本文主要是介绍如何通过绘制【学习曲线】来判断模型是否【过拟合】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
学习曲线是一种图形化工具,用于展示模型在训练集和验证集(或测试集)上的性能随着训练样本数量的增加而如何变化。它可以帮助我们理解模型是否受益于更多的训练数据,以及模型是否可能存在过拟合或欠拟合问题。学习曲线的x轴通常是训练样本的数量或训练迭代的次数,y轴是模型的性能指标,如准确率或损失函数的值。
- 如果模型在训练集上的性能随着训练样本数量的增加而提高,但在验证集上的性能提高不明显或者甚至下降,那么模型可能存在过拟合问题。
- 如果模型在训练集和验证集上的性能都随着训练样本数量的增加而提高,且两者的性能都还有提升的空间,那么模型可能会从更多的训练数据中受益。
- 如果模型在训练集和验证集上的性能都随着训练样本数量的增加而提高,但两者的性能提升已经很小或者没有提升,那么模型可能存在欠拟合问题,或者已经达到了它的性能上限。
在这里,我们以贝叶斯算法为例:
我们先来导入相应的库:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn.datasets import load_digits
from sklearn.model_selection import learning_curve #画学习曲线的类
from sklearn.model_selection import ShuffleSplit #设定交叉验证模式的类
接下来定义一个绘制学习曲线的函数:
def plot_learning_curve(estimator,title, X, y, ax, #选择子图ylim=None, #设置纵坐标的取值范围cv=None, #交叉验证n_jobs=None #设定索要使用的线程):train_sizes, train_scores, test_scores = learning_curve(estimator, X, y,cv=cv,n_jobs=n_jobs) ax.set_title(title)if ylim is not None:ax.set_ylim(*ylim)ax.set_xlabel("Training examples")ax.set_ylabel("Score")ax.grid() #显示网格作为背景,不是必须ax.plot(train_sizes, np.mean(train_scores, axis=1), 'o-', color="r",label="Training score") # 画出训练集学习曲线ax.plot(train_sizes, np.mean(test_scores, axis=1), 'o-', color="g",label="Test score") # 画出验证集学习曲线ax.legend(loc="best")return ax这段代码使用了`learning_curve`函数,该函数是一个非常有用的工具,用于生成学习曲线的数据。学习曲线可以帮助我们理解随着训练样本数量的增加,模型的性能如何变化。
`learning_curve`函数的参数包括:
- `estimator`:这是用于训练的模型。
- `X`和`y`:这是用于训练的数据和对应的标签。
- `cv`:这是交叉验证的策略。
- `n_jobs`:这是用于计算的线程数。
`learning_curve`函数返回三个值:
- `train_sizes`:这是用于生成学习曲线的训练集的样本数。
- `train_scores`:这是在每个训练集大小下,模型在训练集上的得分。
- `test_scores`:这是在每个训练集大小下,模型在交叉验证集上的得分。
这些返回的值可以用于绘制学习曲线,以帮助我们理解模型随着训练样本数量的增加,其性能如何变化。
接下来再导入手写数据集:
digits = load_digits()
X, y = digits.data, digits.target再用如下代码绘制子图和学习曲线:
fig, axes = plt.subplots(1, 1, figsize=(10, 6)) # Define the axes variable
cv = ShuffleSplit(n_splits=50, test_size=0.2, random_state=0)
plot_learning_curve(GaussianNB(), "Naive Bayes", X, y, ax=axes, ylim=[0.7, 1.05], n_jobs=4, cv=cv)
plt.show()
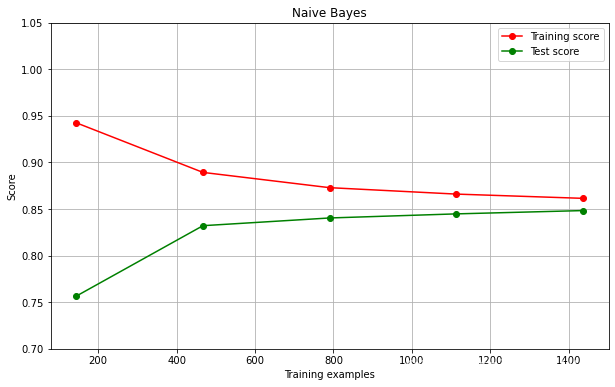
结果分析:可以看出贝叶斯作为一个分类器,效果不是很理想。可以观察到,随着样本量逐渐增大,训练分数逐渐降低,从95%下降到85%,但是测试分数逐渐增高,从75%上升到85%。测试分数在逐渐逼近训练分数,过拟合问题在逐渐减弱。但是,可以想象,接下来即使再增大样本量,测试分数和训练分数也不会变高,只会趋近于某个值。综上所述,朴素贝叶斯是依赖于训练集准确率的下降,测试集准确率上升来解决过拟合问题。
这篇关于如何通过绘制【学习曲线】来判断模型是否【过拟合】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








