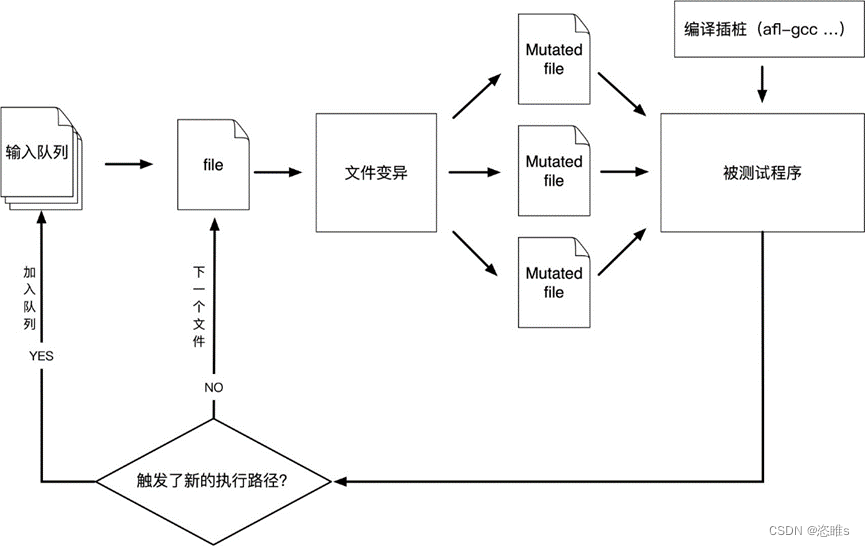
本文主要是介绍AFL入门教学——插桩、执行、覆盖率收集与反馈,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- AFL(American Fuzzy Lop)是一个面向安全的模糊测试工具,它使用编译时插桩技术和遗传算法,可以自动发现触发目标二进程程序的测试用例,从而大大提高测试代码的功能覆盖率。
- 本文主要讲述AFL是如何实现插桩的,如何对覆盖率进行收集的,以及如何利用覆盖率指导种子进行变异的。
一、插桩
- 使用AFL对目标程序进行测试时,首先需要通过afl-gcc/afl-clang等工具对其进行编译,并且在这个过程中会对其进行插桩。
1、afl-gcc.c
- 这里以afl-gcc为例。afl-gcc.c其实就是gcc的一个包装。尝试打印afl-gcc在编译文件时所执行的所有命令行参数。
-
gcc test.c -B /root/src/afl-2.52b -g -O3 -funroll-loops -D__AFL_COMPILER=1 -DFUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION=1 - 可以看出,afl-gcc调用了gcc,并定义了一些宏,设置了一些参数。
- 其中最关键的是:-B /root/src/afl-2.52b。-B 选项用于设置编译器的搜索路径,这里设置成了 /root/src/afl-2.52b,也就是afl-as的路径。
-
- 把源文件编译成二进制文件,需要经过“源代码 -> 汇编代码 -> 二进制代码”的过程。将汇编代码编译成二进制代码就需要使用到汇编器。Linux系统下常用的汇编器为as。AFL目录下也有一个as文件,其作为一个符号链接指向了afl-as。
- 从afl-gcc.c的main中也能看出这点。
- 所以-B 选项的设置是为了把afl-as作为汇编器来使用。而AFL插桩,就是在源代码编译为汇编代码后,由afl-as完成的。
- 下图为gcc的编译流程,只不过在第三阶段时,将as替换为了afl-as。


2、afl-as.c
- afl-as又是如何实现插桩的呢?阅读afl-as.c。其大致逻辑是处理汇编代码,在程序代码段中的每个基本块插入了桩代码,并最终再调用as进行真正的汇编。具体插入代码的部分如下:

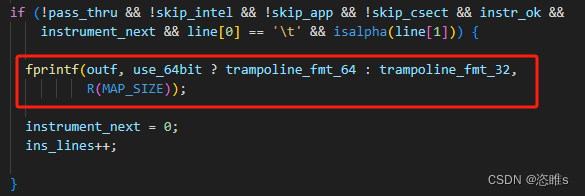
- 这里通过fprintf()将格式化字符串添加到汇编文件的相应位置。其中trampoline_fmt_64和trampoline_fmt_64是定义的汇编代码,也就是桩代码。
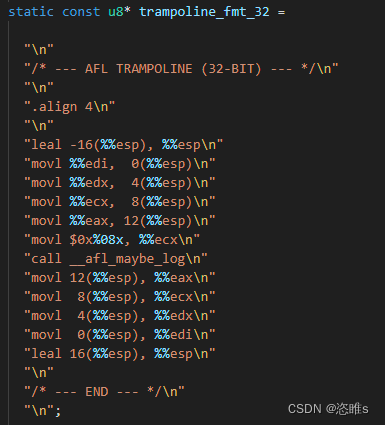

- 功能:
- 保存一些寄存器的值
- 将生成的随机数保存在ecx/rcx中
- 调用__afl_maybe_log()
- 恢复寄存器
-
fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE));- 其中R(MAP_SIZE))是ecx/rcx要设置的值。MAP_SIZE定义为64K,R(x)定义为(random() % (x)) ,故R(MAP_SIZE))为0~64K的一个随机数。
- 所以,在一个基本块中插入桩代码时,afl-as会生成一个随机数,保存在ecx/rcx中,用来标记该基本块。
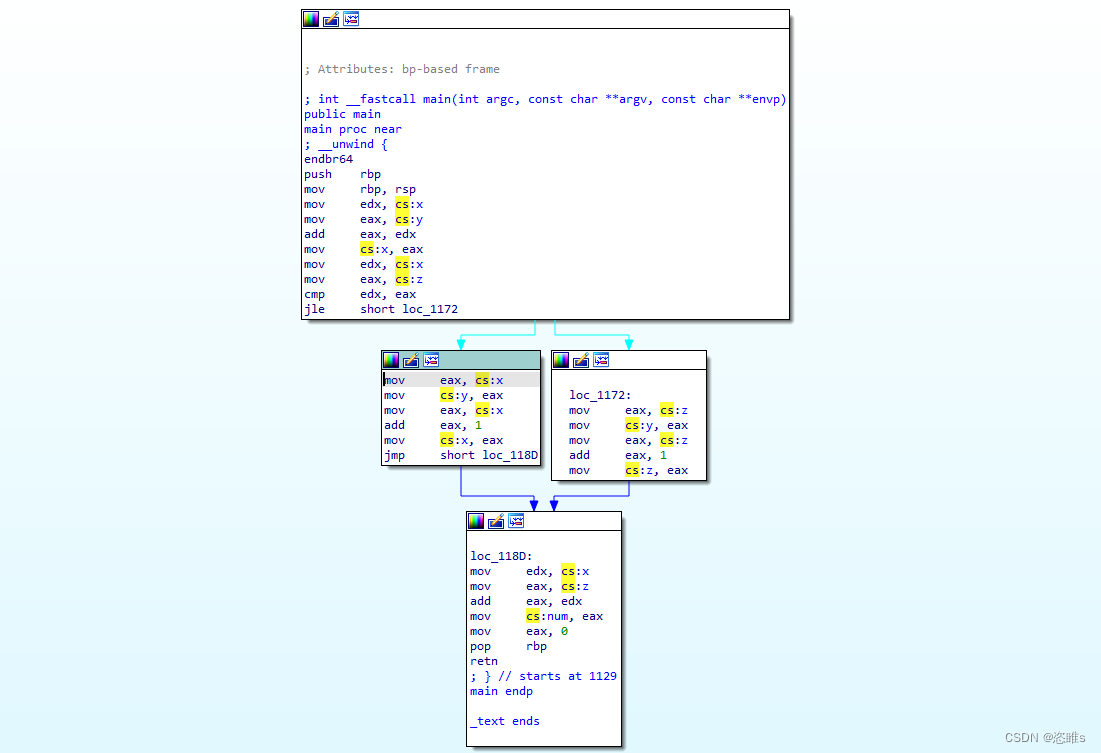
2.1、基本块
- 基本块 (BB)指一组顺序执行的指令,BB中第一条指令被执行后,后续的指令也会被全部执行,每个BB中所有指令的执行次数是相同的,也就是说一个BB必须满足以下特征:
- 只有一个入口,BB中的指令不是任何跳转指令的目标。
- 只有一个出口,只有最后一条指令执行完跳到另一个BB中。
- 例如,下面代码分为4个基本块。
二、执行
- 编译完目标程序后,就可以进行fuzzing了。(本文只讲述了第一次fuzzing)
1、afl-fuzz.c
- 在main中,首先会对所有初始测试用例进行试运行。(本文未提及对种子的变异操作)
- 在perform_dry_run()中,会对测试用例进行了一次测试,以检测测试用例是否有问题需要校准。
- 校验测试用例,就需要将这个测试用例输入到目标程序中运行。首先需要初始化fork server。
2、fork server
- 为了更高效地进行上述过程,AFL实现了一套fork server机制。其基本思路是:启动目标进程后,目标会运行一个fork server。afl-fuzz不需要负责fork子进程,只需要与这个fork server通信,并由fork server来完成fork及继续执行目标的操作。
- 简单来说,当执行第一个基本块时会启动fork server,afl-fuzz和fork server之间通过管道通信,每当afl-fuzz生成一个测试用例,就会通知fork server去fork一个子进程,然后子进程会从fork server的位置继续往下执行并处理数据,而fork server则继续等待afl-fuzz的请求。
- 下面讲述fork server的具体运行原理:
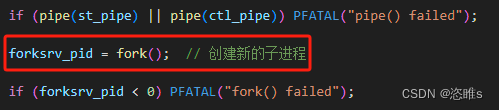
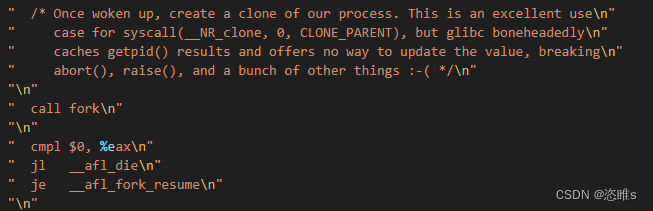
- 首先,afl-fuzz执行fork()得到父进程和子进程,父进程为afl-fuzz,子进程为fork server。
- 父子进程之间,是通过管道进行通信。具体使用了2个管道,一个用于传递状态,另一个用于传递命令。
- 对于子进程(fork server),会进行一系列设置,其中包括将上述两个管道分配到预先指定的文件描述符 (fd),并最终执行目标程序。
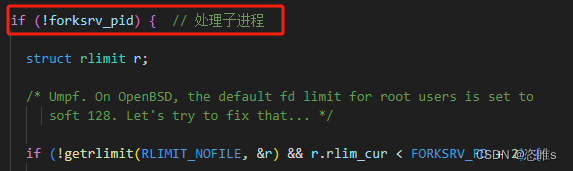


- 【注】内核利用文件描述符 (fd)来访问文件。文件描述符是非负整数。打开现存文件或新建文件时,内核会返回一个文件描述符。读写文件也需要使用文件描述符来指定待读写的文件。
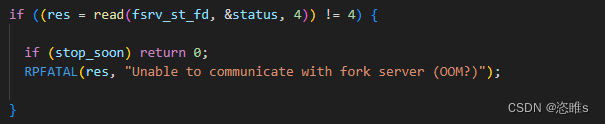
- 对于父进程(afl-fuzz),则会读取状态管道的信息,如果一切正常,则说明fork server创建完成。
- 首先,afl-fuzz执行fork()得到父进程和子进程,父进程为afl-fuzz,子进程为fork server。
- 下面讲述afl-fuzz是如何与fork server进行通信的:
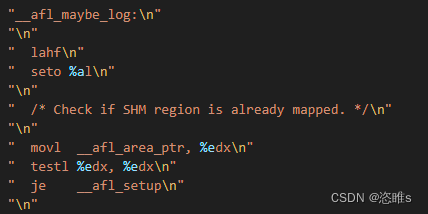
- fork server的实现过程,是插桩代码中调用的_afl_maybe_log()函数(afl-as.h)实现的。
- _afl_maybe_log:用于保护现场和检查共享内存是否以分配。
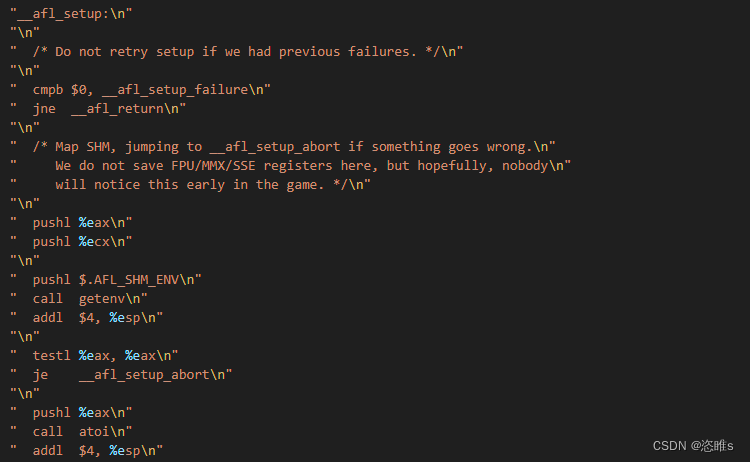
- 如已分配,则跳转到__afl_setup。初始化共享内存指针等。
- 如一切顺利,则进入_afl_forkserver。
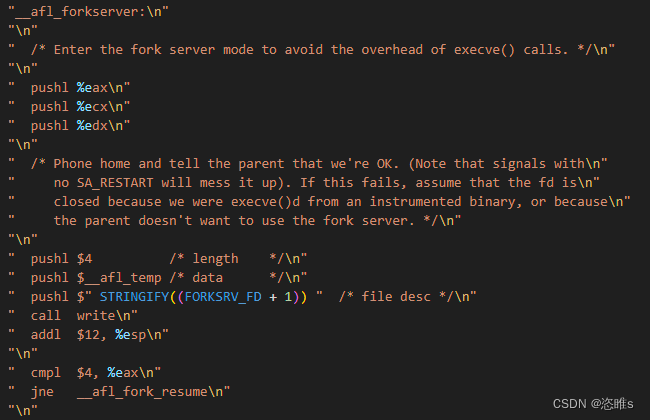
- 首先,通过写入状态管道,fork server会通知afl-fuzz,其已经准备完毕,可以开始fork了。上面则父进程等待的信息。
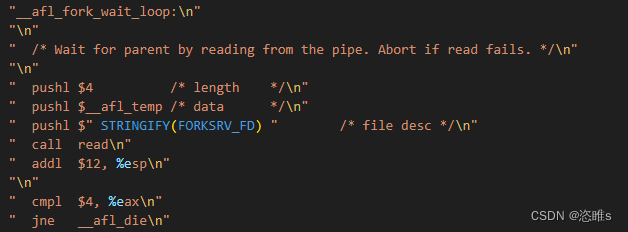
- 然后,fork server进入等待状态__afl_fork_wait_loop,读取命令管道,直到afl-fuzz通知其开始fork。
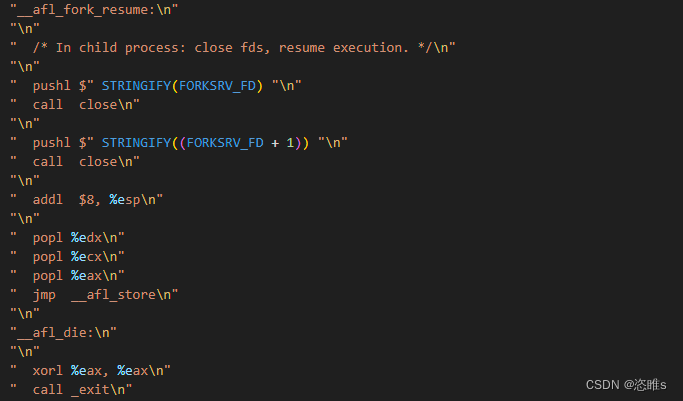
- 一旦fork server接收到afl-fuzz的信息,便调用fork(),得到一个子进程(目标进程)。
- 子进程(目标进程)则跳转执行 __afl_fork_resume,该函数会关闭不需要的管道并恢复现场。然后执行__afl_store(该函数用于记录命中桩代码的次数,并计算覆盖率,后面再讲)。
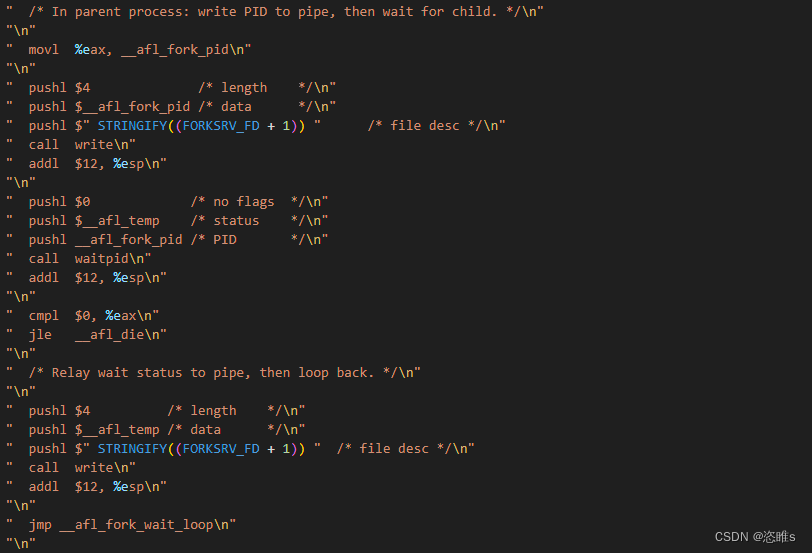
- 子进程(目标进程)执行期间,fork server会将子进程的pid通过状态管道发送给afl-fuzz,并执行waitpid等待子进程执行完毕。一旦子进程(目标进程)执行完毕,fork server则再通过状态管道,将其结束状态发送给afl-fuzz。之后再次进入__afl_fork_wait_loop,重新循环操作。
- _afl_maybe_log:用于保护现场和检查共享内存是否以分配。
- 父进程(afl-fuzz)的实现过程,就是在fork server启动完成后,一旦需要执行某个测试用例,就调用run_target()方法。
- run_target()方法会通过命令管道,通知fork server准备fork,并通过状态管道,获取子进程(目标进程)的pid。
- 之后,afl-fuzz再次读取状态管道,获取子进程的退出状态,并由此来判断子进程结束的原因,例如正常退出、超时、崩溃等,并进行相应的记录。
- run_target()方法会通过命令管道,通知fork server准备fork,并通过状态管道,获取子进程(目标进程)的pid。
- fork server的实现过程,是插桩代码中调用的_afl_maybe_log()函数(afl-as.h)实现的。


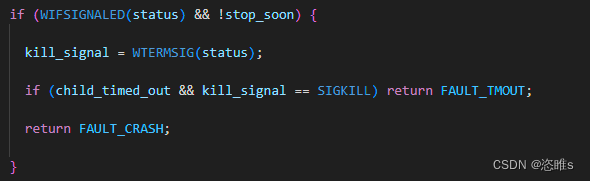
三、内存共享
- AFL最大的特点是可以通过覆盖率来指导种子的变异。也就是AFL对目标代码插桩编译再执行时,会收集执行过程中的分支信息,即覆盖率。
- AFL使用共享内存来实现alf-fuzz和目标程序之间的信息传递。
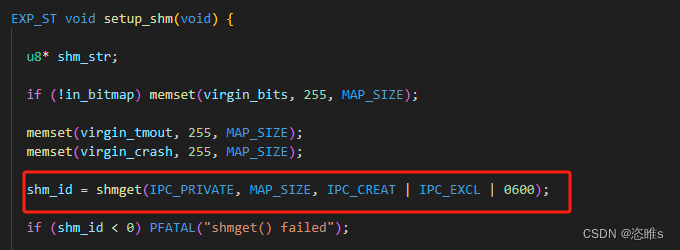
- afl-fuzz.c的main中会调用setup_shm()来配置共享内存。
- 该函数中,首先会调用shmget()分配一块大小为64KB(MAP_SIZE=64K)的共享内存。
- 分配成功后,该共享内存的标志符会被设置到环境变量中,从而之后fork()得到的子进程可以通过该环境变量,得到这块共享内存的标志符。
- afl-fuzz也会使用变量 trace_bits 保存该共享内存地址。
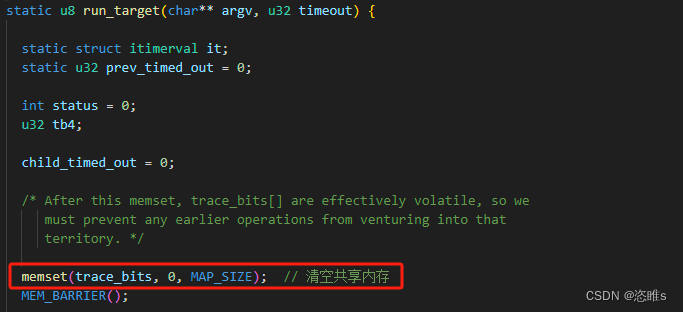
- 并且每次执行目标进程时,首先会将该共享内存清零。
- afl-fuzz.c的main中会调用setup_shm()来配置共享内存。
- 接下来讲述目标进程时如何获取并使用这块共享内存的。同样也是在_afl_maybe_log()函数(afl-as.h)实现的。
- 首先会检查共享内存是否映射完成。
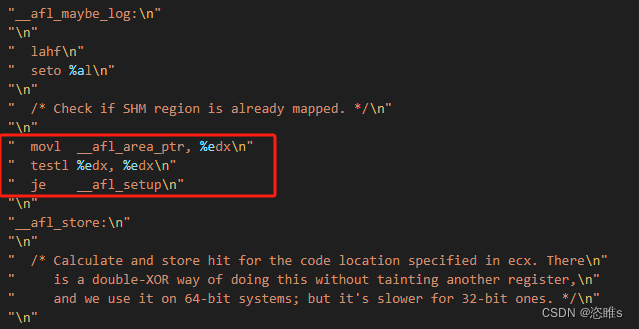
- __afl_area_ptr中保存的就是共享内存映射到目标进程的内存空间中的地址,如果非空,则保存在ebx中继续执行;否则跳转到__afl_setup。
- __afl_setup会做一些错误检查,然后获取环境变量AFL_SHM_ENV的内容并将其转为整型。AFL_SHM_ENV存放的是之前afl-fuzz保存的共享内存的标志符。
-
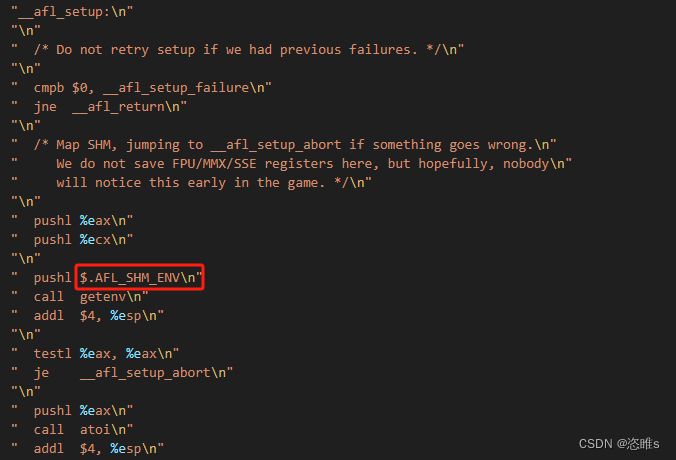
-
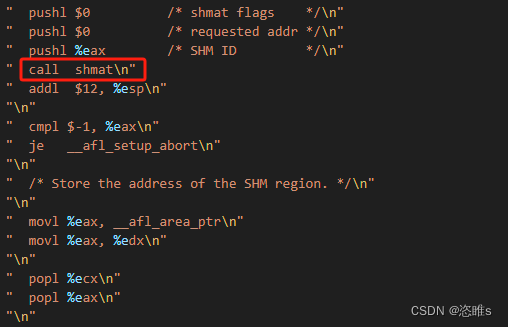
- 最后目标进程调用shmat()函数,将这块共享内存也映射到了自己的内存空间中,之后将其地址保存在__afl_area_ptr和edx中。
- 以上就完成了afl-fuzz与目标进程之间共享内存的设置。
- 【注】如果是fork server模式,那么上述获取共享内存的操作,是在fork server中进行。之后fork出来的子进程(目标进程),只需直接使用这个共享内存即可。
- 首先会检查共享内存是否映射完成。


四、覆盖率收集与反馈
1、分支信息记录
- 上面已经讲述了afl-fuzz与子进程使用内存共享进行通信,通信的内容是执行流程和代码覆盖情况。那AFL是如何记录这些信息的呢?
- AFL通过插桩代码捕获边 (edge)覆盖率。什么是边呢?将程序看成一个控制流图,图的每个节点表示一个基本块,而边表示在基本块之间的转跳。知道了每个基本块和跳转的执行次数,就可以知道程序中的每个语句和分支的执行次数,从而获得比记录基本块更细粒度的覆盖率信息。
- 而AFL是利用二元组(当前基本块+前一基本块)来记录分支(边)信息的,其伪代码如下:
-
cur_location = <COMPILE_TIME_RANDOM>; // 用一个随机数标记当前基本块 shared_mem[cur_location ^ prev_location]++; // 将当前块和前一块异或保存到shared_mem数组(共享内存)对应的位置 prev_location = cur_location >> 1; // cur_location右移1位赋给prev_location,原因看下方
-
- 信息收集也是在_afl_maybe_log()函数中完成的。当afl-fuzz保存了共享内存地址并且完成了fork server的初始操作后,会调用__afl_store(32位是ecx,64位是rcx,下面以64为例)。

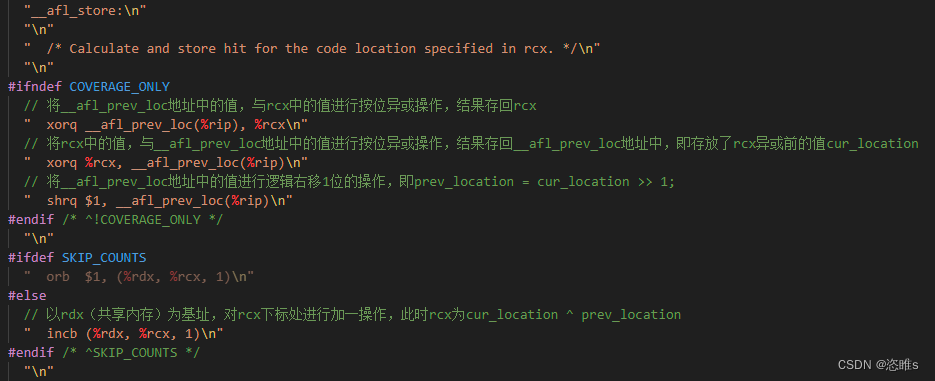
- 其中,rcx 开始保存的是 cur_location,然后保存的是 cur_location ^ prev_location。__afl_prev_loc 开始保存的是伪代码中的 cur_location,之后右移了1位,变成了 prev_location。
- 回顾前面插桩时做的操作,R(MAP_SIZE) 生成了一个 0~64K 的随机数,并保存到了 rcx 中。这就实现了伪代码中的 cur_location = <COMPILE_TIME_RANDOM> 操作。
- 【原理】
- AFL为每一个代码块生成了一个随机数,用于标记其位置。之后对分支处的当前块和前一块的位置(随机数)进行异或操作,并将异或结果作为该分支的key。当该分支被执行,共享内存中的对应位置就会 +1(用1Byte储存分支的执行次数),实际就是哈希表的映射。共享内存保存的是一张哈希表,哈希表中记录的是边覆盖率和分支的执行次数。
- 因为使用的是哈希算法,所以会存在碰撞问题。但如果目标程序不是太复杂的话,碰撞概率也不会很高。
- 另外,为什么需要将 cur_location 右移1位后,再保存到 prev_location 中?
- 如果存在 A -> A 或 B -> B 这样的跳转,如果不右移的话,那这两个分支异或的值都是0,无法区分。
- 如果存在 A ->B 和 B -> A 这样的跳转,如果不右移的话,那这两个分支异或的值是相同的,也无法区分。
- 当目标进程执行结束后,afl-fuzz便开始对这张表进行分析,从而判断代码的执行情况。
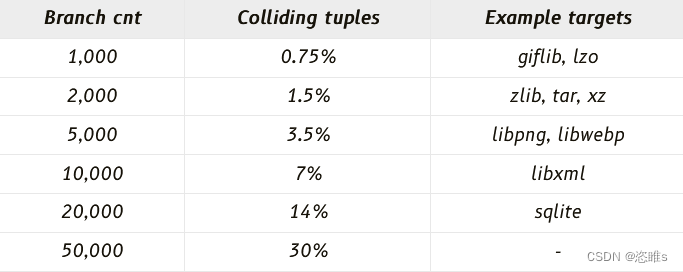
2、分支信息分析
- 在执行目标进程的最后,会调用classify_counts()先对共享内存中的执行次数进行重新计数,传入的参数trace_bits即为共享内存的地址。

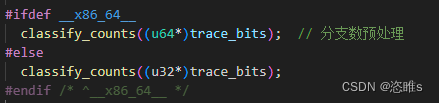 (这里将trace_bits强制转换为了64位的指针,也就是一次读取8字节)
(这里将trace_bits强制转换为了64位的指针,也就是一次读取8字节)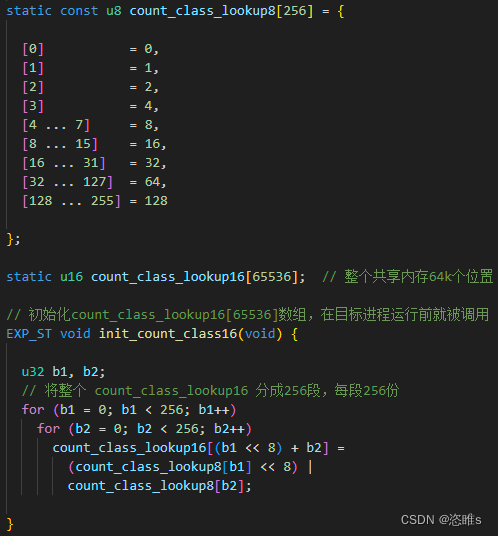
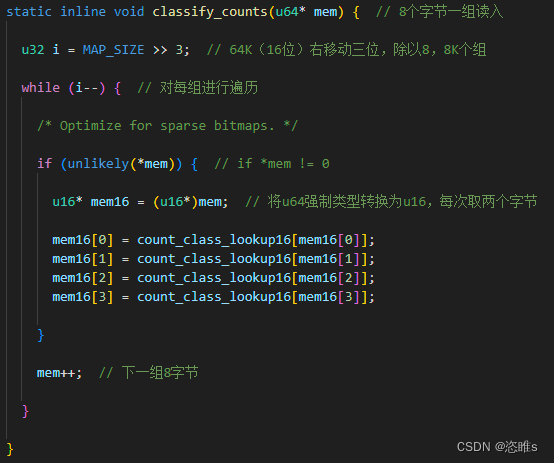
- 实际就是对分支执行次数进行分类。例如,执行了4~7次的计数为8,32~127次的计数为64。
- 目的是处理一些微小误差,而被误判为不同执行结果的情况。例如,分支A执行了32次;对另外一个测试用例,分支A执行了33次,那么AFL就会认为这两次的代码覆盖是相同的。因为它们都被处理为了64。
- 【注】使用 count_class_lookup16 是因为AFL在后面实际进行规整的时候,是一次读两个字节去处理的,为了提高效率,这只是出于效率的考量。
- 目标进程执行完后,会调用hash32计算共享内存的hash值。
- 对于某些突变的种子,如果执行没有出现崩溃等异常输出,afl-fuzz还会检查其是否新增了执行路径。而通过比较hash值,就可以判断trace _bits(共享内存)是否发生了变化,从而判断此次突变种子是否带来了新路径,为之后的fuzzing提供参考信息。

这篇关于AFL入门教学——插桩、执行、覆盖率收集与反馈的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




