本文主要是介绍分类回归——CART分类与回归以及Python实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CART分类与回归树本质上是一样的,构建过程都是逐步分割特征空间,预测过程都是从根节点开始一层一层的判断直到叶节点给出预测结果。只不过分类树给出离散值,而回归树给出连续值(通常是叶节点包含样本的均值),另外分类树基于Gini指数选取分割点,而回归树基于平方误差选取分割点。
CART分类树:
核心思想:以特征及对应特征值组成元组为切分点,逐步切分样本空间
基本概念:
基尼指数(Gini):样本属于第K类的概率为pk,则基尼指数为
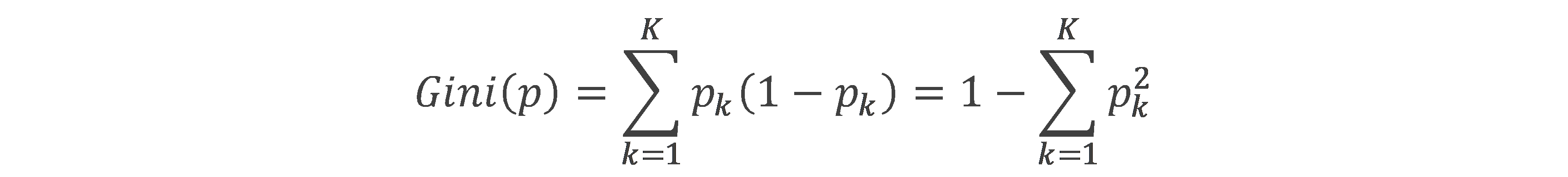
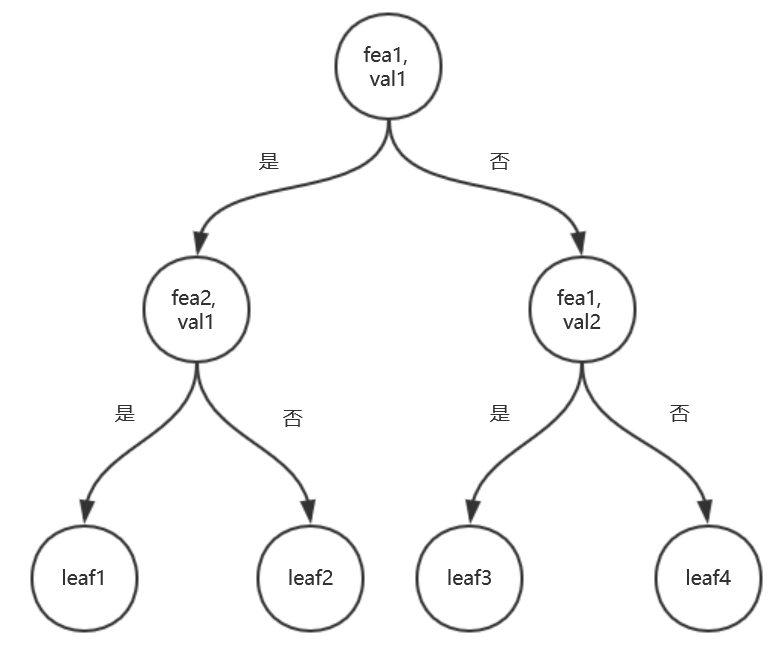
CART分类树示意图如下:
算法流程:
l Input:阈值epsilon,最少样本量min_sample,训练数据集X,y
l Output: CART分类树
l Step1:建立特征集,空树。
l Step2: 递归构建树。
递归终止条件:
1. 子数据集少于阈值min_sample
2. 基尼指数下降量少于epsilon
树的构建流程:
1. 搜寻最优切分点(由特征及某个值的元组构成),并返回切分后两个子数据集的索引。
2. 依据最优切分点构建树的节点,其中满足切分点条件为左子树,反之右子树。
3. 重复步骤1,2,递归切分两个子数据集。
l Step3: 运用构建好的分类树预测。递归搜索树,碰到叶节点返回标记。
"""
CART分类树,是一颗二叉树,以某个特征以及该特征对应的一个值为节点,故相对ID3算法,最大的不同就是特征可以使用多次
"""
from collections import Counter, defaultdictimport numpy as npclass node:def __init__(self, fea=-1, val=None, res=None, right=None, left=None):self.fea = fea # 特征self.val = val # 特征对应的值self.res = res # 叶节点标记self.right = rightself.left = leftclass CART_CLF:def __init__(self, epsilon=1e-3, min_sample=1):self.epsilon = epsilonself.min_sample = min_sample # 叶节点含有的最少样本数self.tree = Nonedef getGini(self, y_data):# 计算基尼指数c = Counter(y_data)return 1 - sum([(val / y_data.shape[0]) ** 2 for val in c.values()])def getFeaGini(self, set1, set2):# 计算某个特征及相应的某个特征值组成的切分节点的基尼指数num = set1.shape[0] + set2.shape[0]return set1.shape[0] / num * self.getGini(set1) + set2.shape[0] / num * self.getGini(set2)def bestSplit(self, splits_set, X_data, y_data):# 返回所有切分点的基尼指数,以字典形式存储。键为split,是一个元组,第一个元素为最优切分特征,第二个为该特征对应的最优切分值pre_gini = self.getGini(y_data)subdata_inds = defaultdict(list) # 切分点以及相应的样本点的索引for split in splits_set:for ind, sample in enumerate(X_data):if sample[split[0]] == split[1]:subdata_inds[split].append(ind)min_gini = 1best_split = Nonebest_set = Nonefor split, data_ind in subdata_inds.items():set1 = y_data[data_ind] # 满足切分点的条件,则为左子树set2_inds = list(set(range(y_data.shape[0])) - set(data_ind))set2 = y_data[set2_inds]if set1.shape[0] < 1 or set2.shape[0] < 1:continuenow_gini = self.getFeaGini(set1, set2)if now_gini < min_gini:min_gini = now_ginibest_split = splitbest_set = (data_ind, set2_inds)if abs(pre_gini - min_gini) < self.epsilon: # 若切分后基尼指数下降未超过阈值则停止切分best_split = Nonereturn best_split, best_set, min_ginidef buildTree(self, splits_set, X_data, y_data):if y_data.shape[0] < self.min_sample: # 数据集小于阈值直接设为叶节点return node(res=Counter(y_data).most_common(1)[0][0])best_split, best_set, min_gini = self.bestSplit(splits_set, X_data, y_data)if best_split is None: # 基尼指数下降小于阈值,则终止切分,设为叶节点return node(res=Counter(y_data).most_common(1)[0][0])else:splits_set.remove(best_split)left = self.buildTree(splits_set, X_data[best_set[0]], y_data[best_set[0]])right = self.buildTree(splits_set, X_data[best_set[1]], y_data[best_set[1]])return node(fea=best_split[0], val=best_split[1], right=right, left=left)def fit(self, X_data, y_data):# 训练模型,CART分类树与ID3最大的不同是,CART建立的是二叉树,每个节点是特征及其对应的某个值组成的元组# 特征可以多次使用splits_set = []for fea in range(X_data.shape[1]):unique_vals = np.unique(X_data[:, fea])if unique_vals.shape[0] < 2:continueelif unique_vals.shape[0] == 2: # 若特征取值只有2个,则只有一个切分点,非此即彼splits_set.append((fea, unique_vals[0]))else:for val in unique_vals:splits_set.append((fea, val))self.tree = self.buildTree(splits_set, X_data, y_data)returndef predict(self, x):def helper(x, tree):if tree.res is not None: # 表明到达叶节点return tree.reselse:if x[tree.fea] == tree.val: # "是" 返回左子树branch = tree.leftelse:branch = tree.rightreturn helper(x, branch)return helper(x, self.tree)def disp_tree(self):# 打印树self.disp_helper(self.tree)returndef disp_helper(self, current_node):# 前序遍历print(current_node.fea, current_node.val, current_node.res)if current_node.res is not None:returnself.disp_helper(current_node.left)self.disp_helper(current_node.right)returnif __name__ == '__main__':from sklearn.datasets import load_irisX_data = load_iris().datay_data = load_iris().targetimport timefrom machine_learning_algorithm.cross_validation import validate # 导入交叉验证模块,见githubstart = time.clock()g = validate(X_data, y_data, ratio=0.2)for item in g:X_data_train, y_data_train, X_data_test, y_data_test = itemclf = CART_CLF()clf.fit(X_data_train, y_data_train)score = 0for X, y in zip(X_data_test,y_data_test):if clf.predict(X) == y:score += 1print(score / len(y_data_test))print(time.clock() - start)
CART回归树:
核心思想:CART回归树样本空间细分成若干子空间,子空间内样本的输出y(连续值)的均值即为该子空间内的预测值。故对于输入X为一维时,预测结果可表示为阶梯函数。
基本概念:属于某个数据集,c为该数据上输出向量y的均值。
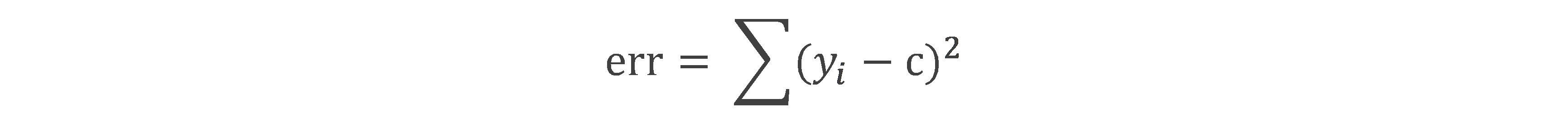
算法流程:
Input:阈值epsilon,最少样本量min_sample,训练数据集X,y
Output: CART回归树
l Step1: 构建特征集,空树
l Step2: 递归构建二叉树。
递归终止条件:
1. 子数据集大小小于min_sample
2. 切分后存在子数据集大小不足2
3. 切分后两个子数据集的平方误差和小于epsilon
树的构建流程:
1. 以每个特征j及相应的取值s为切分点,将数据集划分成左右两个子数据集,计算两个子数据集的平方误差。
2. 取平方误差最小的(j, s),构建二叉树的节点
3. 调用步骤1,2,递归对两个子数据集划分
l Step3: 预测
"""
CART+最小二乘法构建CART回归树
"""import numpy as npclass node:def __init__(self, fea=-1, val=None, res=None, right=None, left=None):self.fea = feaself.val = valself.res = resself.right = rightself.left = leftclass CART_REG:def __init__(self, epsilon=0.1, min_sample=10):self.epsilon = epsilonself.min_sample = min_sampleself.tree = Nonedef err(self, y_data):# 子数据集的输出变量y与均值的差的平方和return y_data.var() * y_data.shape[0]def leaf(self, y_data):# 叶节点取值,为子数据集输出y的均值return y_data.mean()def split(self, fea, val, X_data):# 根据某个特征,以及特征下的某个取值,将数据集进行切分set1_inds = np.where(X_data[:, fea] <= val)[0]set2_inds = list(set(range(X_data.shape[0]))-set(set1_inds))return set1_inds, set2_indsdef getBestSplit(self, X_data, y_data):# 求最优切分点best_err = self.err(y_data)best_split = Nonesubsets_inds = Nonefor fea in range(X_data.shape[1]):for val in X_data[:, fea]:set1_inds, set2_inds = self.split(fea, val, X_data)if len(set1_inds) < 2 or len(set2_inds) < 2: # 若切分后某个子集大小不足2,则不切分continuenow_err = self.err(y_data[set1_inds]) + self.err(y_data[set2_inds])if now_err < best_err:best_err = now_errbest_split = (fea, val)subsets_inds = (set1_inds, set2_inds)return best_err, best_split, subsets_indsdef buildTree(self, X_data, y_data):# 递归构建二叉树if y_data.shape[0] < self.min_sample:return node(res=self.leaf(y_data))best_err, best_split, subsets_inds = self.getBestSplit(X_data, y_data)if subsets_inds is None:return node(res=self.leaf(y_data))if best_err < self.epsilon:return node(res=self.leaf(y_data))else:left = self.buildTree(X_data[subsets_inds[0]], y_data[subsets_inds[0]])right = self.buildTree(X_data[subsets_inds[1]], y_data[subsets_inds[1]])return node(fea=best_split[0], val=best_split[1], right=right, left=left)def fit(self, X_data, y_data):self.tree = self.buildTree(X_data, y_data)returndef predict(self, x):# 对输入变量进行预测def helper(x, tree):if tree.res is not None:return tree.reselse:if x[tree.fea] <= tree.val:branch = tree.leftelse:branch = tree.rightreturn helper(x, branch)return helper(x, self.tree)if __name__ == '__main__':import matplotlib.pyplot as pltX_data_raw = np.linspace(-3, 3, 50)np.random.shuffle(X_data_raw)y_data = np.sin(X_data_raw)X_data = np.transpose([X_data_raw])y_data = y_data + 0.1 * np.random.randn(y_data.shape[0])clf = CART_REG(epsilon=1e-4, min_sample=1)clf.fit(X_data, y_data)res = []for i in range(X_data.shape[0]):res.append(clf.predict(X_data[i]))p1 = plt.scatter(X_data_raw, y_data)p2 = plt.scatter(X_data_raw, res, marker='*')plt.legend([p1,p2],['real','pred'],loc='upper left')plt.show()
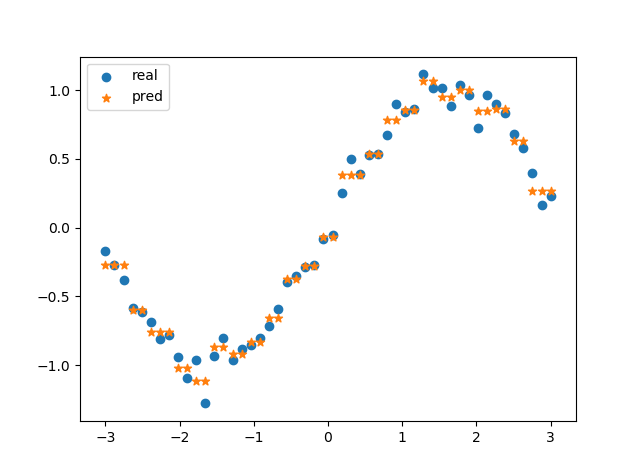
预测结果示例:
[我的GitHub](https://github.com/Shi-Lixin)
注:如有不当之处,请指正。
这篇关于分类回归——CART分类与回归以及Python实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








