本文主要是介绍舒服,又偷学到一个高并发场景面试题的解决方案。,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
高并发 PV 问题
他的文章标题是这样的:

首先他给出了一个业务场景:在一些需要统计 PV(Page View), 即页面浏览量或点击量高并发系统中,如:知乎文章浏览量,淘宝商品页浏览量等,需要统计相应数据做分析。
比如我的公众号阅读量大概在 3000 左右,如果要统计我这种小号主的 PV 其实就很简单,就用 Redis 的 incr 命令轻轻松松就实现了。
但是,假设微信公众号每天要统计 10 万篇文章,每篇文章的访问量 10 万,如果采用 Redis 的 incr命令来实现计数器的话,每天 Redis=100 亿次的写操作,按照每天高峰 12 小时来算,那么 Redis 大约 QPS=57万。
如此大的并发量,CPU 肯定满负载运行,网络资源消耗也巨大,所以直接使用 incr 命令这种技术方案是行不通的。
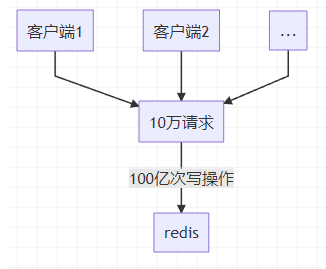
假设这是一个面试场景题,你会怎么去回答呢?
其实你也别想的有多复杂,剥离开场景,这无外乎就是一个高并发的问题。
而高并发问题的解决方案,基本上逃不过这三板斧:缓存、拆分、加钱。
所以这个老哥给出的方案就是:缓存。
二级缓存
Redis 都已经是缓存了,那么再加缓存算什么回事呢?
那就算是二级缓存了。
而且这个缓存,就在 JVM 内存里面,比 Redis 还快。
其核心思想是减少 Redis 的访问量。这些理论的东西,大家应该都知道。
那么通过什么方案去减少 Redis 的访问量呢,这个二级缓存应该怎么去设计呢?
首先,文章服务采用了集群部署,在线上可以部署多台。
然后每个文章服务,增加一级 JVM 缓存,即用 Map 存储在 JVM,key 为当前请求所属的时间块。
就是这个意思:
Map<Long,Map<Integer,Integer>> = Map<时间块,Map<文章id,访问量>>
但是我觉得巧妙的地方在于这里提到的“时间块”的概念。
什么是时间块?
就是把时间切割为一块块,例如
这篇关于舒服,又偷学到一个高并发场景面试题的解决方案。的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





