本文主要是介绍细品BERT,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Bert时代的创新:Bert应用模式比较及其它
根据几篇相关论文的实验结果,得到一下分析和结论:
1. 对比了特征集成和fine-tuning两种方式的优劣,结论是,在不同的任务上效果是各不相同的。采取Fine-tuning的模式更有可能达到最优效果。
2. 对比了只是用顶层输出和加权平均各个层输出的优劣,结论是:可能跟任务类型有关,不同类型的任务可能结论不太一样,背后可能有更深层的原因在起作用。
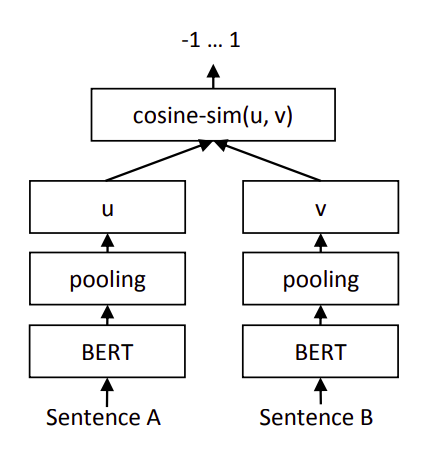
Word2Vec,ELMo,GPT,BERT的演变
Bert最关键两点,一点是特征抽取器采用Transformer;第二点是预训练的时候采用双向语言模型。
"Next Sentence Prediction”: 指的是做语言模型预训练的时候,分两种情况选择两个句子,一种是选择语料中真正顺序相连的两个句子;另外一种是第二个句子从语料库中抛色子,随机选择一个拼到第一个句子后面。我们要求模型除了做上述的Masked语言模型任务外,附带再做个句子关系预测,判断第二个句子是不是真的是第一个句子的后续句子。之所以这么做,是考虑到很多NLP任务是句子关系判断任务,单词预测粒度的训练到不了句子关系这个层级,增加这个任务有助于下游句子关系判断任务。所以可以看到,它的预训练是个多任务过程。这也是Bert的一个创新。
对比试验可以证明,跟GPT相比,双向语言模型起到了最主要的作用,对于那些需要看到下文的任务来说尤其如此。而预测下个句子来说对整体性能来说影响不算太大,跟具体任务关联度比较高。
从模型或者方法角度看,Bert借鉴了ELMO(上下文相关编码,预训练),GPT(Transformer做特征提取器)及CBOW(根据上下文预测当前词),主要提出了Masked 语言模型及Next Sentence Prediction,但是这里Next Sentence Prediction基本不影响大局,而Masked LM明显借鉴了CBOW的思想。
对于当前NLP的发展方向,我个人觉得有两点非常重要,一个是需要更强的特征抽取器,目前看Transformer会逐渐担当大任,但是肯定还是不够强的,需要发展更强的特征抽取器;第二个就是如何优雅地引入大量无监督数据中包含的语言学知识
放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较
一个特征抽取器是否适配问题领域的特点,有时候决定了它的成败,而很多模型改进的方向,其实就是改造得使得它更匹配领域问题的特性。
深度学习的End-to-End优势: 以前研发人员得考虑设计抽取哪些特征,而端到端时代后,这些你完全不用管,把原始输入扔给好的特征抽取器,它自己会把有用的特征抽取出来。
为什么RNN能够这么快在NLP流行并且占据了主导地位呢?主要原因还是因为RNN的结构天然适配解决NLP的问题,NLP的输入往往是个不定长的线性序列句子,而RNN本身结构就是个可以接纳不定长输入的由前向后进行信息线性传导的网络结构,而在LSTM引入三个门后,对于捕获长距离特征也是非常有效的。所以RNN特别适合NLP这种线形序列应用场景
RNN的痛点:RNN本身的序列依赖结构很难具备高效的并行计算能力;(t时刻的输入依赖于t-1时刻的输出)
CNN的痛点:无法捕获长距离特征。(改进方法:1. 窗口里的k个词不连续;2.加深层数,高层的窗口自然就覆盖最底层更多词了,即3*3=9,3*3*3=27)
CNN的pooling会造成位置信息丢失:在NLP领域里,目前CNN的一个发展趋势是抛弃Pooling层,靠全卷积层来叠加网络深度;(或者类似Transformer,把position-embedding引入输入)

Self-Attention和CNN的n是可以并行的,RNN的n不能并行;
考虑了并行的速度:Transformer Base>CNN>Transformer Big>RNN。RNN比前两者慢了3倍到几十倍之间。
语义特征提取能力: Transformer>>CNN=RNN
长距离特征捕获能力: RNN=Transformer>>CNN
任务综合特征抽取能力(以机器翻译为例):Transformer>>CNN=RNN
Transformer对长输入计算量过大的解决办法:可以把长输入切断分成K份,强制把长输入切短,再套上Transformer作为特征抽取器,高层可以用RNN或者另外一层Transformer来接力,形成Transformer的层级结构,这样可以把n平方的计算量极大减少。(Transforme-XL)
Bert时代的创新(应用篇):Bert在NLP各领域的应用进展
搜索引擎的未来,很可能就是QA+阅读理解,机器学会阅读理解,理解了每篇文章,然后对于用户的问题,直接返回答案。
这篇关于细品BERT的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!