本文主要是介绍Spark---RDD算子(单值类型转换算子),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1.RDD算子介绍
- 2.转换算子
- 2.1 Value类型
- 2.1.1 map
- 2.1.2 mapPartitions
- 2.1.3 mapPartitionsWithIndex
- 2.1.4 flatMap
- 2.1.5 glom
- 2.1.6 groupBy
- 2.1.7 filter
- 2.1.8 sample
- 2.1.9 distinct
- 2.1.10 coalesce
- 2.1.11 repartition
- 2.1.12 sortBy
1.RDD算子介绍
RDD算子是用于对RDD进行转换(Transformation)或行动(Action)操作的方法或函数。通俗来讲,RDD算子就是RDD中的函数或者方法,根据其功能,RDD算子可以分为两大类:
转换算子(Transformation): 转换算子用于从一个RDD生成一个新的RDD,但是原始RDD保持不变。常见的转换算子包括map、filter、flatMap等,它们通过对RDD的每个元素执行相应的操作来生成新的RDD。
行动算子(Action): 行动算子触发对RDD的实际计算,并返回计算结果或将结果写入外部存储系统。与转换算子不同,行动算子会导致Spark作业的执行。如collect方法。
2.转换算子
RDD 根据数据处理方式的不同将算子整体上分为:
Value 类型:对一个RDD进行操作或行动,生成一个新的RDD。
双 Value 类型:对两个RDD进行操作或行动,生成一个新的RDD。
Key-Value类型:对键值对进行操作,如reduceByKey((x, y),按照key对value进行合并。
2.1 Value类型
2.1.1 map
将处理的数据逐条进行映射转换,这里的转换可以是类型的转换,也可以是值的转换。
函数定义
def map[U: ClassTag](f: T => U): RDD[U]
代码实现:
//建立与Spark框架的连接val rdd = new SparkConf().setMaster("local[*]").setAppName("RDD") //配置文件val sparkRdd = new SparkContext(rdd) //读取配置文件val mapRdd: RDD[Int] = sparkRdd.makeRDD(List(1, 2, 3, 4))//对mapRdd进行转换val mapRdd1 = mapRdd.map(num => num * 2)//对mapRdd1进行转换val mapRdd2 = mapRdd1.map(num => num + "->")mapRdd2.collect().foreach(print)sparkRdd.stop();//关闭连接

2.1.2 mapPartitions
将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处理,哪怕是过滤数据。
函数定义
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]
val rdd = sc.parallelize(Seq(1, 2, 3, 4, 5, 6)) // 使用 mapPartitions 将每个分区中的所有元素增加 1
val mappedRDD = rdd.mapPartitions(iter => { val increment = 1 iter.map(x => x + increment)
}) mappedRDD.collect().foreach(println) // 输出: 2, 3, 4, 5, 6, 7Map 算子是分区内一个数据一个数据的执行,类似于串行操作。而 mapPartitions 算子是以分区为单位进行批处理操作。
mapPartitions在处理数据的时候因为是批处理,相对于map来说处理效率较高,但是如果数据量较大的情况下使用mapPartitions可能会造成内存溢出,因为mapPartitions会将分区内的数据全部加载到内存中。此时更推荐使用map。
2.1.3 mapPartitionsWithIndex
将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处理,哪怕是过滤数据,在处理时同时可以获取当前分区索引。
函数定义
def mapPartitionsWithIndex[U: ClassTag](
f: (Int, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]
实现只保留第二个分区的数据
val mapRdd: RDD[Int] = sparkRdd.makeRDD(List(1, 2, 3, 4),2)val newRdd: RDD[Int] = mapRdd.mapPartitionsWithIndex((index, iterator) => {if (index == 1) iteratorelse Nil.iterator})newRdd.collect().foreach(println)
2.1.4 flatMap
将处理的数据进行扁平化后再进行映射处理,所以算子也称之为扁平映射
//建立与Spark框架的连接val rdd = new SparkConf().setMaster("local[*]").setAppName("RDD") //配置文件val sparkRdd = new SparkContext(rdd) //读取配置文件val rdd1: RDD[List[Int]] = sparkRdd.makeRDD(List(List(1, 2), List(3, 4)))val rdd2: RDD[String] = sparkRdd.makeRDD(List("Hello Java", "Hello Scala"), 2)val frdd1: RDD[Int] =rdd1.flatMap(list=>{list})val frdd2: RDD[String] =rdd2.flatMap(str=>str.split(" "))frdd1.collect().foreach(println)frdd2.collect().foreach(println)sparkRdd.stop();//关闭连接

2.1.5 glom
将同一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变,glom函数的作用就是将一组数据转换为数组。
函数定义
def glom(): RDD[Array[T]]
/建立与Spark框架的连接val rdd = new SparkConf().setMaster("local[*]").setAppName("RDD") //配置文件val sparkRdd = new SparkContext(rdd) //读取配置文件val rdd1: RDD[Any] = sparkRdd.makeRDD(List(1,2,3,4),2)val value: RDD[Array[Any]] = rdd1.glom()value.collect().foreach(data=> println(data.mkString(",")))sparkRdd.stop();//关闭连接

2.1.6 groupBy
将数据根据指定的规则进行分组, 分区默认不变,但是数据会被打乱重新组合,我们将这样的操作称之为 shuffle。 极限情况下,数据可能被分在同一个分区中
函数定义
def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])]
//按照奇偶分组val rdd1: RDD[Int] = sparkRdd.makeRDD(List(1,2,3,4),2)val value = rdd1.groupBy(num => num % 2)value.collect().foreach(println)//将 List("Hello", "hive", "hbase", "Hadoop")根据单词首写字母进行分组。val rdd2: RDD[String] = sparkRdd.makeRDD(List("Hello", "hive", "hbase", "Hadoop"))val value1: RDD[(Char, Iterable[String])] = rdd2.groupBy(str => {str.charAt(0)})value1.collect().foreach(println)

2.1.7 filter
将数据根据指定的规则进行筛选过滤,符合规则的数据保留,不符合规则的数据丢弃。当数据进行筛选过滤后,分区不变,但是分区内的数据可能不均衡,生产环境下,可能会出现数据倾斜。
函数定义
def filter(f: T => Boolean): RDD[T]
//获取偶数val dataRDD = sparkRdd.makeRDD(List(1, 2, 3, 4), 1)val value1 = dataRDD.filter(_ % 2 == 0)
2.1.8 sample
函数定义
def sample(
withReplacement: Boolean,
fraction: Double,
seed: Long = Utils.random.nextLong): RDD[T]
根据指定的规则从数据集中抽取数据
参数具体意义:
1.抽取数据不放回withReplacement: Boolean, 该参数表示抽取不放回,此时采用伯努利算法(false)fraction: Double,该参数表示抽取的几率,范围在[0,1]之间,0:全不取;1:全取;seed: Long = Utils.random.nextLong): RDD[T] 该参数表示随机数种子2.抽取数据放回withReplacement: Boolean, 该参数表示抽取放回,此时采用泊松算法(true)fraction: Double,该参数表示重复数据的几率,范围大于等于 0.表示每一个元素被期望抽取到的次数seed: Long = Utils.random.nextLong): RDD[T] 该参数表示随机数种子
2.1.9 distinct
将数据集中重复的数据去重
def distinct()(implicit ord: Ordering[T] = null): RDD[T]
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
val dataRDD = sparkRdd.makeRDD(List(1, 2, 3, 4, 1, 2), 6)val value = dataRDD.distinct()

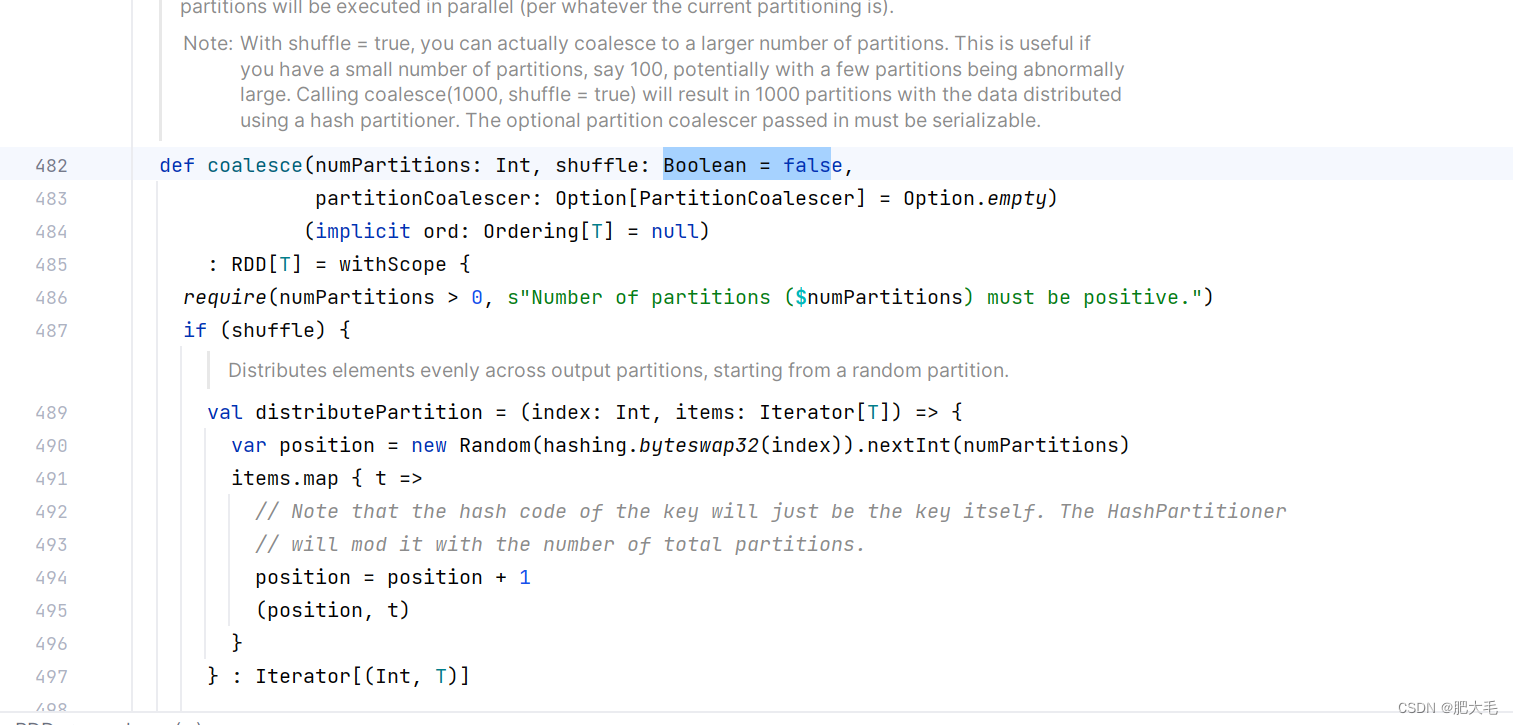
2.1.10 coalesce
根据数据量缩减分区,用于大数据集过滤后,提高小数据集的执行效率当 spark 程序中,存在过多的小任务的时候,可以通过 coalesce 方法,收缩合并分区,减少分区的个数,减小任务调度成本
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null)
: RDD[T]
//初始Rdd采用6个分区val dataRDD = sparkRdd.makeRDD(List(1, 2, 3, 4, 1, 2), 6)//将分区数量缩减至2个val value = dataRDD.coalesce(2)
在coalesce中默认不开启shuffle,在进行分区缩减的时候,数据不会被打散。
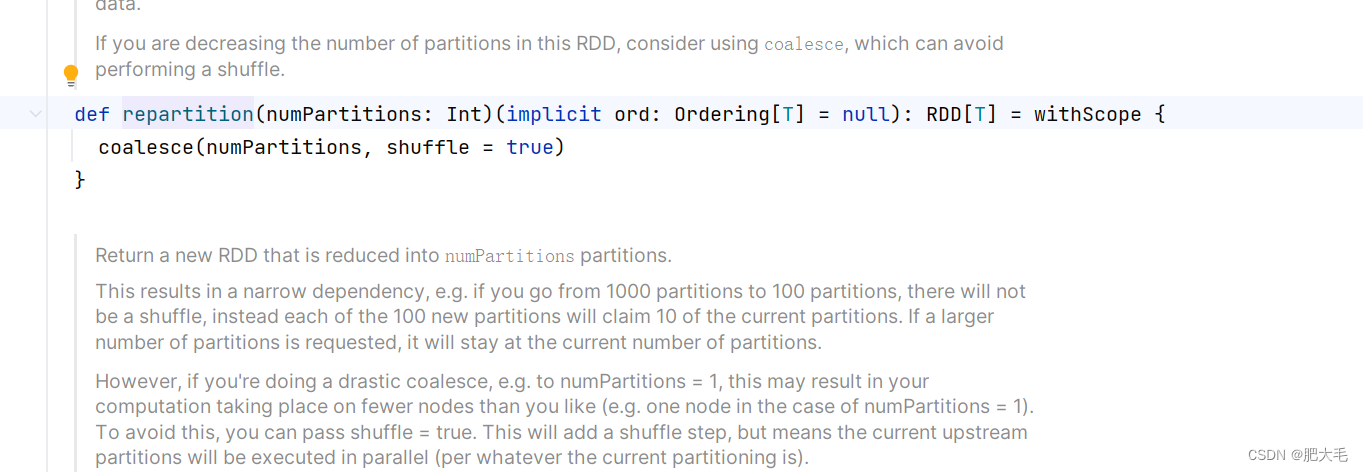
2.1.11 repartition
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
repartition内部其实执行的是 coalesce 操作,参数 shuffle 的默认值为 true。无论是将分区数多的RDD 转换为分区数少的 RDD,还是将分区数少的 RDD 转换为分区数多的 RDD,repartition操作都可以完成,因为无论如何都会经 shuffle 过程。
//将分区数量从2个提升至4个val dataRDD = sparkRdd.makeRDD(List(1, 2, 3, 4, 1, 2), 2)val dataRDD1 = dataRDD.repartition(4)
2.1.12 sortBy
该操作用于排序数据。在排序之前,可以将数据通过 f 函数进行处理,之后按照 f 函数处理的结果进行排序,默认为升序排列。排序后新产生的 RDD 的分区数与原 RDD 的分区数一致。中间存在 shuffle 的过程
def sortBy[K](
f: (T) => K, 该参数表述用于处理的函数
ascending: Boolean = true, 该参数表示是否升序排序
numPartitions: Int = this.partitions.length) 该参数表示设置分区数量
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
val dataRDD = sparkRdd.makeRDD(List(1, 2, 3, 4, 1, 2), 2)//按照初始数据降序排列val dataRDD1 = dataRDD.sortBy(num => num, false, 4)
这篇关于Spark---RDD算子(单值类型转换算子)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






