本文主要是介绍Labelimg打标工具编译版使用介绍——免安装conda等python虚拟环境,简单易用上手快,不容易报错,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
首先直接给出免积分的下载地址,开源软件,直接共享给csdn的各位开发者,求个三连不过分吧。点赞关注收藏。谢谢各位支持
资源地址如下
1打开D:\xxxxx\labelImg\data内的predefined_classes.txt文件,
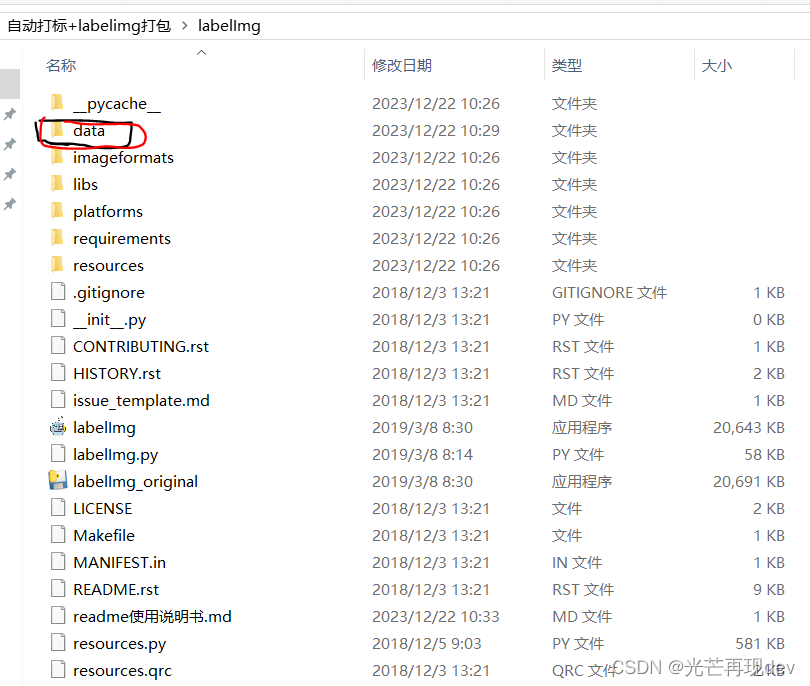
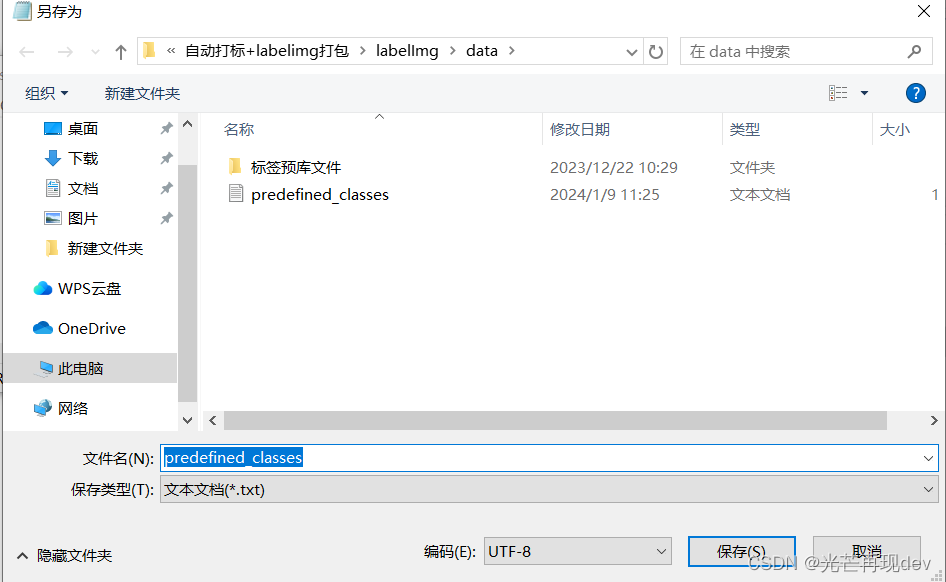
修改其中的类别为自己需要的,然后保存,这个data文件夹里面的txt文件保存的格式为UTF-8,这个通过记事本另存为就可以进行修改的(记事本——>另存为——>选择编码“UTF-8”)

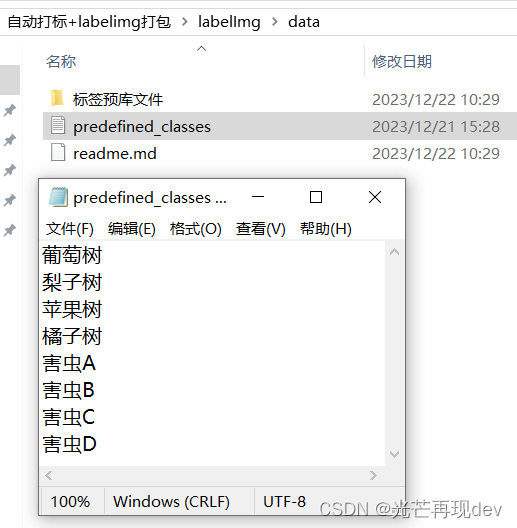
此外需要注意!!!数据集文件夹(其结构如下图所示,一个用于存放需要标注的图像——jpg文件夹,一个用于存放coco格式的yolo数据集文件——coco文件夹,其中coco文件夹内必须要有classes.txt文件,且其编码必须指定为ANSI格式,其内容需要和前文提到的data文件夹中的predefined_classes.txt(UTF-8编码格式)里面的内容保持一致,但是编码不一样,请注意这一点不一样的区别之处)
里面的classes.txt的格式为ANSI 编码,右键这个txt文件,点击记事本打开编辑,点击记事本中的文件,点击另存为,右小角选自保存的编码即可。

确保接下来双击运行labelimg.exe,即可进入labelimg标注的页面

打开主页面以后,会发现这个编译版本和我们直接通过如下命令
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple安装的效果是一样的。但是这个编译版本的有点就在于比较稳定和不容易报错。

点击上图所示的1标志,进入选择图像目录

这里jpg文件夹内选择存放有水果树害虫图像的数据集,jpg格式的图像

接下来需要选择存放coco数据集的文件夹
我们点击2的Change Save Dir
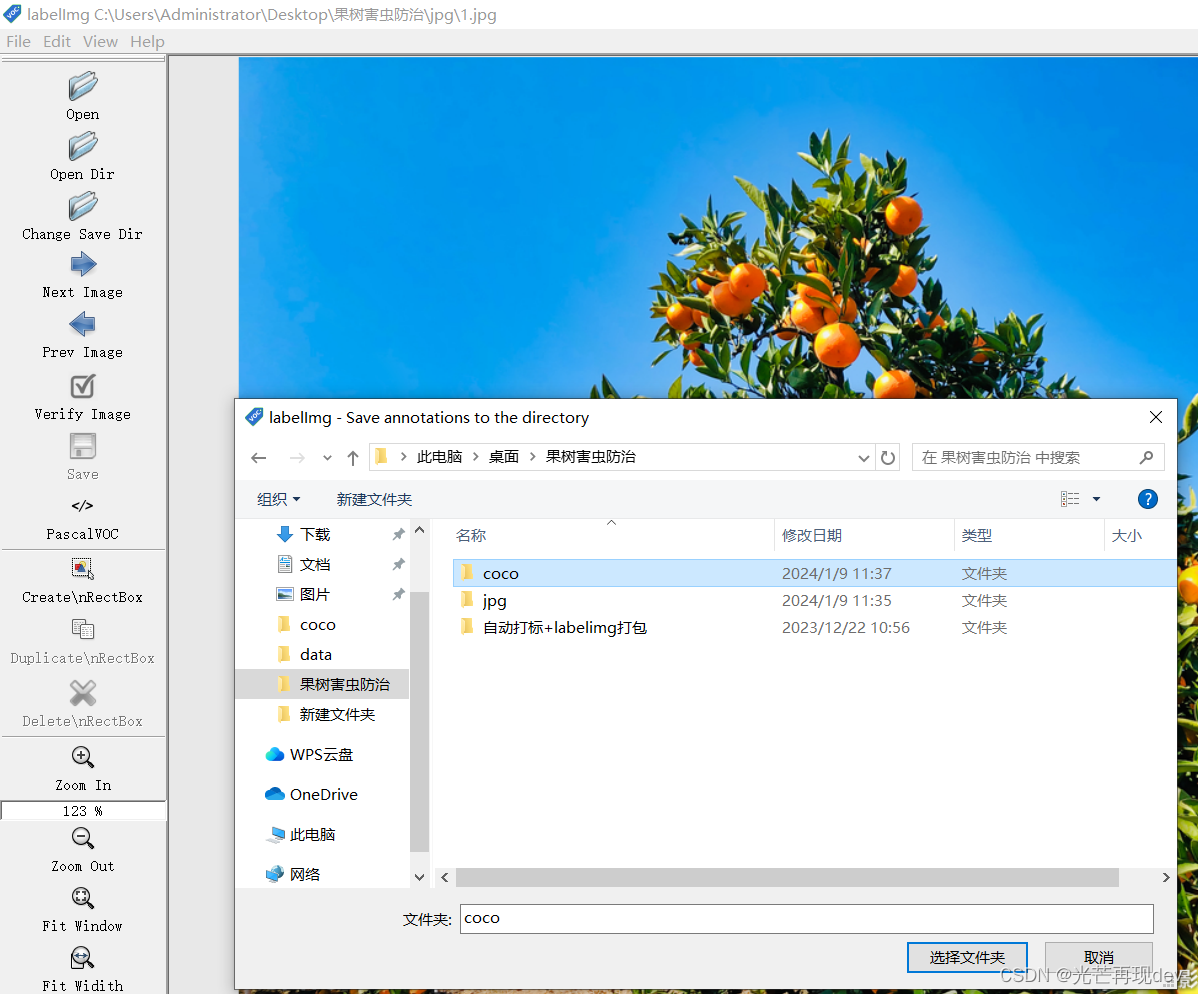
coco文件夹当中已经存放有一个classes.txt文件(ANSI编码格式)

接下来点击3,将PascalVOC改为YOLO格式的数据集


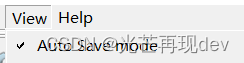
然后点击上面的工具栏中打开Auto-save-mode开启自动保存模式,依次点击view——>Auto Save mode

出现这个“√”对勾的标志就说明成功打开了自动保存标注文件的模式了。
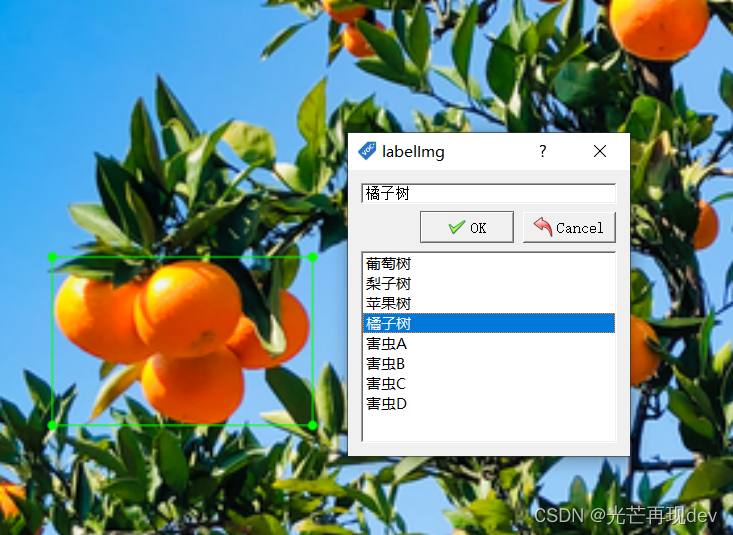
此时会发现,标注的标签,直接下拉即可进行选择,十分方便,因为我们已经在之前的predefined_classes.txt里面定义好了这个内容。
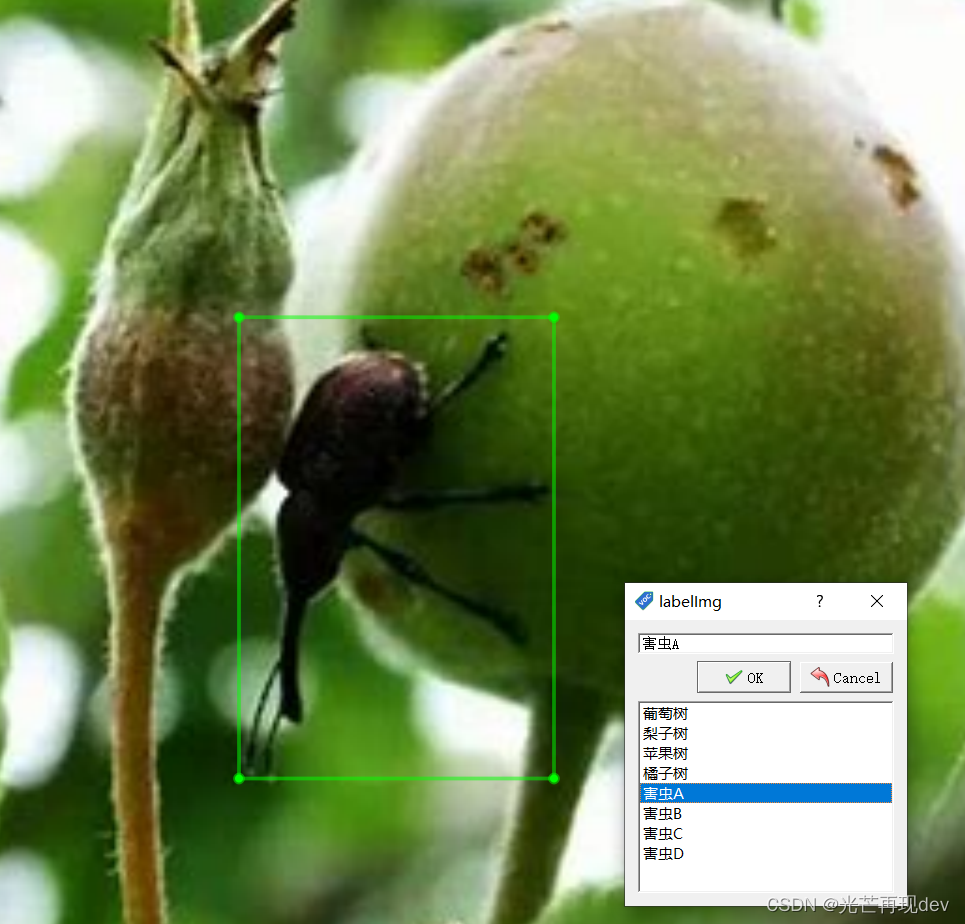
接下来即可开启我们的标注了
这篇关于Labelimg打标工具编译版使用介绍——免安装conda等python虚拟环境,简单易用上手快,不容易报错的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




