本文主要是介绍Finding Tiny Faces,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Overview of detection pipeline
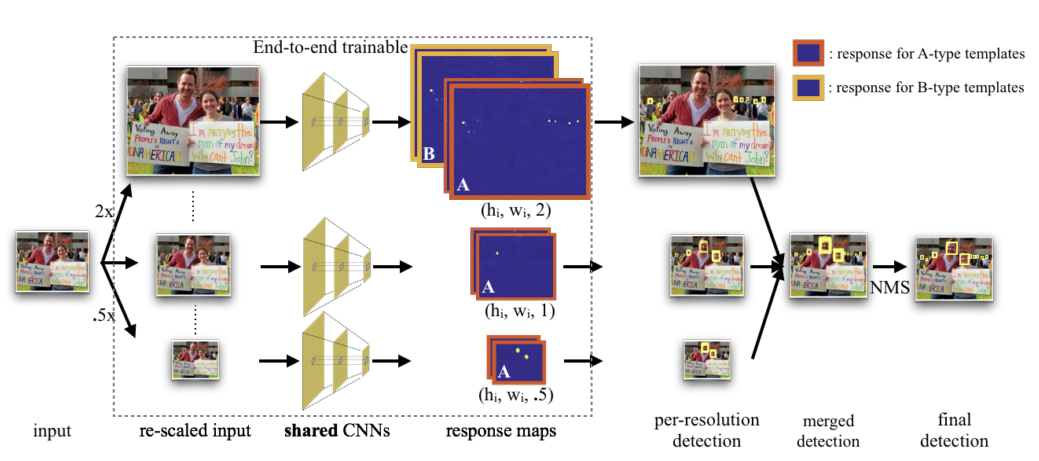
Multi-task modeling of scales

前面a, b两种是传统的 model 方式。 b的缺点是,如果某个尺寸的 model 的样本少的话,不利于训练。而c有利于解决这种问题。 d,e 是作者提出的: d 加入 context 信息, e 利用多层的特征。
Human on context
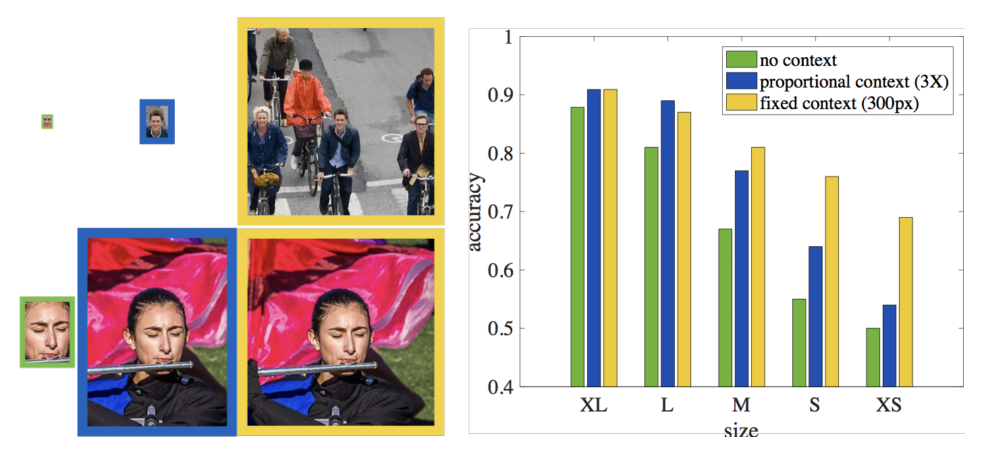
这里分析了context 的作用。人类进行判别人脸的时候,对于大尺寸的人脸,context作用很小,但对于小尺寸的人脸,context的作用很大。
How best to encode context?
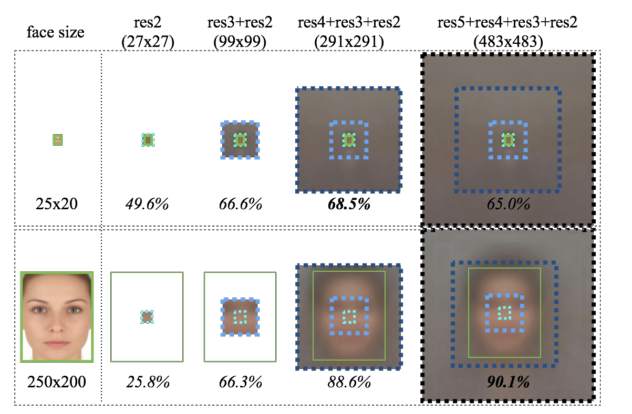
对于小尺寸的人脸,感受野相对较小的feature map 对识别率提升更有效,这时相应的 context 信息也相对少一些,不至于 context 信息过大。 而大尺寸的人脸,则是感受野大的好。
How to generalize pre-trained networks?
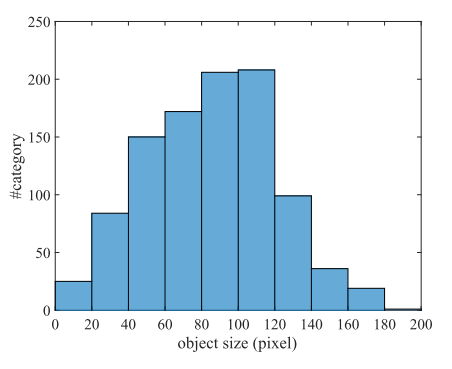
对于ImageNet 而言,80%的object 高度在40~140 pixels。
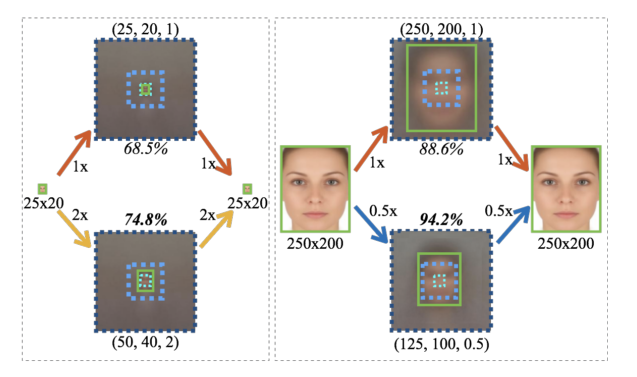
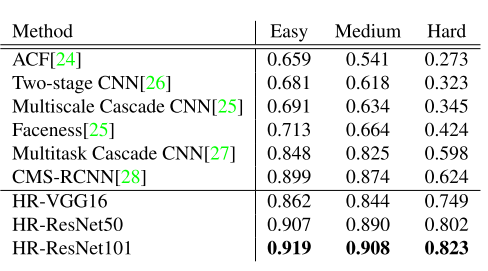
作者发现,medium-size template 比 small-size template 在检测 small objects 时效果更好,同时,medium-size template 比 large-size template 在检测 large objects 时效果也更好。作者给出一个解释是,因为在training dataset 里 large faces 不够多,more medium faces for training medium-size template.但这不能解释 result for small faces. 于是作者又给出另一个解释。在pre-trained dataset (ImageNet) 里,80%的training samples 在 40-140 pixels 之间,也就是属于 medium size. 在fine tuning 的时候,训练的template size 也应该尽可能的在这个范围以内(40-140 pixels).所以我们在fine tune 网络的时候,a template tuned for 50x40 sized faces 比 a template tuned for 25x20 sized faces 在检测 25x20 sized faces 时的性能要好。而a template tuned for 125x100 sized faces 比 a template tuned for 250x200 sized faces 在检测250x200 sized faces 时的性能要好。
从以下的实验,也能得出结论。
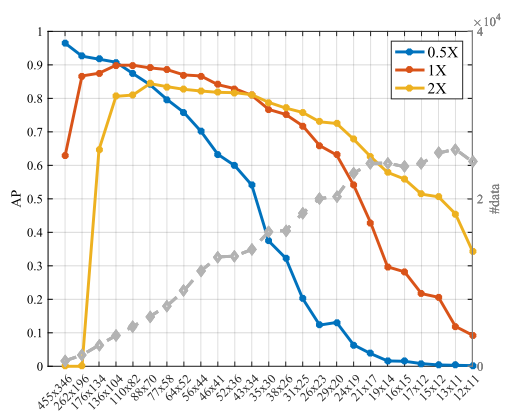
这篇关于Finding Tiny Faces的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









