本文主要是介绍【论文阅读】Visual Sentiment Prediction Based on Automatic Discovery of Affective Regions,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

概括
本文尝试去解决在情感分析中所遇到的情感分类和可解释性问题。这里的可解释性主要指图片上哪一区域会影响人类视觉对情感的判断。本文解决这个问题的办法是引入了Affective Region (AR),类似空间注意力的东西。
结合流程图,整体的思路和亮点有两个:
- 弱监督找到AR(建立自动寻找AR的模型),用于定位最容易影响人类视觉判断情感的区域,起到辅助情感分类的作用。【也就是下面的红色虚线框部分】
- 建立情感分类器(采用了求和池化、最大池化、级联三个策略)【红色虚线框以外的部分】

产生候选AR
首先看看作者对AR的描述:
We introduce a new notion named Affective Regions (ARs), which contains two distinguishing characteristics:
1.an AR is a salient region and probably contains one or more objects, which can attract people’s attention, and
2.an AR conveys significant sentiments.

结合图片可以看出,包含不止一个对象的AR最能吸引视线,且最能够反映图片想要传达的情感。图中红框圈起来的部分都是AR,比如(a)中松鼠的笑容让我们一眼能够判断这张图片传递的情感是积极(positive)的。
产生候选AR的时候,有两个要考虑的因素,一是候选框应该覆盖图片中的主要对象,这里需要高召回率,二是只需要有限的候选框来保证准确率。综上,整个步骤包含三步:
1)针对输入图片,用EdgeBoxes产生一组包含对象分数(objectness score,后面记为Obj_score)的边界框(bounding boxes)
2)候选框选择模块,这一步的目的是筛选候选框。

用Fig.4来解释,就是首先过滤太大或者太小的区域(像素小于800的候选框/宽高比大于阈值6);然后如(c)所示,利用normalized cut算法将图片分为m簇(不同的颜色表示不同簇),并计算每簇中的候选框得分W(W为相似性矩阵,指每一对候选框的IoU);最后产生m个候选框。
3)计算AR_score,选出AR
先初始化框架,
再估算候选框情感得分(Senti_score),
最后根据公式计算AR_score,选出得分高的。
初始化框架使用在ImageNet预训练过并用Flickr和Instagram数据集微调过的16层VGGNet,且将fc8分类层改为二分类层,方便预测情感概率。
估算候选框Senti_score,定义了一个概率抽样函数,第i个区域的情感得分(Senti_score):
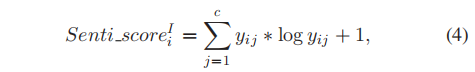
二元分类的得分范围在0到1之间。公式中定义的信息熵表示在预测情绪时的不确定性程度,与传统方法相比,Senti_score可以提供更高级的语义测量。
计算AR_score的时候,利用两个参数Obj_score和Senti_score。前者基于外观估算候选框内包含对象的概率,后者估算情感得分。
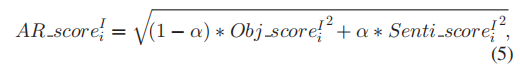
α进行低层和情感层之间的平衡,由对大规模情感数据集的交叉验证来确定。AR_score高的就被认为是AR,用于情感预测,而AR_score低的就被删除。
建立情感分类器
基于初始化的框架,对给定图像的情绪分类可以总结如下。给定一个测试图像,首先生成基于边框的情感候选对象。为了减少冗余性,采用了基于IoU的候选框选择方法,只保留最好的候选框。在选择有可能吸引注意的AR时,同时考虑了Obj_score和Senti_score。然后,对于每个AR和整体图像,由CNN得到一个c维的预测结果,将其融合为最终的预测。作者考虑了三种策略,最大池化、求和池化和级联策略。
实验部分和具体公式内容等:
https://ieeexplore.ieee.org/document/8283764
代码没有公布,暂时只有Github上的Matlab版本:
https://github.com/sherleens/AR_discovery
这篇关于【论文阅读】Visual Sentiment Prediction Based on Automatic Discovery of Affective Regions的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









