本文主要是介绍从Eumetsat批量下载哨兵数据等各种数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
从Eumetsat批量下载哨兵数据等各种数据
那些最好的程序员不是为了得到更高的薪水或者得到公众的仰慕而编程,他们只是觉得这是一件有趣的事情!
批量下载Sentinel数据脚本2023
- 从Eumetsat批量下载哨兵数据等各种数据
- 🌿前言
- 🍀脚本构成
- ClassEumdac.py
- EUMETSATMain.py
- 🌸使用教程
- 🍗设置products_url
- 🍟设置用户参数
- 🍔运行程序
- 🌹结语
📆Date: 2024年1月6日
🎬Author: 小 y 同 学
🔖Language: Python
批量下载Eumetsat官网的数据(Sentinel-3、Sentinel-6等数据产品以及一些气象数据产品)
🌿前言
-
脚本介绍:使用Python+科学上网+多进程,批量下载Eumetsat官网的数据(Sentinel-3、Sentinel-6等数据产品以及一些气象数据产品)
-
Eumetsat官网:https://data.eumetsat.int/search?
-
Eumetsat简介:EUMETSAT(European Organisation for the Exploitation of Meteorological Satellites) 是欧洲气象卫星开发组织,其主要宗旨是建立、维护和运行欧洲的气象卫星系统,其官网不仅仅提供有Sentinel-3、Sentinel-6、Jason-3等卫星数据,还包括其他气象数据产品。具体可以进入官网进行查看。

-
**敬请关注项目Github仓库地址:**https://github.com/cyloveyou/Eumetsat_Download,若后续脚本有更新将同步到Github。
🍀脚本构成
ClassEumdac.py
包含了UserPrint、ProductsInfoFile、SaveParam、UserInfo、ProductInfo四个类。
- UserPrint:包含了一些个性化打印提示函数。
- ProductsInfoFile:主要是从获取的JSON数据提取下载链接、读取下载链接等功能。
- SaveParam:保存参数,包含缓存文件路径和保存路径的创建。
- UserInfo:用户个人信息customer_key、customer_secret、token等
- ProductInfo:对单个产品进行下载。
EUMETSATMain.py
程序入口,包含了一些参数设置,具体设置教程见下文。
🌸使用教程
主要包括设置products_url,设置用户参数。
🍗设置products_url
-
获取products_url,进入EUMETSATM官网https://data.eumetsat.int/search?,选择需要的产品数据文件进行检索,(脚本将会下载检索得到的所有结果)。
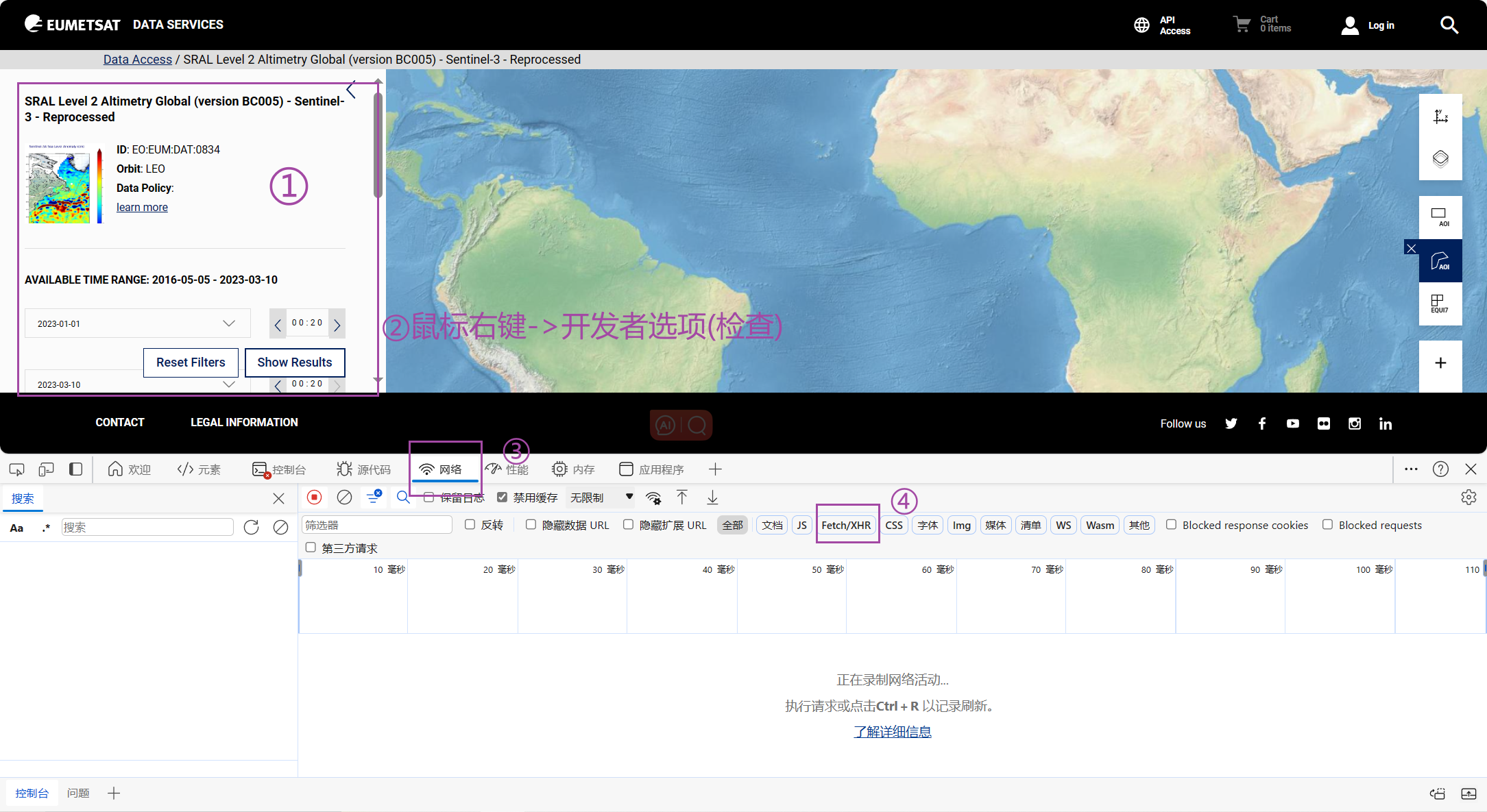
-
获取JSON url
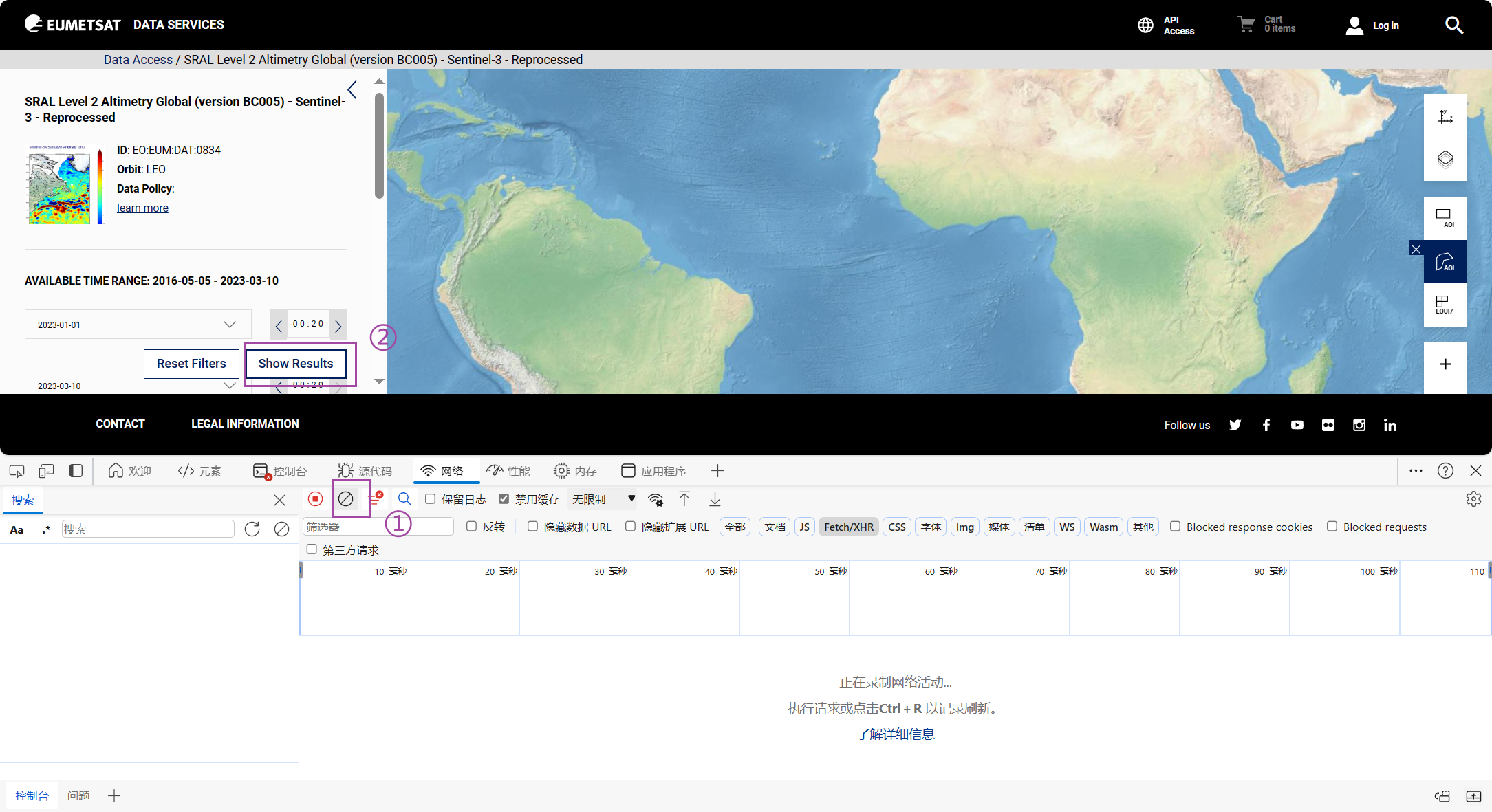
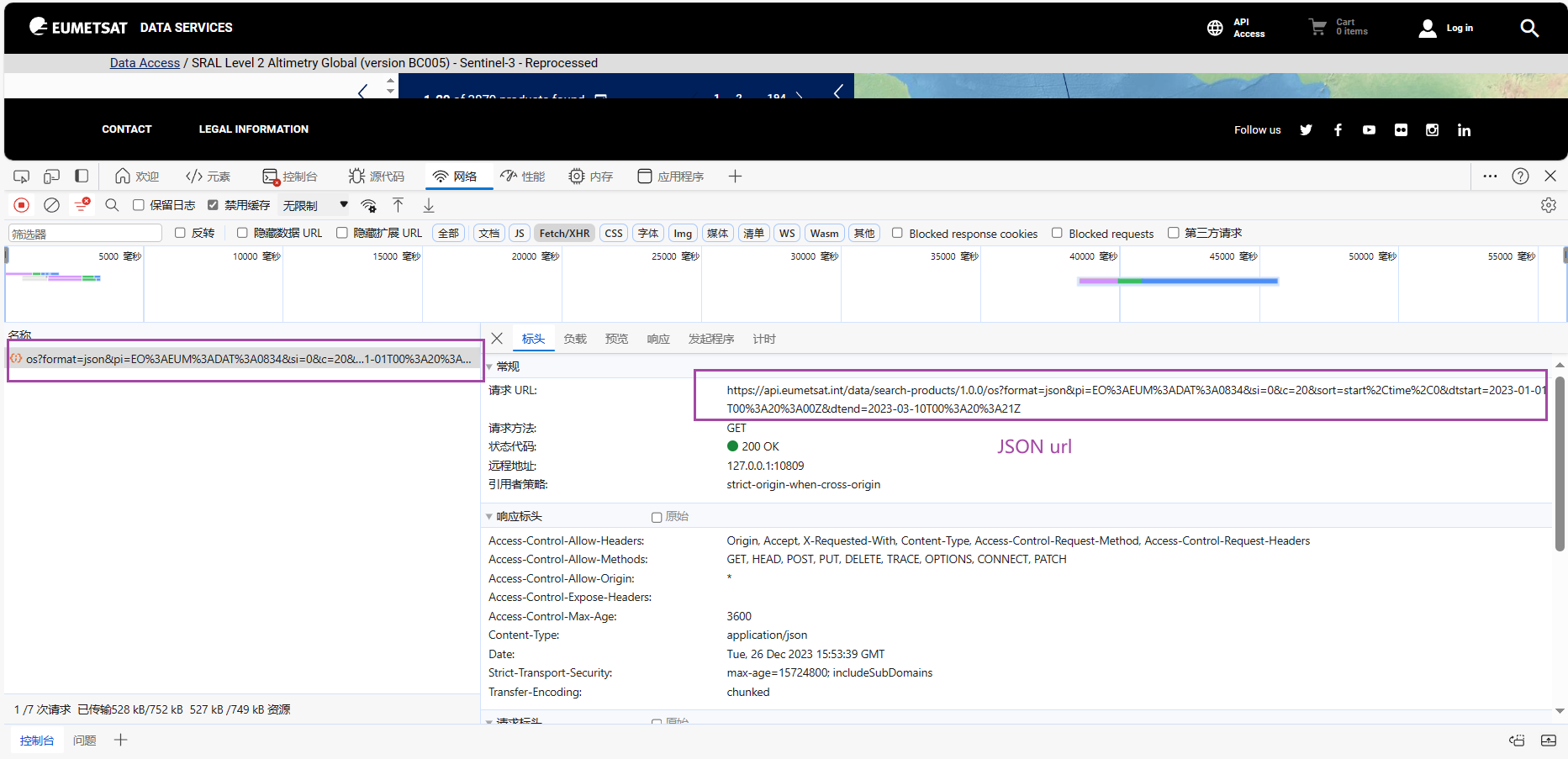
-
将JSON url复制粘贴到products_url.txt文件中

-
至此,products_url设置完成。
🍟设置用户参数
-
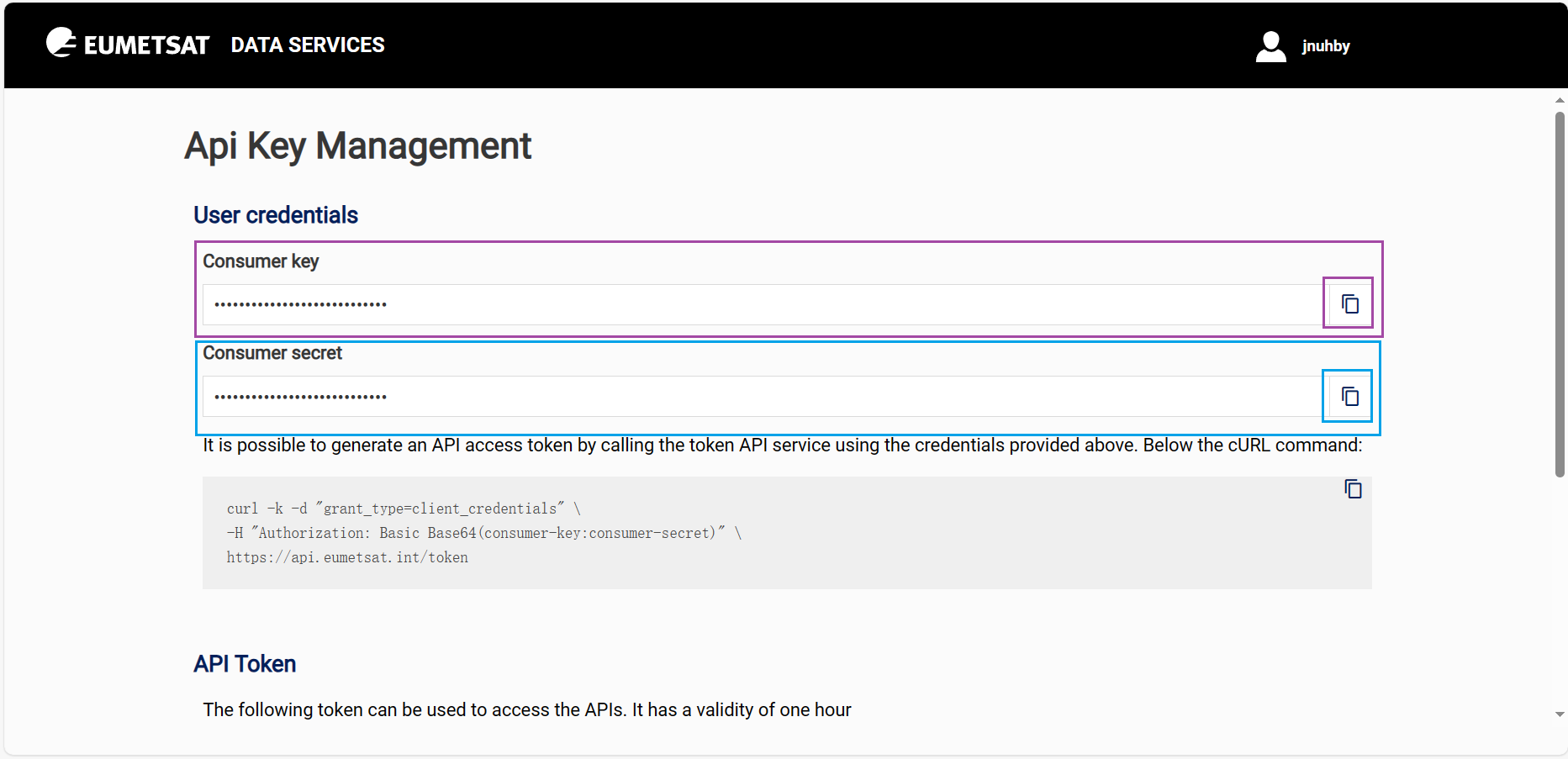
consumer_key和consumer_secret参数设置
登录EUMETSAT,点击API Key,随后即可看到参数,复制替换到脚本
-
products_url_path、products_file_path以及download_path参数设置
products_url_path:是存放JSON url的文件,这里默认为products_url.txt,也就是第一步的.txt文件。
products_file_path:用于存放脚本从JSON url获取的产品下载链接文件,同时也用于下载脚本的输入数据。
download_path:产品保存文件夹,程序会自动以该路径创建缓存文件夹(temp)和完成文件夹(finish),下载完整的数据会被保存到finish文件夹中。
-
IPPort参数设置
IPPort为本地代理参数,开启科学上网,具体八仙过海,此处做不赘述。值得注意的是:需要保证代理流量足够
Windows自带搜索框,搜索Internet属性,按下图操作。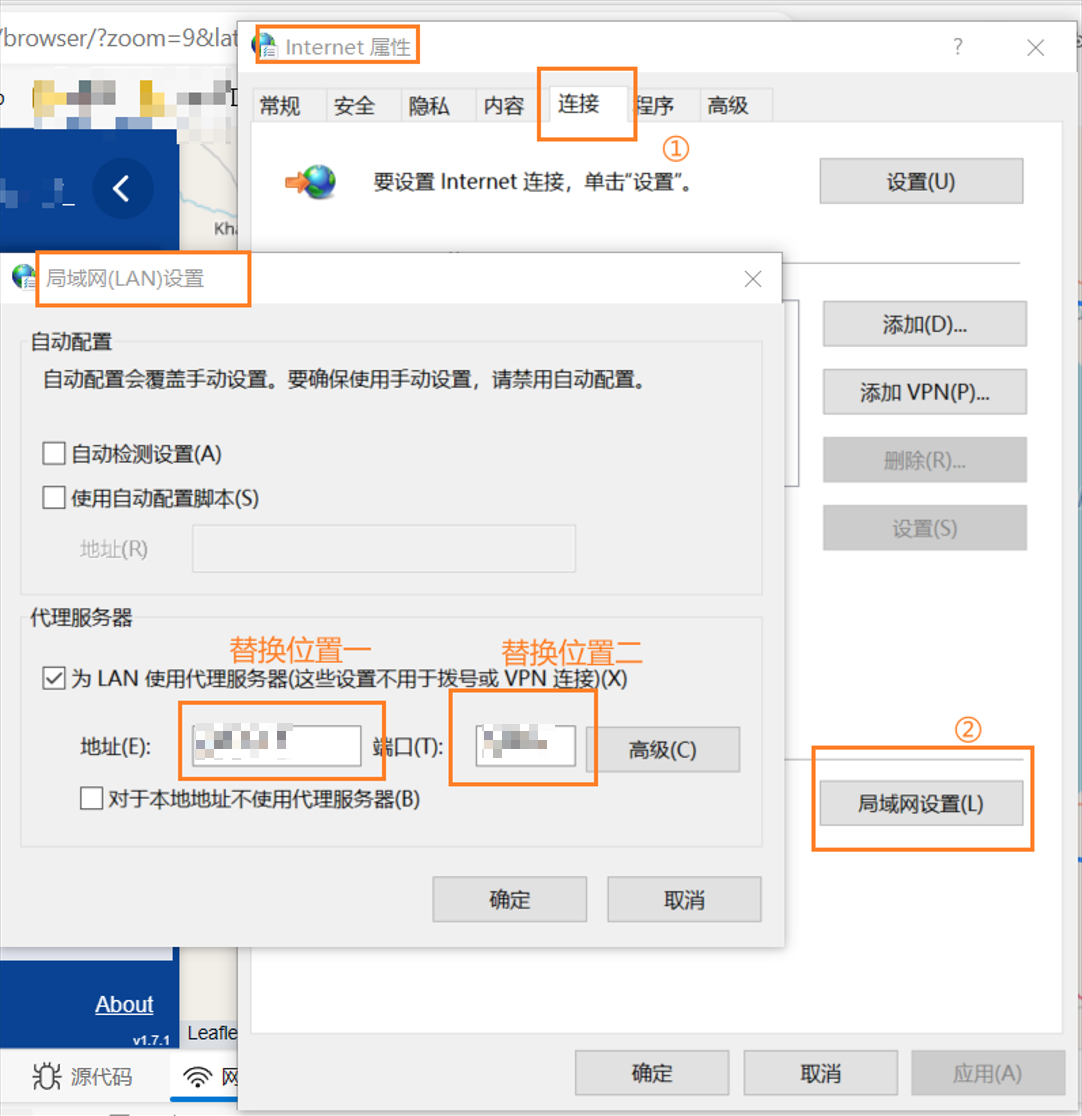
需要注意的是,程序中IPPort写法应为
替换位置一:替换位置二 -
multiN参数设置
multiN为多进程个数参数,一般小于CPU核数,不可过大
🍔运行程序
- 经过上述参数设置完成后,可以运行程序,会出现以下提示:

- 对于下载出错的文件,会提示并随机等待几十秒后重新下载:

- 对于已经存在的文件,会跳过下载:

- 对于Token过期,会重新获取Token并重新下载(这里目前还未遇到,不便截图)
🌹结语
-
项目源码已托管与Github仓库,公众号回复关键字“240101”获取~
-
就目前而言,脚本对于断网、token过期等常见现象抵抗能力良好,还遇到过异常情况,欢迎邮箱私信。
-
对于本脚本,还有很多可以优化的地方,希望大家可以多给些建议,不忘收藏关注😉
-
本人也是测绘遥感方向的学习者,愿意结交志同道合的伙伴,对于脚本的相关问题可在一定程度上提供帮助。
-
脚本进程数不宜设置过大,若修改脚本进程过大放在多核服务器上执行导致对EUMETSAT服务器的攻击行为,本站不承担任何责任。
-
…最终解释权归作者所有。作者邮箱:3232076199@qq.com,烦请说明来意。
-
路虽远,行则将至;事虽难,做则必成。希望认真学习的你能够有所收获~
-
本公众号的原创成果,在未经允许的情况下,请勿用于任何商业用途!
-
如果本文有幸可以帮到您,欢迎您的点赞、收藏与关注;您的点赞、收藏与关注是我创作的最大动力~


这篇关于从Eumetsat批量下载哨兵数据等各种数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








