本文主要是介绍Flink构造宽表实时入库案例介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 安装包准备
| Flink 1.15.4 安装包 |
| Flink cdc的mysql连接器 |
| Flink sql的sdb连接器 |
| MySQL驱动 |
| SDB驱动 |
| Flink jdbc的mysql连接器 |
2. 入库流程图
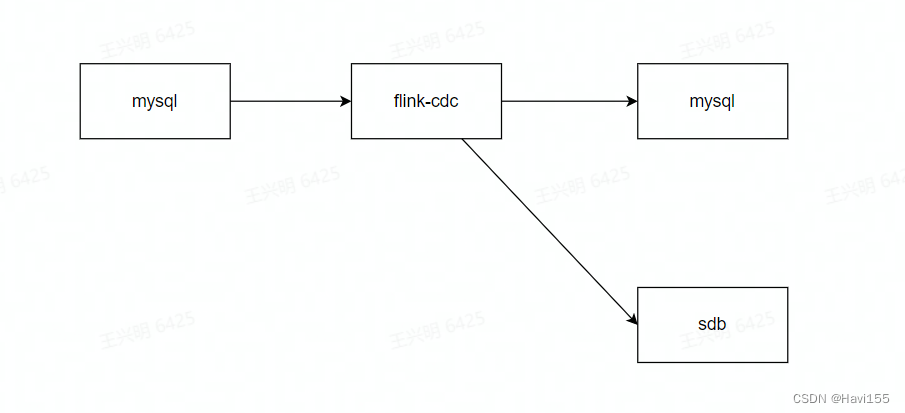
3. Flink安装部署
- 上传Flink压缩包到服务器,并解压
| tar -zxvf flink-1.14.5-bin-scala_2.11.tgz -C /opt/ |
- 复制依赖至Flink中
| cp sdb-flink-connector-3.4.8-jar-with-dependencies.jar /opt/flink-1.14.5/lib
cp sequoiadb-driver-3.4.8.jre8.jar /opt/flink-1.14.5/lib
cp flink-sql-connector-mysql-cdc-2.2.1.jar /opt/flink-1.14.5/lib
cp flink-connector-jdbc_2.11-1.14.6.jar /opt/flink-1.14.5/lib |
- 修改flink-conf.yaml文件
| vi conf/flink-conf.yaml
### 配置Master的机器名(IP地址)
jobmanager.rpc.address: sdb1
### 配置每个taskmanager 生成的临时文件夹
io.tmp.dirs: /opt/flink-1.14.5/tmp |
- 修改master文件
| vi conf/masters
#作为master的ip和端口号
upgrade1:8081 |
- 修改worker文件
| vi conf/workers
#集群主机名
upgrade1
upgrade2
upgrade3 |
- 拷贝到集群其他机器
| scp -r /opt/flink-1.14.5 sdbadmin@upgrade2:/opt/
scp -r /opt/flink-1.14.5 sdbadmin@upgrade3:/opt/ |
- 启动flink集群
| [sdbadmin@upgrade1 flink-1.14.5]$ ./bin/start-cluster.sh |
- 启动flink-SQL
| [sdbadmin@upgrade1 flink-1.14.5]$ ./bin/sql-client.sh |
4. 实时入库
编写造数程序进行造数
4.1 环境准备
4.1.1 开启mysql的binlog
- 创建binlog文件夹
| [sdbadmin@upgrade1 mysql]$ mkdir /opt/sequoiasql/mysql/database/3306/binlog |
- 开启binlog
| vim /opt/sequoiasql/mysql/database/3306/auto.cnf
>>配置以下内容:
log_bin=/opt/sequoiasql/mysql/database/3306/binlog
binlog_format=ROW
expire_logs_days=1
server_id=1 |
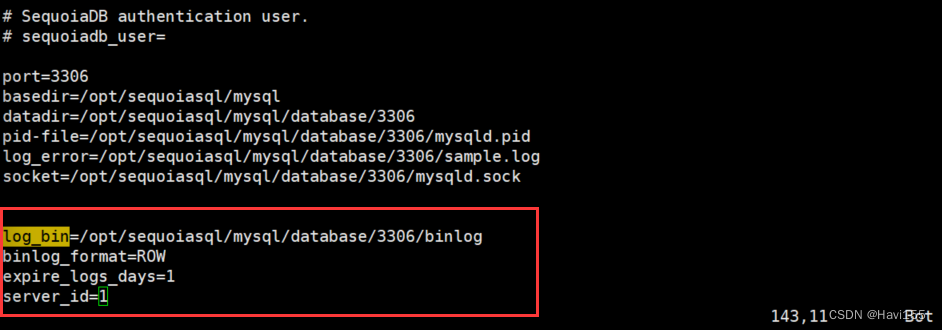
配置完成之后,重启mysql
| [sdbadmin@upgrade1 mysql]$ ./bin/sdb_mysql_ctl stop myinst
[sdbadmin@upgrade1 mysql]$ ./bin/sdb_mysql_ctl start myinst |
4.1.2 创建mysql表
创建库
| create database sbtest;
use sbtest; |
创建表
| CREATE TABLE sbtest1 (
id INT UNSIGNED AUTO_INCREMENT,
uuid INT(10),
name1 CHAR(120),
age INT(4),
time1 DATETIME,
PRIMARY KEY(id)
); |
| CREATE TABLE sbtest2 (
id INT UNSIGNED AUTO_INCREMENT,
uuid INT(10),
name2 CHAR(120),
age INT(4),
time1 DATETIME,
PRIMARY KEY(id)
); |
| CREATE TABLE sbtest3 (
id INT UNSIGNED AUTO_INCREMENT,
uuid INT(10),
name3 CHAR(120),
age INT(4),
time1 DATETIME,
PRIMARY KEY(id)
); |
创建flink入库表
| CREATE TABLE sbtest4 (
id INT UNSIGNED AUTO_INCREMENT,
uuid INT(10),
name1 CHAR(120),
name2 CHAR(120),
name3 CHAR(120),
age INT(4),
time1 DATETIME,
PRIMARY KEY(id)
); |
4.1.3 创建flink映射表
需要用到flink-sql-connector-mysql-cdc-2.2.1.jar
| CREATE TABLE sbtest1_mysql (
id INT,
uuid INT,
name1 CHAR(120),
age INT,
time1 TIMESTAMP,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.223.135',
'port' = '3306',
'username' = 'root',
'password' = 'root',
'database-name' = 'sbtest',
'table-name' = 'sbtest1'
); |
| CREATE TABLE sbtest2_mysql (
id INT,
uuid INT,
name2 CHAR(120),
age INT,
time1 TIMESTAMP,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.223.135',
'port' = '3306',
'username' = 'root',
'password' = 'root',
'database-name' = 'sbtest',
'table-name' = 'sbtest2'
); |
| CREATE TABLE sbtest3_mysql (
id INT,
uuid INT,
name3 CHAR(120),
age INT,
time1 TIMESTAMP,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.223.135',
'port' = '3306',
'username' = 'root',
'password' = 'root',
'database-name' = 'sbtest',
'table-name' = 'sbtest3'
); |
创建flink --> mysql入库映射表
需要用到flink-connector-jdbc_2.11-1.14.6.jar
| CREATE TABLE sbtest4_mysql (
id BIGINT,
uuid INT,
name1 CHAR(120),
name2 CHAR(120),
name3 CHAR(120),
age INT,
time1 TIMESTAMP,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.168.223.135:3306/sbtest',
'username' = 'root',
'password' = 'root',
'table-name' = 'sbtest4'
); |
创建flink --> mysql入库映射表
需要用到sdb-flink-connector-3.4.8-jar-with-dependencies.jar
| CREATE TABLE sbtest_sdb (
id BIGINT,
uuid INT,
name1 CHAR(120),
name2 CHAR(120),
name3 CHAR(120),
age INT,
time1 TIMESTAMP,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'sequoiadb',
'bulksize' = '1',
'hosts' = '192.168.223.135:11810',
'collectionspace' = 'sbtest',
'collection' = 'sbtest4'
); |
4.2 MySQL实时入库
4.2.1 Flink left join
| select sdb1.id, sdb1.uuid, sdb1.name1, sdb2.name2, sdb3.name3, sdb1.age, sdb1.time1
from sbtest1_mysql sdb1
left join sbtest2_mysql sdb2
on sdb1.id = sdb2.id
left join sbtest3_mysql sdb3
on sdb1.id = sdb3.id; |
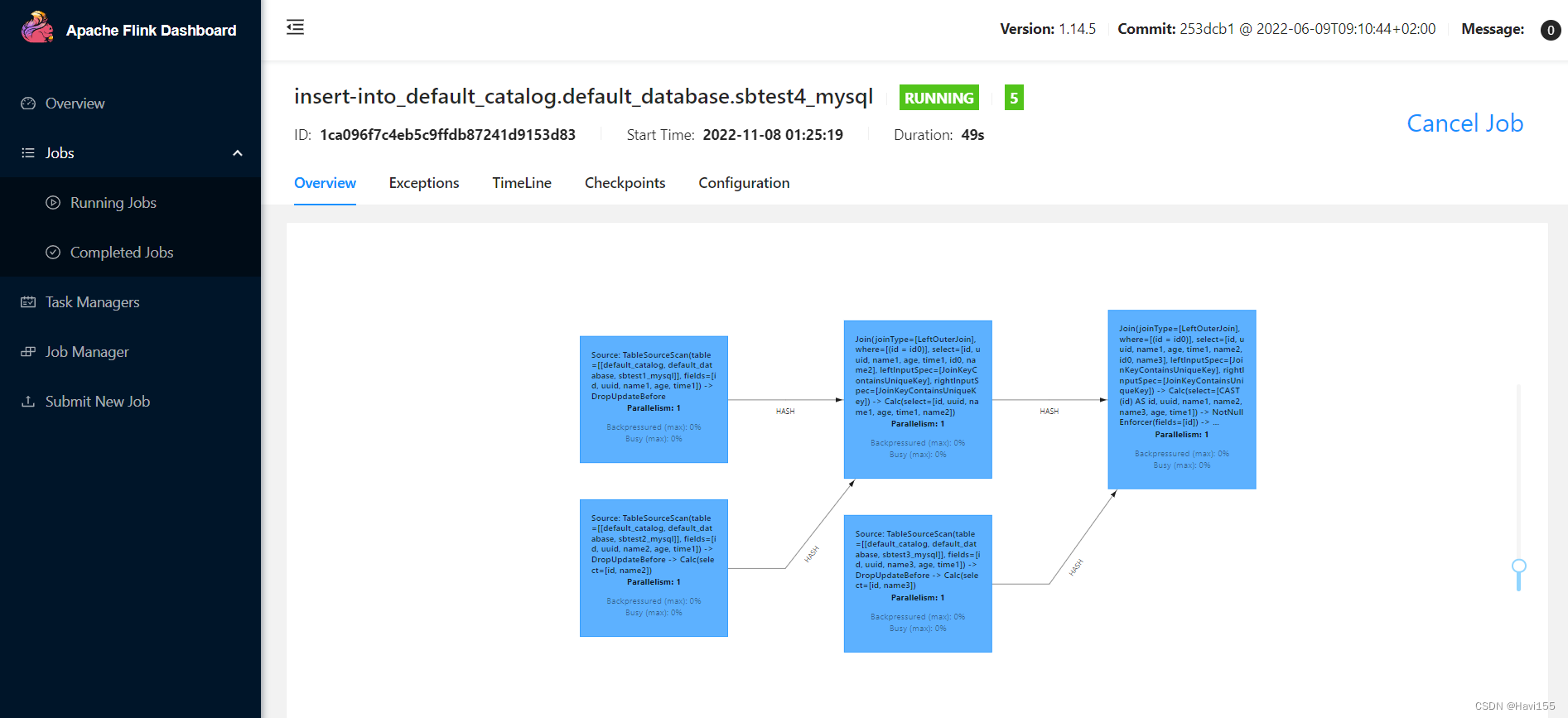
4.2.2 mysql实时入库
| insert into sbtest4_mysql select sdb1.id, sdb1.uuid, sdb1.name1, sdb2.name2, sdb3.name3, sdb1.age, sdb1.time1
from sbtest1_mysql sdb1
left join sbtest2_mysql sdb2
on sdb1.id = sdb2.id
left join sbtest3_mysql sdb3
on sdb1.id = sdb3.id; |
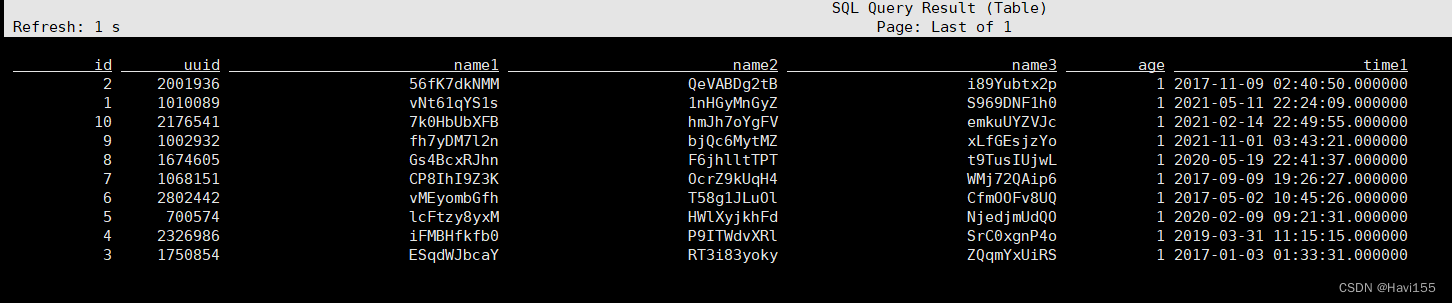
查看Flink任务
查看可以成功入库

4.3 SDB实时入库
4.3.1 Flink left join
| select sdb1.id, sdb1.uuid, sdb1.name1, sdb2.name2, sdb3.name3, sdb1.age, sdb1.time1
from sbtest1_mysql sdb1
left join sbtest2_mysql sdb2
on sdb1.id = sdb2.id
left join sbtest3_mysql sdb3
on sdb1.id = sdb3.id; |

4.3.2 sdb实时入库
| insert into sbtest_sdb select sdb1.id, sdb1.uuid, sdb1.name1, sdb2.name2, sdb3.name3, sdb1.age, sdb1.time1
from sbtest1_mysql sdb1
left join sbtest2_mysql sdb2
on sdb1.id = sdb2.id
left join sbtest3_mysql sdb3
on sdb1.id = sdb3.id; |
查看Flink任务
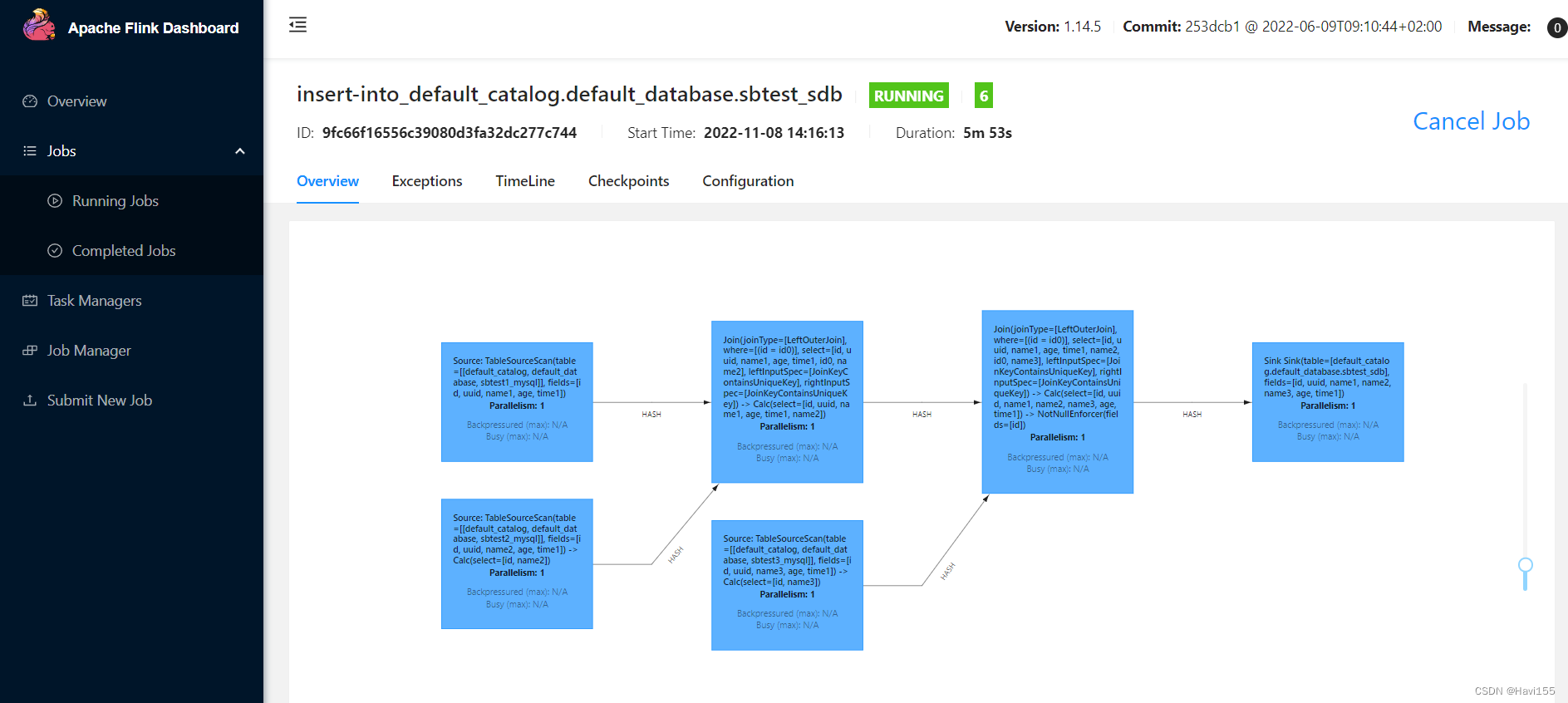
显示已经成功入库

这篇关于Flink构造宽表实时入库案例介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




