本文主要是介绍点击就看新NLP模型如何稳准狠狙击杠精,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


看完《无敌破坏王2:大闹互联网》,资深迪粉的我不禁感慨,我迪自黑和黑起互联网来,也是无人出其右。
不仅深度“曝光”了互联网充斥着木马病毒、弹窗广告、暗网之类的“阴暗面”,一幕热门视频网站“BuzzzTube”所展现的“人间真实”也令人印象深刻:在网络平台上,算法可以让一个普通人成为点赞无数、收入激增的网红,却难以阻挡网友们赠送的“人参”万两。
当拉尔夫在后台惊愕地看到无数负面评价并为之难过时,网站的负责人“赞姐”(Yesss) 也只能建议他——“别看评论区……”
这不就是我们每天都会在网络中围观的大型杠精现场吗?

无论国别、无论次元,只要网上冲浪,就会遇到水军、键盘侠、喷子、杠精……总有一款奇葩网友在线教你做人,社交媒体上的“网怒症”也以指数级增长。
当然,平台们也并非无所作为,只不过,他们似乎总是用不对方法。
比如微博去年就打响了史上最狠评论区保卫战,推出了净化功能“拉黑禁言”,只要评论引发博主不适并被拉黑,乱发言的账号三天内无法再发出任何一条评论。推出后确实震慑到了不少杠精,不过弊端也很明显,那就是依赖网络红人大v博主们一人战杠精,工作量和维护成本也未免也太大了吧?

既然人肉审查效率太低,那采用自动化呢?Youtube和Facebook以实际行动告诉我们,想要让系统精准识别哪些是垃圾账号和恶意行为,实在是做不到啊!
前不久,Facebook一口气删除783个“水军”帐号,原因是存在虚假宣传和舆论攻击行为。其中356个Facebook帐户和162个Instagram帐户,早在2010年就开始在网络任性活动了。但由于他们很容易伪装自己,导致系统根本无法自动清理,最后还是靠手动审查才发现了蛛丝马迹。
看来,想要让机器像人一样精准识别网络行为背后的意图,以当前NLP的阅读理解能力,真的是想太多。
也因此,去年一篇利用人类眼动来提升NLP模型性能的论文,一经问世,就迅速受到关注,为与网络暴力斗智斗勇的程序员们打开了一扇新的技术之窗。
我们不妨就以这个最新研究成果为契机,来猜想一下,技术如何才能打赢这场争夺网络话语权的无声战争。
机器之殇:远不够完美的RNN
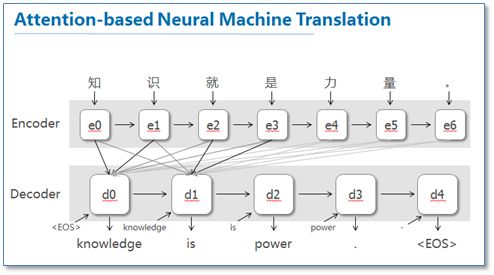
在了解这个新的RNN模型做了哪些创新之前,我想有必要先简单介绍一下,NLP的世界里一般是如何使用注意力机制来完成任务的。
以最为常用的序列对序列(sequence to sequence)模型为例,比如说我们要将中文翻译成英文,如果我们拥有大量的双语语料,就可以得到两个知识丰富而结构相似的编码和解码网络,从而训练出很有效的模型,来实现很好的机器翻译效果。
但序列模型对机器的记忆力提出了比较残酷的要求,需要先背诵全文再翻译,如果是长篇大论,机器就放飞自我了。
于是,注意力模型出现了。
试想一下,人类是如何翻译的(此处致敬高考英语老师):先完整地读完整个句子,结合上下文理解大概含义,然后对关键单词和短语重点思索,再着手进行翻译。
而注意力模型试图模仿的正是人类这种理解能力。它被设计成一个双向的RNN网络,每个单元由LSTM或GRU组成,能够向前和向后获取信息,通俗点说就是“联系上下文”。
每次翻译时,注意力模型会根据待翻译部分以及上下文,给予不一样的注意力(权重参数),接着循序渐进地翻译出整段话。
注意力机制解决了传统神经机器翻译中基于短语的生搬硬套,但并不意味着毫无缺陷。
它的不完美主要体现在三个方面:
1.需要大规模标注数据。
原始RNN在解码过程中,机器的焦点是分散在整个序列当中的,需要先对序列上的每个元素进行标记,再进行对齐操作。里面就包含了词性标注、CHUNK识别、句法分析、语义角色识别,甚至包括关键词抽取等很多子任务,显然不是一个小工程。
2.增加额外运算负担。
人类在阅读时,并不关注所有的字,往往会自动忽略掉不想关注或无意义的部分,只重点处理关注需要注意的那一部分。比如“Courage is like a muscle”中,“Courage”和“muscle”就会让人多看两眼。这样做不仅能够降低任务的复杂度,还能避免脑负荷过载。
而NLP的注意力机制虽然是在模仿人类行为,但机器必须对所有对象进行处理和计算,还要用一个矩阵去存储不同字节的权重,这些都增加了额外的运算压力和成本。
3.容易出现归纳偏置。
通俗点说,就是机器在遇到某种没有见过的东西时,会倾向于给出一个简单的预测或判断,以此来决定输出规则。
比如通过分析,它认为出现“but”“不”等单词,就说明对方会开始释放负面甚至攻击性的语言了。但要是遇上“我跳起来反手就是一个么么哒”之类玩梗的骚操作,可能就会误伤友军。
了解了注意力机制的基本工作方式,我们就赶紧来看看这项新的研究成果,究竟是凭什么惊艳了整个学界吧。
NLP希望之钥,还掌握在人类手中
一句话概括,就是论文作者Maria Barrett和她的同事们,将人类在阅读时的眼部动作引入了RNN网络的训练中,使其能够在标注型文本和人类注意力信息之间来回切换,以此获得性能更好的循环神经网络。
具体是怎么实现的呢?
首先,研究人员利用两个公开的眼动追踪语料库:Dundee Corpus和ZuCo Corpus来研究人类的注意力机制。
其中,Dundee Corpus包含了20篇报纸文章,共2368个句子,阅读屏幕可以感知眼部动作。ZuCo Corpus则包含了1000个单独的英语句子,有一部分来自斯坦福情感树库,通过红外染色仪来记录眼睛运动和面部情绪分析。
根据这些人类阅读语料时的眼睛动作追踪数据(比如注视持续时间MEAN FIX DUR),得到了一个“人类注意力”的数据集。
第二步,使用人类眼动数据集与标注好的序列数据集,来共同训练RNN模型。
从两个数据集中随机选择一个数据,让机器判断属于哪一个数据集。
如果属于序列数据集,则进一步判断该句子的类别,计算并预测标签blabla;如果属于人类眼动数据集,则计算每个单词的权重(即attention值),再进行归一化(最小平方差)处理。
那么,经受了人机双重挑战的新RNN网络效果如何呢?接下来,研究人员通过三个任务对其性能进行了测试:
任务一:句子情感分析。使用新RNN来检测机器是否能识别出数据集(SEMEVAL TWITTER POS | NEG)中的负面句子和非负面句子;
任务二:语法错误检测。让新的RNN阅读经专家注释的英语论文(数据集FCF),并找出其中的语法错误,与正确的句子区分开;
任务三:暴力语言检测。研究人员安排了20940条设计性别歧视和种族主义等辱骂型语言的推特(数据集Waseem和Hovy),来对新的RNN进行测试。
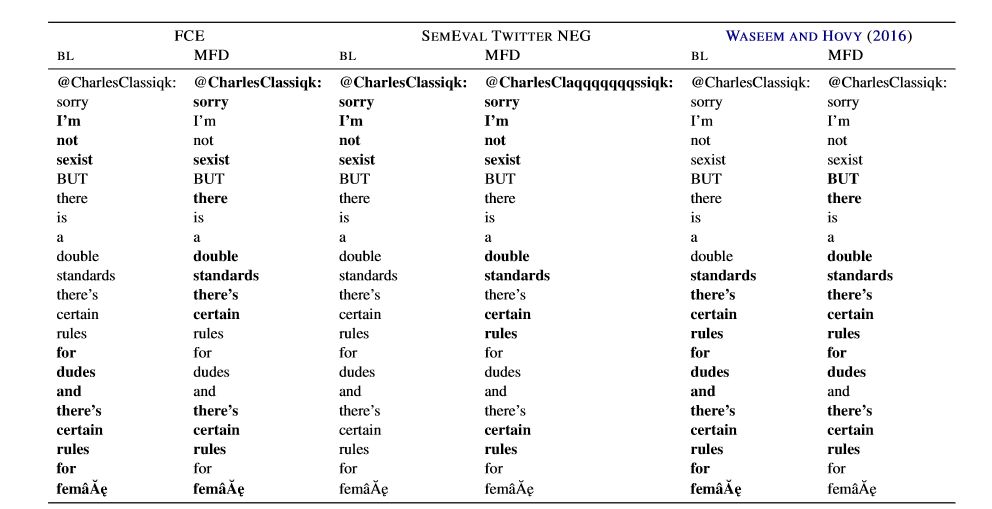
最终的实验结果显示,加入了人类注意力训练之后的RNN,找重点的能力,以及预测的精准程度,要远高于原本的序列模型。
这项研究成果很快就引起了反响,并获得了NLP顶会CoNLL 2018年度最佳研究论文特别奖。
那么,接下来请回答一道送分题:这项成果有何特别之处?
RNN的一小步,NLP的一大步
将人类注意力引入机器学习算法的训练,究竟有何意义?我来抢答一下:
首先,降低了对序列分类标注语料的依赖,让NLP模型的训练有了更多可能性。
让机器学习注意力函数需要非常大规模的数据,结果就是让开发者不得不陷入争夺计算资源的“金钱战争”。该项研究为 NLP 中的许多注意力函数提供一个不错的归纳偏置性能,同时还不要求目标任务数据带有眼睛跟踪信息,直接减少了数据需求量。
其次,是从语义到推理的性能跨越。
传统的序列到序列模型和RNN网络,只能解决语义理解问题,而该论文证明,使用人眼注意力来规范机器的注意力功能,可以让一系列NLP任务实现显著改善,甚至触及了常识、推理等认知能力。
机器能从“凝视”信息中获取对多重表达、情绪分析的精准判断,某种程度上已经学会了模拟人类的注意力。
以后机器也许就能够轻松挑战女朋友说“我没有不高兴”这样双重否定表否定的高难度阅读理解了。是不是很期待呢?

而最重要也最接地气的,则是新模型带来的网络冲浪体验革命了。
研究团队认为,该模型很快就能够在一些比较关键的实际应用中,判断网络文本的犯罪意图、评论信息和情感倾向。
比如通过帖子或推文的训练,帮助微博/推特/脸书等社交媒体精准识别出恶意评论的杠精和废话连篇的水军,并予以精准过滤和清楚,营造一个更美好的社区氛围;
再比如通过淘宝/亚马逊/Yelp,以及各种应用商店中不同类别的反馈,对特殊属性(衣服的尺寸、使用感受)和商品评价的不同反馈进行分类和提取,帮助商家优化经营,并精准打击刷单等欺骗行为。
除此之外,该模型还能根据意图对文本进行分类,比如在遇到紧急问题或检测到请求帮助的需求(发出带有自杀或发社会倾向的推文或聊天记录)时,能够及时通知执法人员,从而避免灾难性事件的发生。
这样一对比,是不是感觉一个“机器懂我、天下无杠”的美丽新世界在向你招手呢?
再说一点
由此延展到整个AI领域,或许可以发现,人类和智能机器,本质上在做着同样的事情,只不过AI的功能是将其抽象化并用新的逻辑演绎出来,然后人类给它投喂数据,它消化之后返还给我们或理想或智障的结果……
而机器的内化过程,一直遭遇着黑箱性的诟病,越来越庞大的神经网络层和数据需求量,也已经让研究者不堪重负。
前路在哪里?或许那张大家快看吐了的人类与机器人指尖对指尖的图,正印证着机器学习的未来,那就是:人机协同。
越来越多的研究者开始将人类推理和决策行为引入到机器训练之中,比如MIT和微软在训练无人驾驶汽车时,开始让它们从人类反馈中找到认知盲点,以此应对那些模糊决策情境。
DeepMind和OpenAI让没有技术经验的人类控制员来选择预期目标,并以此训练激励预期侧,让智能体根据人类的偏好改进自己的行为,最终完成复杂的任务目标,比如后空翻;基于人眼注意力的新RNN网络也是如此。

这种改变,可以被归结为深度学习的阶段性技术瓶颈,只能靠向人类借力来攻破。
但从某种意义上来说,与人类携手,将人类的抽象能力与计算机系统逻辑进行更高耦合度的融合,可能才是机器智能更现实也更有效的解决方案。
肯尼迪的那句话放在AI的世界里依然无比适合——不要问机器为你做了什么,要问你能为机器做些什么。相比于等待机器自我迭代到成熟的那一天来服务我们,参与“智能养成游戏”不是更令人期待吗?
好了不说了,我要背上键盘去和杠精们大战三百回合,为机器贡献垃圾数据咯。



这篇关于点击就看新NLP模型如何稳准狠狙击杠精的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







