本文主要是介绍【MindSpore:跟着小Mi机器学习】异常检测(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一周未见,甚是想念,今天小Mi带大家学习异常检测(Anomaly detection)!废话不多说,我们开始吧~
1 定义
异常检测(Anomaly detection)这个算法很有意思:它虽然主要用于非监督学习问题,但从某些角度看,它又和一些监督学习问题很类似。
什么是异常检测:
通常飞机的引擎从生产线上流出时需要进行质量控制测试,作为依据会测试引擎的一些特征变量,比如引擎运转时产生的热量,或者引擎的振动等等。

这样一来,我们就有了一个数据集,从
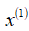
到
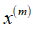
,如果生产了
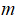
个引擎的话,可以将这些数据绘制成图表:
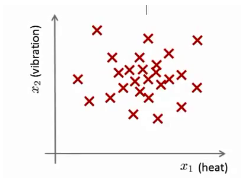
因此,异常检测问题可以定义如下:假设有一个新的飞机引擎从生产线上流出,看似有点异常,赋予其特征变量
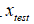
来判断该引擎是否需要进一步的测试。
给定数据集
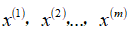
,假使数据集是正常的,我们希望知道新的数据
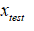
是不是异常的,即这个测试数据不属于该组数据的几率是多少,因此构建的模型需要根据该测试数据来告诉我们其属于这组数据集的可能性
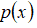
。
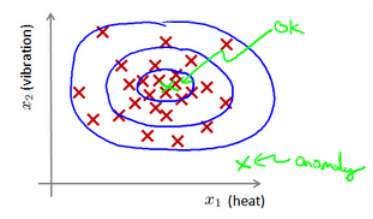
上图中,在蓝色圈内的数据属于该组数据的可能性较高,而越是偏远的数据,其属于该组数据的可能性就越低。
这种方法称为密度估计,表达如下:
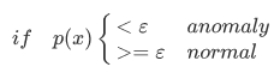
异常检测经常用来识别欺骗。例如在线采集用户的数据,一个特征向量中可能会包含如:用户多久登录一次,访问过的页面,在论坛发布的帖子数量,甚至是打字速度等。尝试根据这些特征构建一个模型,可以用这个模型来识别那些不符合该模式的用户。
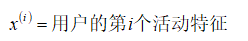
模型
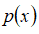
为我们其属于一组数据的可能性,通过
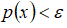
检测非正常用户。
2 正态分布
正态分布其实也可以称之为高斯分布,大家是不是很熟悉。小Mi先带大家回顾下高斯分布的基本知识。
通常认为:变量
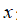
符合高斯分布
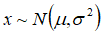
,则其概率密度函数为:
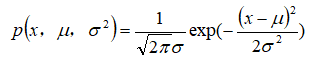
利用已有的数据来预测总体中的
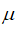
和
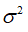
:
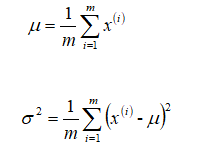
高斯分布样例:
注:机器学习中对于方差我们通常只除以
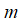
而非统计学中的
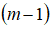
。其实选择
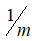
还是
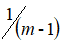
两者之间区别很小,几乎可以忽略不计,在机器学习领域大部分人更习惯使用
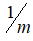
。
3 算法
那么这个时候大家是不是会觉得疑问了,异常检测和正态分布又有什么关系呢?
异常检测算法:
对于给定的数据集
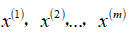
,我们要针对每一个特征计算
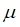
和
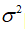
的估计值。
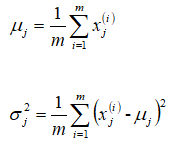
一旦我们获得了平均值和方差的估计值,给定新的一个训练实例,根据模型计算 :
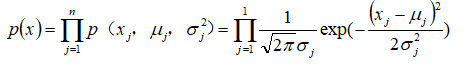
当
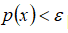
时,为异常。
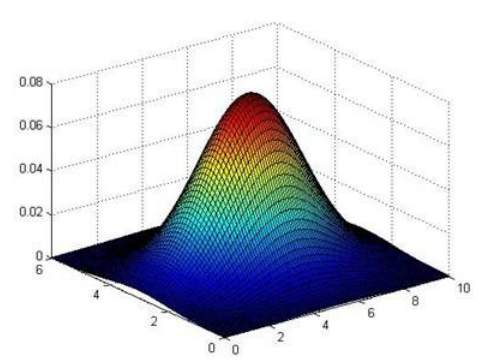
下图是一个由两个特征的训练集,以及特征的分布情况:
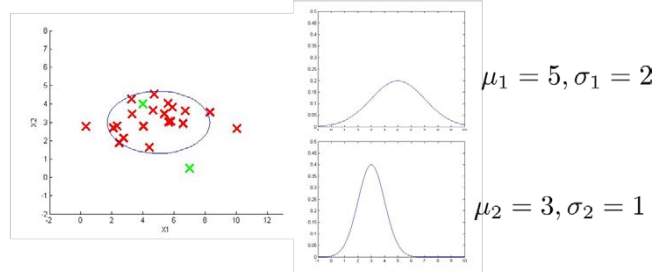
下面的三维图表表示的是密度估计函数,
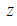
轴为根据两个特征估计的
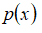
值:
选择一个
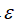
,将
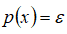
作为判定边界,当
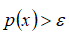
时预测数据为正常数据,否则为异常。
4 异常检测系统
异常检测算法是一种非监督学习算法,意味着无法根据结果变量
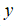
的值来告诉我们数据是否真的是异常的。因此,我们需要另一种方法来帮助检验算法是否有效,开发一个异常检测系统,需要从带标记(异常或正常)的数据着手,选择一部分正常数据用于构建训练集,然后用剩下的正常数据和异常数据混合的数据构成交叉检验集和测试集。
例如:有10000台正常引擎的数据,有20台异常引擎的数据,分配如下:
6000台正常引擎的数据作为训练集
2000台正常引擎和10台异常引擎的数据作为交叉检验集
2000台正常引擎和10台异常引擎的数据作为测试集
具体的评价方法如下:
1.根据测试集数据,可以估计特征的平均值和方差并构建函数
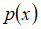
2.对交叉检验集,尝试使用不同的
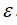
值作为阀值,并预测数据是否异常,根据F1值或者查准率与查全率的比例来选择
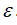
3.选出
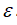
后,针对测试集进行预测,计算异常检验系统的F1值,或者查准率与查全率之比
5 对比
由于构建的异常检测系统也使用的是带标记的数据,与监督学习有些相似,下面的对比有助于选择是采用监督学习还是异常检测:
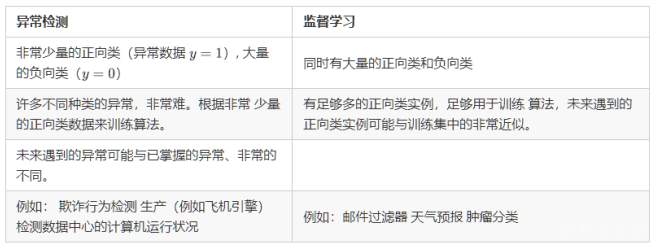
当然,如果遇到正样本的数量很少,甚至为0的情况,通常采用的算法就是异常检测算法啦,因为这时候出现了太多没见过的不同的异常类型。
6 特征的选择
对于异常检测算法,特征的选择是很重要的:
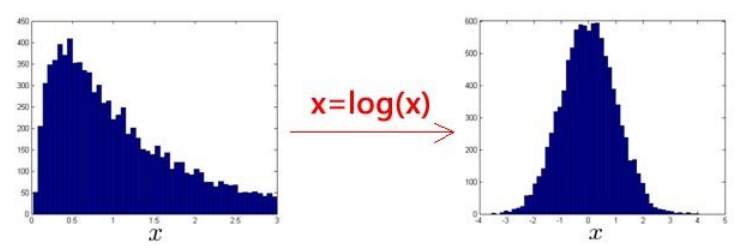
异常检测中的数据集假设特征符合高斯分布,(如果数据的分布不是高斯分布,异常检测算法也可以进行工作,但是通常是将数据转换成高斯分布),例如使用对数函数:
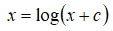
,其中
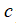
为非负常数; 或者
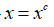
,
为0-1之间的一个分数,等方法。(python中,通常用np.log1p()函数,
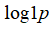
就是
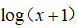
,反向函数就是np.expm1())。
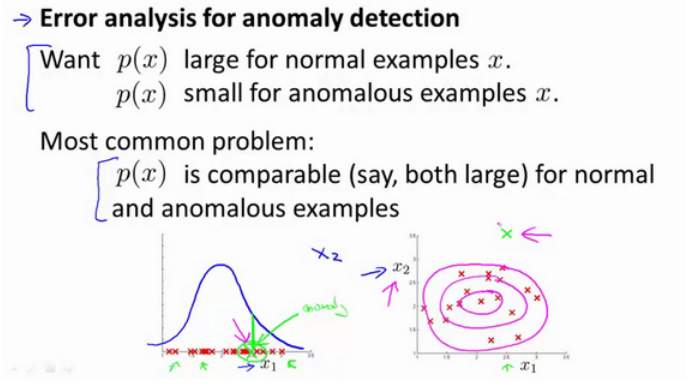
一个常见的问题是一些异常的数据可能也会有较高的
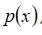
值,从而会被算法认为是正常的。这种情况下误差分析能够帮助我们,我们可以分析那些被算法错误预测为正常的数据,观察能否找出一些问题。可能还会从问题中发现需要增加一些新的特征,增加这些新特征后获得的新算法能够帮助我们更好地进行异常检测。
异常检测误差分析:
通常可以将一些相关的特征进行组合来获得一些新的更好的特征(异常数据的特征值异常地大或小),例如,在检测数据中心的计算机状况时,可以用CPU负载与网络通信量的比例作为一个新的特征,如果该值异常地大,便有可能意味着该服务器是陷入了一些问题中。
在选择特征的时候,其实有时候我们可以对特征进行一些小小的转换,让数据更像正态分布,然后再把数据输入异常检测算法;而误差分析方法也可以捕捉各种异常情况。
今天小Mi先带大家简单了解了异常检测的定义呀,算法呀,如何选择特征呀等等,下期小Mi还要介绍更加复杂的多元高斯分布以及如何使用多元高斯分布进行异常检测呢!好啦,今天的介绍就结束啦~我们下期再见呦!(挥手十分钟)~~
这篇关于【MindSpore:跟着小Mi机器学习】异常检测(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




