本文主要是介绍QQ大数据:逃离北上广深后27%的人想回去,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

腾讯即通产品部副总经理冼业成
12%用户“逃离”北上广深
一直以来,“逃离”北上广深是大家非常关心的民生问题。QQ 大数据显示,2015 年 2 月 4日至 2 月 15 日,共计 5334 万人从北上广深四城,回到全国各地,占四地总用户数的 58%。节后,约 1084 万的人真正逃离了北上广深,逃离率为 12%,比上年同期上涨了1%。其中北京又以 19% 的逃离率成为人们最想逃离的城市。调查显示,在逃离的人群中,又有27.1%的用户想重回北上广深。

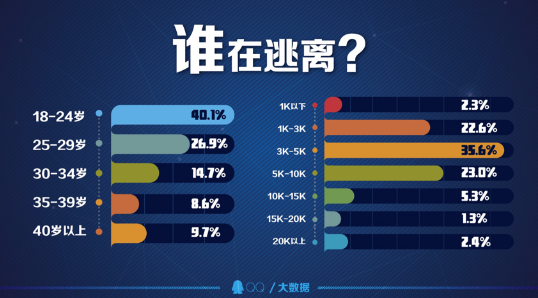
QQ通过问卷抽样调查发现,“逃离”北上广深的用户中,25—30岁的QQ用户占35.8%居首位,其次是31—35岁的用户。此外,35.6%的用户收入范围在3001-5000元,23%的用户收入范围在5001-10000元。
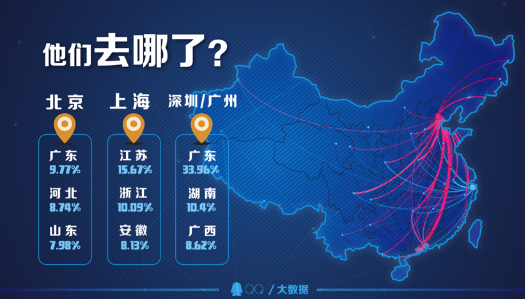
这些节后没有返回北上广深的人们,去哪儿了呢?QQ大数据显示,他们大多在临近的城市找到了新天地,其中值得注意的是,离开北京的用户中,有将近10%的用户选择前往广东。广东以23%的占比成为北上广深四城逃离用户的首选,其余大部分用户选择前往江苏、河北、山东、湖南、浙江等城市。
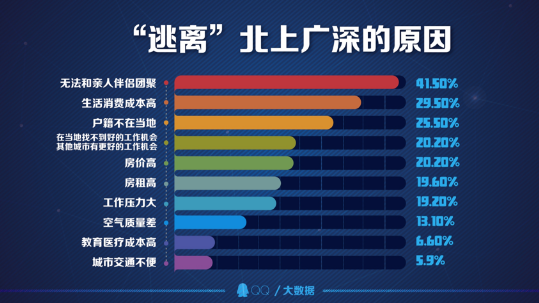
无法与亲人伴侣团聚成“逃离”的主要原因
调查显示,离开北上广深的用户中,有41.5%的用户是因为无法和亲人伴侣相聚。其次如生活消费成本高、户籍不在当地、房价、房租等问题也排前列。而仅有5.9%的用户认为城市交通问题是他们离开的原因,可见城市再堵也拦不住年轻人追梦的心。
超两千万新用户寻梦北上广深
“北上广深”就像一座围墙,在里面的人想出去,外面的人想进来。在2015年春节后,有超过两千万新的QQ用户来到北上广深寻找梦想,占四地总用户的26%。其中,北京以40%的涌入率位列四城之首。流入北上广深的“新血液”大多是25—29岁的QQ用户,仅这部分用户就超过26%,并且超过半数为男生。
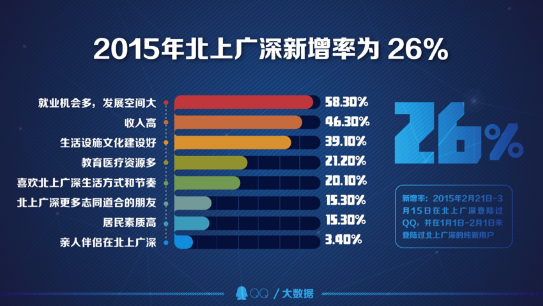
从QQ大数据分析可见,尽管很多人在“逃离”,但两倍的人还在“进入”,北上广深的人口吸引强势地位仍在加剧,北京依然是年轻人“追梦”的首选之地。同时通过问卷调研,可以看出58.3%的QQ用户是为了更大的发展空间及更多就业机会而来到北上广深,这里的高收入、良好的生活设施及文化建设吸引着他们前来。
从“逃离北上广深”这个案例可以看到,QQ大数据的核心正是“人”,以人的走向、变动来揭示中国经济社会发展的走向,这正是QQ倡导的“以‘人’为本的大数据未来”。通过QQ大数据,能够以8.60亿的QQ月活跃用户为基础,描绘出中国人的各项社会生活动态画卷,从而达到分析国家现实国情、展望未来发展的目的。
作者: 景保玉
来源:IT168
原文链接:QQ大数据:逃离北上广深后27%的人想回去
这篇关于QQ大数据:逃离北上广深后27%的人想回去的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







