本文主要是介绍python3操作psycopg2/其它SQL数据库时查询数据以字典格式返回,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在python3中,操作pymysql或者psycopg2等SQL数据库进行数据查询时,它这个库里面好像并没有像python2一样在底层自动帮我们循环转换好以字典键值对的格式给我们返回数据(可能是我没找到),而是在列表里面以元组类型直接把值返回过来,这样就导致我们在取值的时候只能通过下标去取,很容易出错,非常的不方便。针对于此,我简单封装了一个方法,以psycopg2为例,在执行查询语句时,将结果转换成字典类型返回。demo如下:
import psycopg2def get_data(database_info,sql):conn = psycopg2.connect(database=database_info["database"], user=database_info["user"],password=database_info["password"],host=database_info["host"], port=database_info["port"])cur = conn.cursor()try:cur.execute(sql)#获取表的所有字段名称coloumns = [row[0] for row in cur.description]result = [[str(item) for item in row] for row in cur.fetchall()]return [dict(zip(coloumns, row)) for row in result]except Exception as ex:print(ex)finally:conn.close()
#数据库连接信息
database_info={"database":"test_base_inf","user":"data_inf_root","password":"BASE_root~589","host":"192.168.12.101","port":"2345"
}
sql="select * from nric_affiliation"
data=get_data(database_info,sql)
for item in data:print(item)运行返回格式如图:
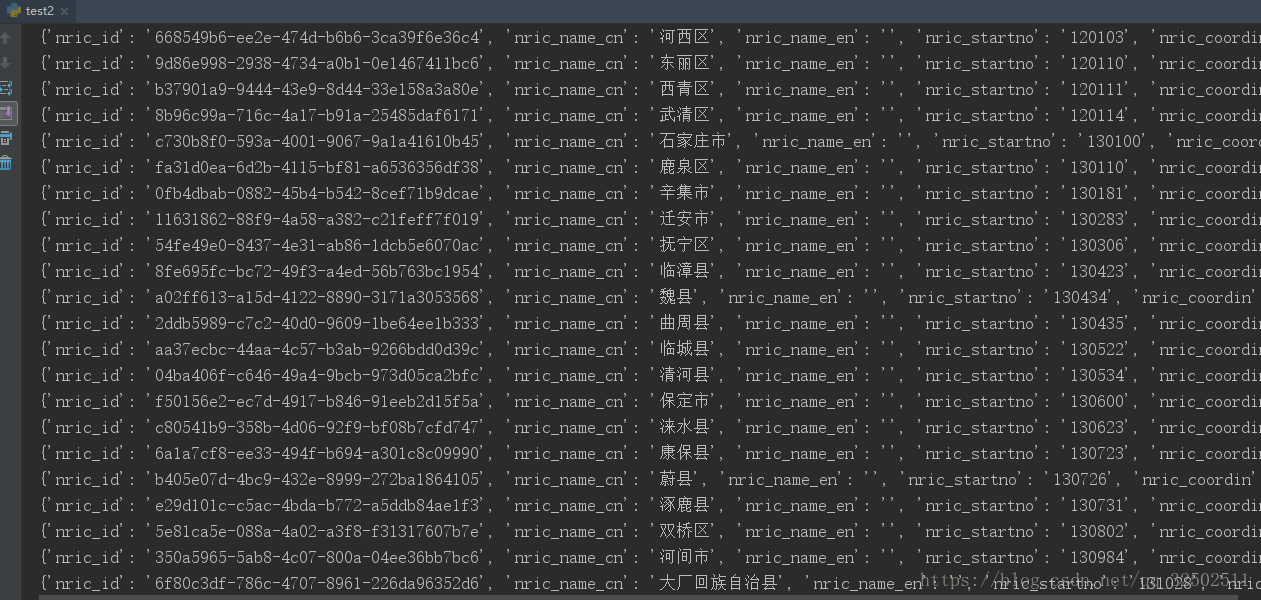
这样就变成了以字段键值对的格式了
#-------------------------------评论朋友反馈的新方法,确实可以用--------------------------------
def get_data(sql):conn = psycopg2.connect(database=GP_DATABASE, user=GP_USERNAME,password=GP_PASSWORD, host=GP_HOST,port=GP_PORT)cur = conn.cursor(cursor_factory=psycopg2.extras.RealDictCursor)try:cur.execute(sql)return cur.fetchall()except Exception as ex:print(ex)finally:conn.close()data=get_data("select * from tb_flight where is_complete='false'")
print(data)
这篇关于python3操作psycopg2/其它SQL数据库时查询数据以字典格式返回的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







