本文主要是介绍人工智障学习笔记——机器学习(10)AP聚类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一.概念
Affinity Propagation (AP) 聚类是2007年在Science杂志上提出的一种新的基于数据点间的"信息传递"的一种聚类算法。与k-均值算法或k中心点算法不同,AP算法不需要在运行算法之前确定聚类的个数。AP算法寻找的"examplars"即聚类中心点是数据集合中实际存在的点,作为每类的代表。它根据N个数据点之间的相似度进行聚类,这些相似度可以是对称的,即两个数据点互相之间的相似度一样(如欧氏距离);也可以是不对称的,即两个数据点互相之间的相似度不等。这些相似度组成N×N的相似度矩阵S(其中N为有N个数据点)。
二.算法
1. 更新相似度矩阵中每个点的吸引度信息,计算归属度信息
2. 更新归属度信息,计算吸引度信息
3. 对样本点的吸引度信息和归属度信息求和,检测其选择聚类中心的决策;若经过若干次迭代之后其聚类中心不变、或者迭代次数超过既定的次数、又或者一个子区域内的关于样本点的决策经过数次迭代后保持不变,则结束
三.sklearn提供的API
sklearn提供了AP聚类的方法AffinityPropagation
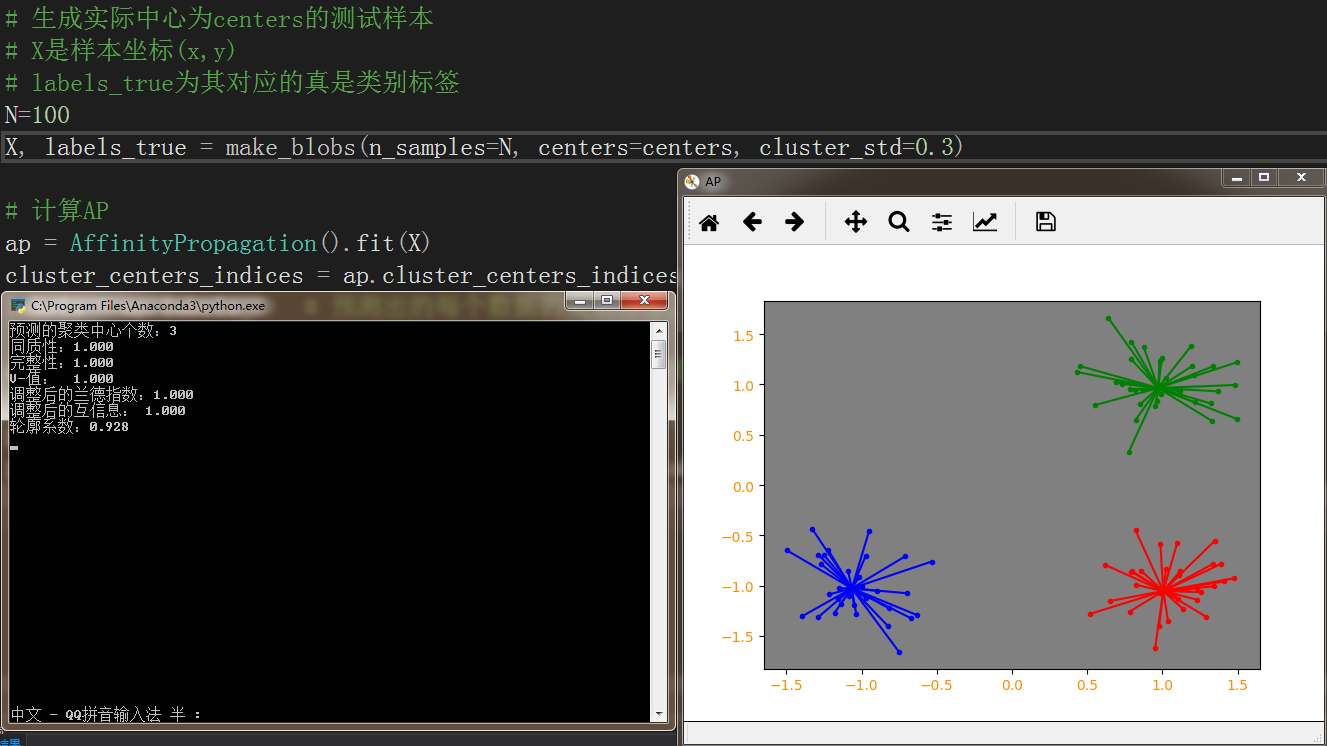
以下代码为测试样例以及六大分群质量评估
from sklearn.cluster import AffinityPropagation,KMeans
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
# 生成测试数据
centers = [[1,1], [-1,-1],[1,-1]]# 生成实际中心为centers的测试样本
# X是样本坐标(x,y)
# labels_true为其对应的真是类别标签
N=500
X, labels_true = make_blobs(n_samples=N, centers=centers, cluster_std=0.5) # 计算AP
ap = AffinityPropagation().fit(X)
cluster_centers_indices = ap.cluster_centers_indices_
labels = ap.labels_ # 预测出的每个数据的类别标签,labels是一个NumPy数组n_clusters_ = len(cluster_centers_indices) # 预测聚类中心的个数print('预测的聚类中心个数:%d' % n_clusters_)
print('同质性:%0.3f' % metrics.homogeneity_score(labels_true, labels))
print('完整性:%0.3f' % metrics.completeness_score(labels_true, labels))
print('V-值: % 0.3f' % metrics.v_measure_score(labels_true, labels))
print('调整后的兰德指数:%0.3f' % metrics.adjusted_rand_score(labels_true, labels))
print('调整后的互信息: %0.3f' % metrics.adjusted_mutual_info_score(labels_true, labels))
print('轮廓系数:%0.3f' % metrics.silhouette_score(X, labels, metric='sqeuclidean'))# 绘制图表展示
import matplotlib.pyplot as plt
from itertools import cycleplt.figure('AP')
plt.subplot(facecolor=(0.5,0.5,0.5))
colors = cycle('rgbcmykw')
# 循环为每个类标记不同的颜色
for k, col in zip(range(n_clusters_), colors):# labels == k 使用k与labels数组中的每个值进行比较# 如labels = [1,0],k=0,则‘labels==k’的结果为[False, True]class_members = labels == kcluster_center = X[cluster_centers_indices[k]] # 聚类中心的坐标plt.plot(X[class_members, 0], X[class_members, 1], col + '.')plt.plot(cluster_center[0], cluster_center[1], markerfacecolor=col,markeredgecolor='k', markersize=14)for x in X[class_members]:plt.plot([cluster_center[0], x[0]], [cluster_center[1], x[1]], col)
plt.xticks(fontsize=10, color="darkorange")
plt.yticks(fontsize=10, color="darkorange")
plt.show()
当不指定Preference Damping 等参数时其效果十分不稳定
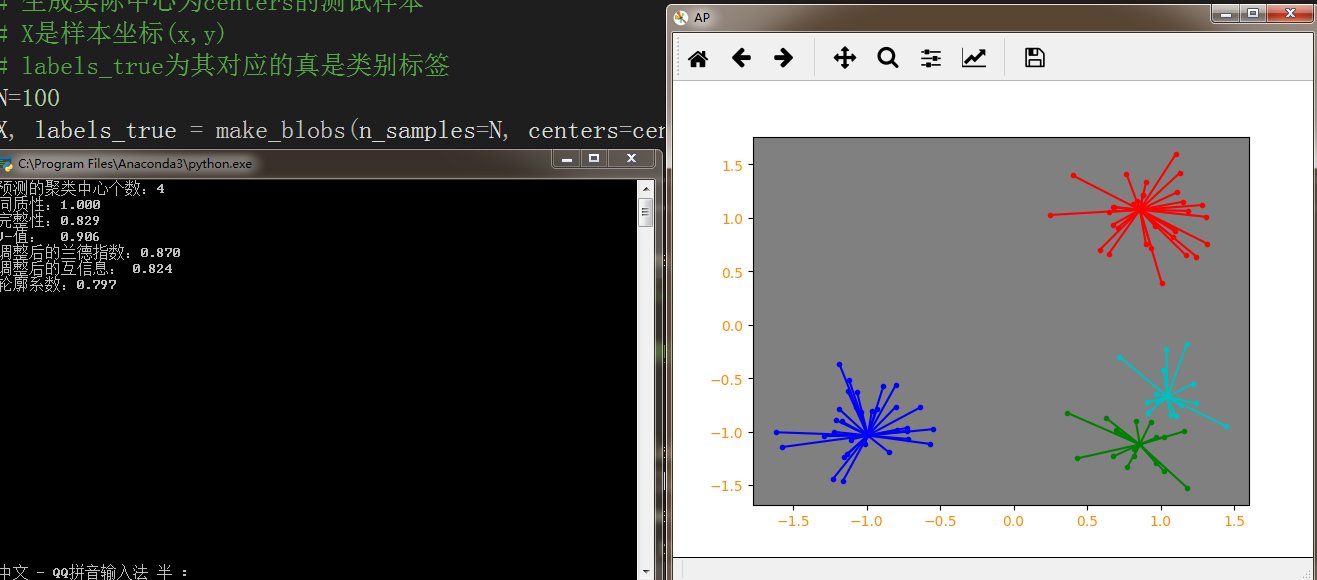
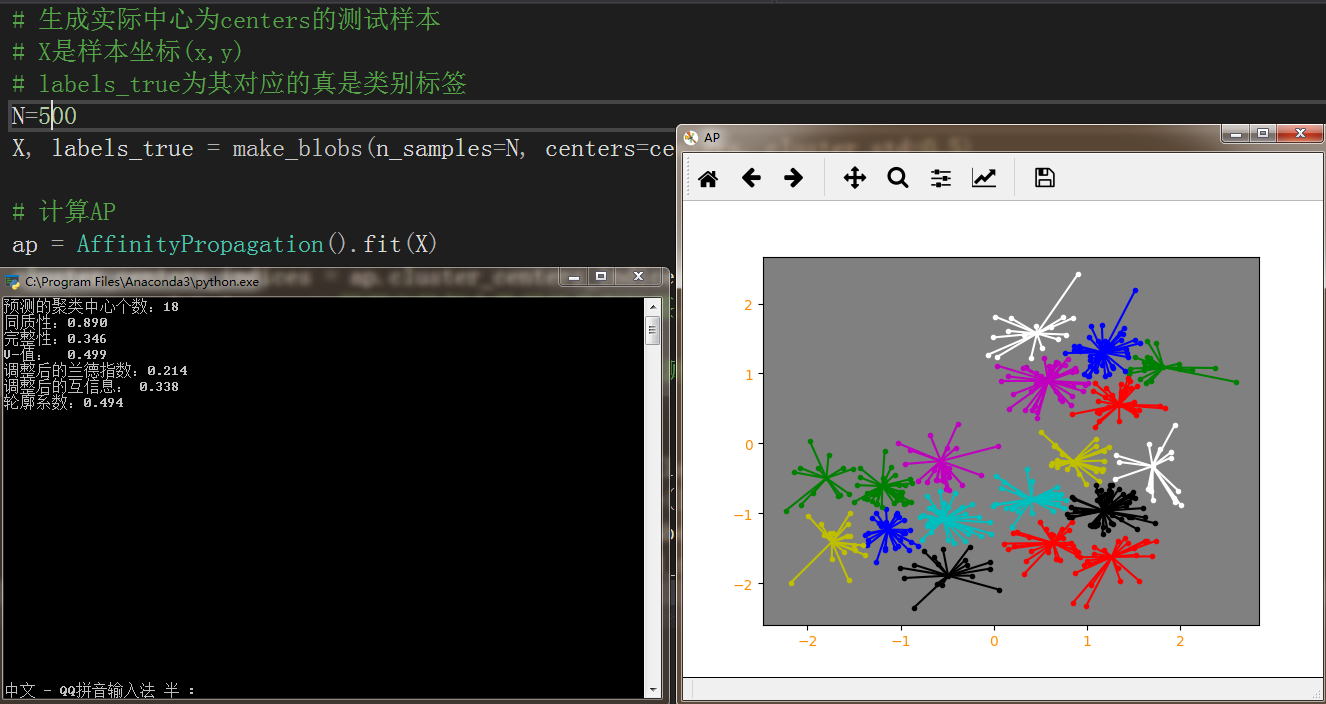
且AP算法复杂度较高,当数据量较大时,其时间效率被K-Means完爆
import numpy as np
import matplotlib.pyplot as plt
import time
from sklearn.cluster import KMeans,AffinityPropagation
from sklearn.datasets.samples_generator import make_blobs # 生成测试数据
np.random.seed(0)
centers = [[1, 1], [-1, -1], [1, -1]]
kmeans_time = []
ap_time = []
pow=4
for i in range(pow): n = np.power(10,i+1)X, labels_true = make_blobs(n_samples=n, centers=centers, cluster_std=0.7) # 计算K-Means算法时间 k_means = KMeans(init='k-means++', n_clusters=3, n_init=10) t0 = time.time() k_means.fit(X) kmeans_time.append([n,(time.time() - t0)]) # 计算AP算法时间 ap = AffinityPropagation() t0 = time.time() ap.fit(X) ap_time.append([n,(time.time() - t0)]) print ('K-Means time',kmeans_time[:10])
print ('AP time',ap_time[:10])
# 图形展示
km_mat = np.array(kmeans_time)
ap_mat = np.array(ap_time)
plt.figure()
plt.bar(np.arange(pow)+1-0.15, km_mat[:,1], width = 0.3, color = 'r', label = 'K-Means', log = 'True')
plt.bar(np.arange(pow)+1+0.15, ap_mat[:,1], width = 0.3, color = 'b', label = 'AffinityPropagation', log = 'True')
plt.xlabel('pow')
plt.ylabel('time')
plt.xticks(fontsize=10, color="darkorange")
plt.yticks(fontsize=10, color="darkorange")
plt.title('K-Means and AffinityPropagation computing time ')
plt.legend(loc='upper center')
plt.show() 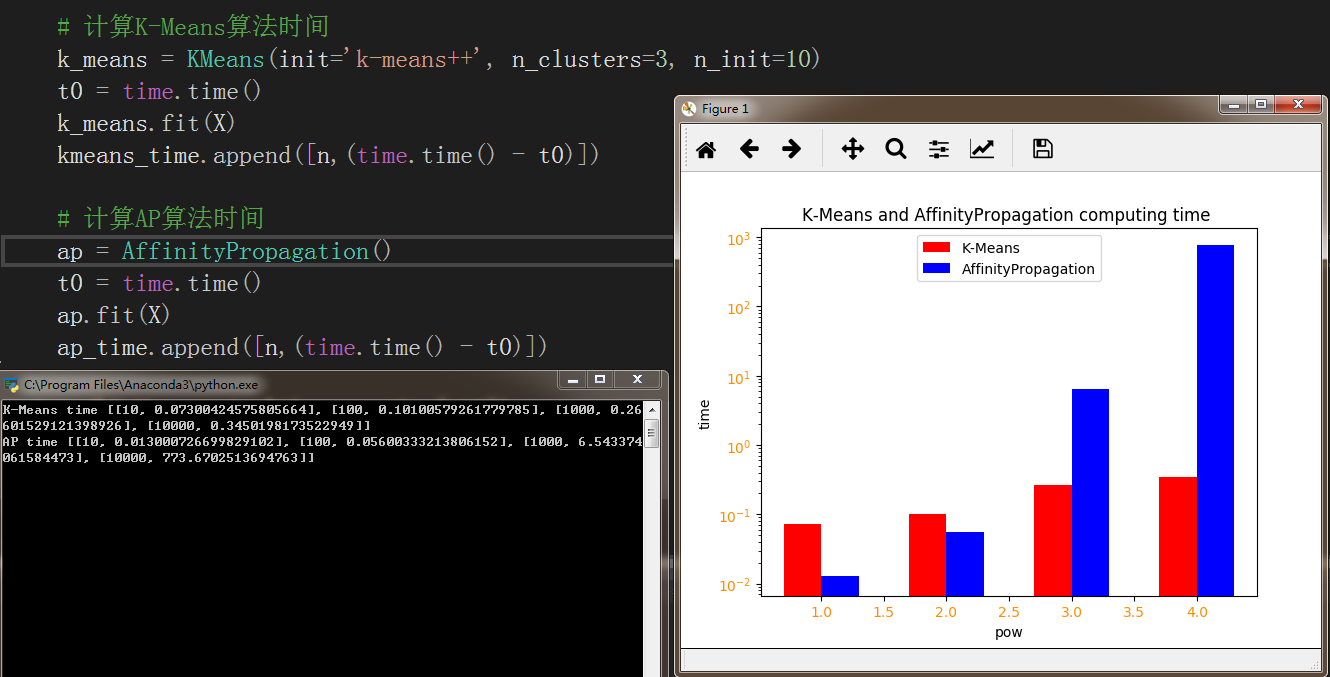
四.总结
尽管AP聚类算法的在大数据面前时间效率爆炸,但其还是有一些小优势的
1.AP聚类不需要指定K(经典的K-Means)或者是其他描述聚类个数(SOM中的网络结构和规模)的参数(对比K-Means)。
2.AP聚类的聚类examplar是原始数据中确切存在的一个数据点,而不是由多个数据点求平均而得到的聚类中心(对比K-Means)。
3.对距离矩阵的对称性没要求。AP通过输入相似度矩阵来启动算法,因此允许数据呈非对称,数据适用范围非常大
4.多次执行AP聚类算法,得到的结果是完全一样的,即不需要进行随机选取初值步骤(对比K-Means)。
5.误差平方和低。(但是太依赖参考度preference了)
五.相关学习资源
http://www.dataivy.cn/blog/%E8%81%9A%E7%B1%BB%E7%AE%97%E6%B3%95affinity-propagation_ap/
http://blog.csdn.net/u010161379/article/details/51636926
https://www.cnblogs.com/Acceptyly/p/4679564.html
这篇关于人工智障学习笔记——机器学习(10)AP聚类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








