本文主要是介绍Spark MLlib ----- ALS算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
补充
在谈ALS(Alternating Least Squares)之前首先来谈谈LS,即最小二乘法。LS算法是ALS的基础,是一种数优化技术,也是一种常用的机器学习算法,他通过最小化误差平方和寻找数据的最佳匹配,利用最小二乘法寻找最优的未知数据,保证求的数据与已知的数据误差最小。LS也被用于拟合曲线,比如所熟悉的线性模型。
下面以简单的线性一元线性回归模型说明最小二乘法。假设我们有一组数据{(x1,y1),(x2,y2),(x3,y3)…}其符合线性回归,
假设其符合的函数为如下:
y = w0 + w1 x
我们使用一个平方差函数来表达参数的好坏,平方差函数如下:
Ln = (yn - f(x;w0,w1))2
其中:
y: 目标变量或响应变量,是模型要预测的值。
x: 特征或自变量,是用来预测目标变量的输入。
w1:斜率,表示每单位x变化时y的变化量。
w0 :截距项,线性回归中表示直线与y轴的交点。
f(x;w0,w1): 线性回归模型的方程,表示预测y的函数,其中f 是模型,x 是输入特征w1和w0是模型的参数。
Ln:损失函数,用于衡量模型在给定数据点xn,yn处的预测值, f(x;w0,w1)与实际观测值 yn之间的差异。
L越小表示参数w越精确,而这里最关键的就是寻找到最合适的w0,w1,则此时的数学表达式为:

将先行回归函数代入到最小二乘损失函数中,得到的结果为:
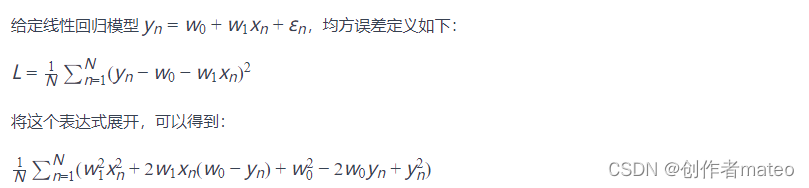
介绍完了LS,现在展开来说ALS算法。ALS算法本质上是基于物品的协同,近年来,基于模型的推荐算法ALS(交替最小二乘)在Netflix成功应用并取得显著效果提升,ALS使用机器学习算法建立用户和物品间的相互作用模型,进而去预测新项。
一、概念
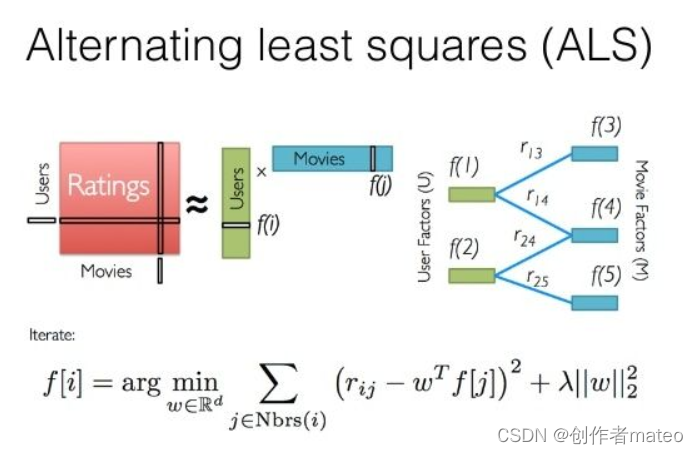
ALS(Alternating Least Squares)是一种协同过滤推荐算法,主要用于处理推荐系统中的矩阵分解问题。它的基本思想是通过交替最小二乘法(Alternating Least Squares)来迭代地优化用户矩阵和物品矩阵。由于简单高效,已被广泛应用在推荐场景中,目前已经被集成到Spark MLlib和ML库中
二、算法概括
- ALS算法用来补全用户评分矩阵。由于用户评分矩阵比较稀疏,将用户评分矩阵进行分解,变成V和U的乘积。通过求得V和U两个小的矩阵来补全用户评分矩阵。
- ALS算法使用交替最小二乘法来进行求解。
- ALS分为显示反馈和隐式反馈两种。显示反馈是指用户有明确的评分。对于商品推荐来说,大部分是通过用户的行为,获取隐式反馈的评分。隐式反馈评分矩阵需要进行处理,如果有用户评分则置为1,没有则赋值为0。但是对这个处理后的评分矩阵,再有一个置信度来评价这个评分。置信度等于1+a*用户真实评分
- ALS的代价函数是估计值和现有的评分值误差的平方和,引入了L2正则。
2.1 协同过滤
协同过滤(Collaborative Filtering)是一种推荐系统的方法,通过分析用户的行为、偏好或兴趣,向用户推荐与其相似的其他用户喜欢的项目。其核心思想是基于用户之间的相似性或项目之间的相似性来进行推荐。
协同过滤分为两类:****基于用户的协同过滤和基于项目的协同过滤。
1. 基于用户的协同过滤(User-Based Collaborative Filtering):
找出和目标用户兴趣相似的其他用户。如果两个用户在过去喜欢或不喜欢的项目上有相似的评价,那么在未来可能也会对相同或类似的项目有相似的兴趣。根据相似用户的行为给目标用户进行推荐。
2. 基于项目的协同过滤(Item-Based Collaborative Filtering):
找出与目标项目相似的其他项目。如果用户喜欢某个项目,那么他们可能也会喜欢与该项目相似的其他项目。根据相似项目的特性给用户进行推荐。
协同过滤的优势在于不需要事先对用户或项目进行明确的描述,而是通过用户行为数据来自动学习用户的偏好。然而,它也面临一些挑战,如稀疏性、冷启动问题(新用户或新项目如何进行推荐)、计算复杂度等。
2.1.1 协同过滤实现
要实现协同过滤的推荐算法,要进行以下三个步骤:
- 收集数据: 首先,需要获取用户对物品(如电影、图书、商品等)的评价数据。这些评价可以是用户的打分、购买历史、点击记录等。通常,这些数据是通过用户的交互行为收集的。
- 找到相似用户和物品:
- 基于用户的协同过滤: 计算用户之间的相似性,通常使用一些相似性度量如余弦相似度或皮尔逊相关系数。找到与目标用户相似的其他用户,然后根据相似用户的行为给目标用户进行推荐。
- 基于物品的协同过滤: 计算物品之间的相似性,同样使用余弦相似度或其他度量。找到与目标物品相似的其他物品,然后将这些相似物品推荐给用户。
- 以下是几种计算相似度的方法:
-
欧几里德距离:
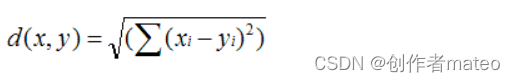
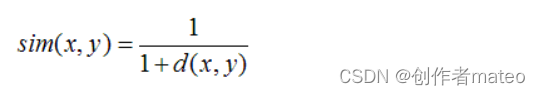
-
皮尔逊相关系数
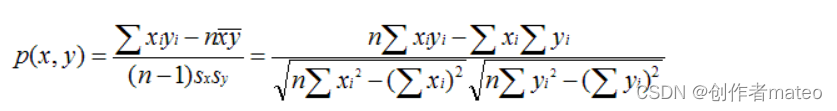
-
Cosine 相似度
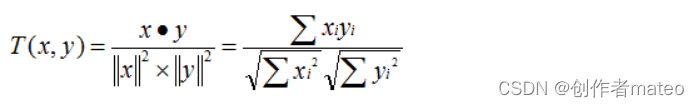
-
Tanimoto 系数
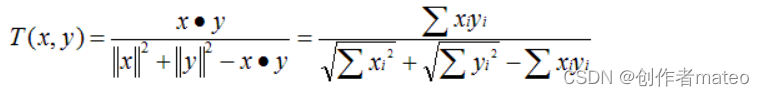
-
- 进行推荐:
- 对于基于用户的协同过滤,可以根据相似用户的历史行为给目标用户推荐未看过的物品。
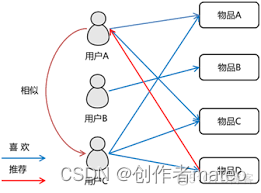
- 基于用户的 CF 的基本思想相当简单,基于用户对物品的偏好找到相邻邻居用户,然后将邻居用户喜欢的推荐给当前用户。计算上,就是将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到 K 邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。 下图给出了一个例子,对于用户 A,根据用户的历史偏好,这里只计算得到一个邻居 - 用户 C,然后将用户 C 喜欢的物品 D 推荐给用户 A。
- 对于基于物品的协同过滤,可以将与用户喜欢的物品相似的其他物品推荐给用户。
- 基于物品的 CF 的原理和基于用户的 CF 类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。从计算的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的物品,计算得到一个排序的物品列表作为推荐。下图给出了一个例子,对于物品 A,根据所有用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C,得出物品 A 和物品 C 比较相似,而用户 C 喜欢物品 A,那么可以推断出用户 C 可能也喜欢物品 C。
注意:实际实现中,还需要考虑一些问题,如处理缺失数据、处理冷启动问题(新用户或新物品的推荐)、选择合适的相似性度量等。这些步骤通常在构建推荐系统时需要仔细考虑和调优。
2.1.2 计算复杂度
Item CF(基于物品的协同过滤)和User CF(基于用户的协同过滤)是协同过滤推荐系统中两个基本的策略。它们的性能和适用场景取决于系统的特点。
- Item CF(基于物品的协同过滤):
- 计算物品之间的相似度,然后根据用户过去喜欢的物品找到相似的物品进行推荐。
适用于物品相对稳定,而用户数量较大的场景。
不太受用户数量的影响,计算相似度的复杂度相对较低。
- User CF(基于用户的协同过滤):
- 计算用户之间的相似度,然后根据相似用户的历史行为给目标用户进行推荐。
适用于用户相对稳定,而物品数量较大或更新频繁的场景。
受用户数量影响较大,计算相似度的复杂度可能较高。
选择合适的算法取决于推荐系统所面对的具体情境和需求。在一些情况下,可以采用混合策略,结合两者的优势,以达到更好的推荐效果。例如,在实际应用中,可能会使用一种算法作为主推荐策略,另一种算法作为辅助推荐或冷启动时的备选策略。
User CF 是很早以前就提出来了,Item CF 是从 Amazon 的论文和专利发表之后(2001 年左右)开始流行,大家都觉得 Item CF 从性能和复杂度上比 User CF 更优,其中的一个主要原因就是对于一个在线网站,用户的数量往往大大超过物品的数量,同时物品的数据相对稳定,因此计算物品的相似度不但计算量较小,同时也不必频繁更新。但我们往往忽略了这种情况只适应于提供商品的电子商务网站,对于新闻,博客或者微内容的推荐系统,情况往往是相反的,物品的数量是海量的,同时也是更新频繁的,所以单从复杂度的角度,这两个算法在不同的系统中各有优势,推荐引擎的设计者需要根据自己应用的特点选择更加合适的算法。
所以这就引出来了,应用场景。对于不同的应用场景给出最优的计算方法。
2.1.3 应用场景
在非社交网络的网站中,内容内在的联系确实是推荐的重要原则之一,特别是在购物、阅读等场景下。以下是一些关键点:
- Item CF 在内容相关性强的场景中的优势:
- 当用户在浏览某一内容(比如一本书)时,通过 Item CF 可以很自然地向用户推荐与当前内容相关的其他内容(相关书籍)。
- 这种推荐方式更加符合用户的当前兴趣和行为,有助于引导用户在网站上浏览更多相关内容。
- Item CF 的解释相对容易理解,因为推荐是基于物品之间的相似性,用户可以直观地理解为“因为你喜欢这个,所以我们为你推荐了类似的”。
- User CF 在社交网络站点中的应用:
- 在社交网络站点中,用户之间的社交关系可以用于计算用户之间的相似性,因此 User CF 在这样的场景中更具优势。
- 结合社交网络信息,可以提高用户对推荐解释的信服程度。例如,推荐可以是“因为你的朋友喜欢这个,所以我们认为你可能也会喜欢”。
- 混合策略的可能性:
- 有时候,可以采用混合策略,结合内容推荐和用户行为推荐,以提供更全面和个性化的推荐服务。
- 在不同场景下,可以动态选择合适的推荐算法,以满足用户的多样化需求。
推荐网站《推荐系统之算法综述》
这篇关于Spark MLlib ----- ALS算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








