) throws Exception {//testGeneratorIdSingle();long startTime = System.currentTimeMillis();testGeneratorIdMultiThread();long endTime = System.currentTimeMillis();System.out.println("耗时:【" + (endTime - startTime) / 1000 + "】秒");}}5.2.6.2 基于Zookeeper节点版本号实现全局唯一Id
思路: 每次为节点赋值的时候,可以拿到Stat对象,通过该对象可以获取节点版本号,这样也可以实现全局唯一Id,因为没操作一次节点,这个版本号也是自增的。(基于当前时间+版本号实现)
【代码示例】
package cn.smilehappiness.generatorID;import com.google.common.util.concurrent.ThreadFactoryBuilder;
import org.apache.commons.lang3.StringUtils;
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.RetryNTimes;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.data.Stat;import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.concurrent.*;/*** <p>* 分布式下,基于Zookeeper生成全局唯一Id(基于Zookeeper版本号实现)* <p/>** @author smilehappiness* @Date 2020/6/21 19:01*/
public class GeneratorIdVersion {/*** 客户端连接地址*/private static final String ZK_ADDRESS = "ip:2181";/*** 创建zookeeper连接实例*/private static CuratorFramework client = null;/*** 客户端子节点*/private static final String ROOT_NODE_CHILDREN = "/root/uniqueId-version";/*** 重试策略* n:最多重试次数* sleepMsBetweenRetries:重试时间间隔,单位毫秒*/private static final RetryPolicy retry = new RetryNTimes(3, 2000);/*** 线程池对象*/private static ThreadPoolExecutor threadPoolExecutor;static {//初始化线程池对象ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("uniqueId-generator-%d").build();threadPoolExecutor = new ThreadPoolExecutor(8, 2 * 8 + 1, 30, TimeUnit.SECONDS, new LinkedBlockingDeque<>(1000), threadFactory);//当前队列任务执行情况ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(1);executor.scheduleAtFixedRate(() -> {System.out.println("任务总线程数:【" + threadPoolExecutor.getTaskCount() + "】");System.out.println("执行完成线程数:【" + threadPoolExecutor.getCompletedTaskCount() + "】");System.out.println("当前活动线程数:【" + threadPoolExecutor.getActiveCount() + "】");System.out.println("当前剩余线程数:【" + threadPoolExecutor.getQueue().size() + "】");}, 1, 2, TimeUnit.SECONDS);// 创建Curator连接对象connectCuratorClient();}public static void main(String[] args) throws Exception {//testGeneratorIdSingle();long startTime = System.currentTimeMillis();testGeneratorIdMultiThread();long endTime = System.currentTimeMillis();System.out.println("耗时:【" + (endTime - startTime) / 1000 + "】秒");}/*** <p>* 创建Curator连接对象* <p/>** @param* @return* @Date 2020/6/21 12:29*/public static void connectCuratorClient() {//创建zookeeper连接client = CuratorFrameworkFactory.newClient(ZK_ADDRESS, retry);//启动客户端(Start the client. Most mutator methods will not work until the client is started)client.start();System.out.println("zookeeper初始化连接成功:" + client);}private static String idGenerator() throws Exception {//如果节点不存在if (null == client.checkExists().forPath(ROOT_NODE_CHILDREN)) {String node = client.create().creatingParentsIfNeeded()//创建持久化节点,可以省略.withMode(CreateMode.PERSISTENT).forPath(ROOT_NODE_CHILDREN);System.out.println("node = " + node);}//基于日期+zk版本号,生成全局唯一IdString DATE_DAY_PATTERN = "yyyyMMdd";String basePrefix = format(new Date(), DATE_DAY_PATTERN);Stat stat = client.setData().withVersion(-1).forPath(ROOT_NODE_CHILDREN);//返回赋值操作节点后,当前节点的版本号return basePrefix + stat.getVersion();}/*** <p>* 全局唯一id生成方法测试-单线程* <p/>** @param* @return void* @Date 2020/6/21 18:12*/private static void testGeneratorIdSingle() throws Exception {for (int i = 0; i < 10; i++) {//通过生成器,生成唯一idString uniqueId = idGenerator();System.out.println("生成的序列号uniqueId = " + uniqueId);}}/*** <p>* 全局唯一id生成方法测试-多线程* <p/>** @param* @return void* @Date 2020/6/21 18:30*/private static void testGeneratorIdMultiThread() {//等待时间final long awaitTime = 10 * 1000;//循环次数int count = 20;//设置倒计数器CountDownLatch countDownLatch = new CountDownLatch(1);for (int i = 0; i < count; i++) {try {Thread.sleep(50);} catch (InterruptedException e) {e.printStackTrace();}//提交线程到线程池去执行(这里可以替换为lambda表达式)threadPoolExecutor.submit(new Runnable() {@Overridepublic void run() {try {//等待,保证所有的线程就位,但是不运行,countDownLatch.await();System.out.println("Thread Name:【" + Thread.currentThread().getName() + "】, current time: " + System.currentTimeMillis());//执行业务代码try {//Thread.sleep(1000);//System.currentTimeMillis()或者i++,++i等多种写法,在多线程环境下生成惟一的Id都是有问题的,所以这里使用zk的版本号作为唯一编号String uniqueId = idGenerator();System.out.println("生成的序列号uniqueId = " + uniqueId);} catch (Throwable e) {System.out.println("Thread:" + Thread.currentThread().getName() + e.getMessage());}} catch (InterruptedException e) {e.printStackTrace();}}});}// countDown()表示倒计算器-1,这里8个线程同时开始执行,那么就可以达到并发效果countDownLatch.countDown();// 关闭线程池的代码try {// 传达完毕信号threadPoolExecutor.shutdown();// 所有的任务都结束的时候,返回TRUE,如果未执行完毕,处于阻塞状态(注意:这里的awaitTime要根据实际情况设置合适的等待时间)if (!threadPoolExecutor.awaitTermination(awaitTime, TimeUnit.MILLISECONDS)) {// 超时的时候向线程池中所有的线程发出中断(interrupted)threadPoolExecutor.shutdownNow();}} catch (InterruptedException e) {// awaitTermination方法被中断的时候,也中止线程池中全部线程的执行,System.out.println("awaitTermination interrupted: " + e);threadPoolExecutor.shutdownNow();}}/*** <p>* 将日期格式化为String* <p/>** @param date* @param pattern* @return java.lang.String* @Date 2020/6/21 19:08*/public static String format(Date date, String pattern) {if (date == null) {return null;} else {if (StringUtils.isBlank(pattern)) {pattern = "yyyy-MM-dd HH:mm:ss";}SimpleDateFormat dateFormat = new SimpleDateFormat(pattern);return dateFormat.format(date);}}/*** <p>* 将日期格式化为Date* <p/>** @param strDate* @param pattern* @return java.lang.String* @Date 2020/6/21 19:08*/public static Date parse(String strDate, String pattern) {if (StringUtils.isBlank(strDate)) {return null;} else {try {return (new SimpleDateFormat(pattern)).parse(strDate);} catch (ParseException var3) {return null;}}}}单线程执行结果:
zookeeper初始化连接成功:org.apache.curator.framework.imps.CuratorFrameworkImpl@754ba872
生成的序列号uniqueId = 2020062111
生成的序列号uniqueId = 2020062112
生成的序列号uniqueId = 2020062113
生成的序列号uniqueId = 2020062114
生成的序列号uniqueId = 2020062115
生成的序列号uniqueId = 2020062116
生成的序列号uniqueId = 2020062117
生成的序列号uniqueId = 2020062118
生成的序列号uniqueId = 2020062119
生成的序列号uniqueId = 2020062120
5.3 小结
以上主要介绍了几种分布式环境下,全局唯一Id的生成方式。详细介绍了基于Zookeeper的方案,其中也使用了两种多线程的方式,来模拟Id的唯一性,以上测试实例说明,在多线程环境下,基于Zookeeper的两种方案,都是可靠的。
6 总结
本系列Zookeeper文章就讲到这里了,后续使用到了再进行补充吧,感谢老铁们的用心阅读,希望对你有所帮助。
写博客是为了记住自己容易忘记的东西,另外也是对自己工作的总结,希望尽自己的努力,做到更好,大家一起努力进步!
如果有什么问题,欢迎大家评论,一起探讨,代码如有问题,欢迎各位大神指正!
给自己的梦想添加一双翅膀,让它可以在天空中自由自在的飞翔!
这篇关于Zookeeper使用详解(进阶篇),满满的干货~的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









