本文主要是介绍自然语言处理-结巴分词实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 安装包
- 方法1
- 方法2
- 代码
安装包
方法1
首先安装jieba包,我用了虚拟环境首先激活到我自己的TensorFlow(为自己取名的包)环境中,然后pip install jiba 安装
activate TensorFlow
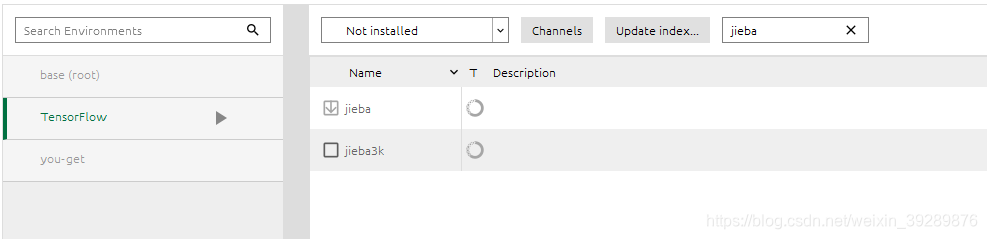
方法2
当然也可以直接在anaconda中进行安装
代码
导入包
import jieba
text='我是练习时长两年半的个人练习生蔡徐坤,我喜欢唱跳rap和篮球'
text

数出分好的word_list但是返回的是内存地址
word_list=jieba.cut(text)
print(word_list)

print(list(word_list))# 缺省是精确模式
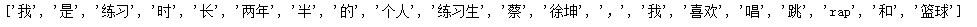
全模式是把中间的语义都写了进去,比如练习生,他包括练习和练习生,精确模式是判断的最有可能的语义
word_list=jieba.cut(text,cut_all=False)
print("精确模式分词结果为:"+"/".join(word_list))# 全模式

word_list=jieba.cut_for_search(text)
print("搜索引擎分词结果为:"+"/".join(word_list))# 搜索引擎模式
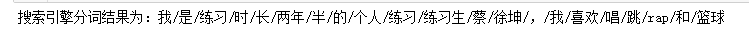
也可以结果直接返回列表
# 把结果直接返回列表
word_list=jieba.lcut(text)
print(word_list)

搜索引擎模式也有这个功能
# 把结果直接返回列表
word_list=jieba.lcut_for_search(text)
print(word_list)

如果有些单词本身也是一体的,我不想分开比如蔡徐坤和练习生
#如何把练习生和蔡徐坤也作为一体 ,在当前目录
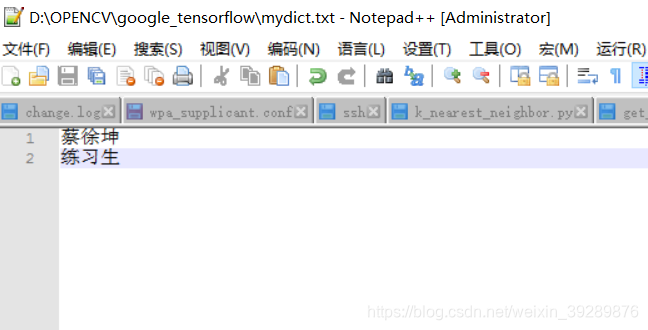
jieba.load_userdict('mydict.txt')
在本地建一个mydict.txt,内部如下
word_list=jieba.lcut(text)
print(word_list)

这篇关于自然语言处理-结巴分词实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



