本文主要是介绍大学英语四、六级考试当次成绩批量查询python脚本,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
问题描述:
已有考生姓名身份证号数据,欲实现四六级成绩批量查询
解决思路:
分析成绩查询网站的请求和响应,利用python实现模拟批量访问,并利用mysql数据库进行存储。 注:上述网站只在发布成绩后一段时间内开放查询。
具体实现:
1.分析查询请求,不难发现
网站通过对https://cjcx.neea.edu.cn/xhtml1/folder/21083/9970-1.htm
(注:网站只在成绩发布的第一天开放免登录查询,其他时间段本文章本方法无效)
发出get请求来获得成绩,请求参数包括km科目,xm姓名,no号码,source来源
但是当我们直接发送get请求却得到了403报错,原因在于网站做了反爬保护,这提醒我们需要添加更多的header信息,经过实验发现决定性的标头字段是
"Referer":"https://cjcx.neea.edu.cn/"
2.分析响应
score 总分,sco_lc 听力,sco_rd 阅读, sco_wt 写译
据上分析,可以构造如下的查询函数
def cet_query(km,name, id):url = "https://cachecloud.neea.cn/api/latest/results/cet"header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.203","Referer":"https://cjcx.neea.edu.cn/"}params = {"km":km, "xm": name, "no":id, "source":"pc"}response = requests.get(url,headers=header,params=params)data = response.json()try: return int(data['score']),int(data['sco_lc']),int(data['sco_rd']),int(data['sco_wt']),idexcept:return ()为了规避学生未报考的情况,我们使用try语句
3.数据库的建立
笔者推荐采用Navicat建立数据库,这比命令行直观得多。表的基本字段如下
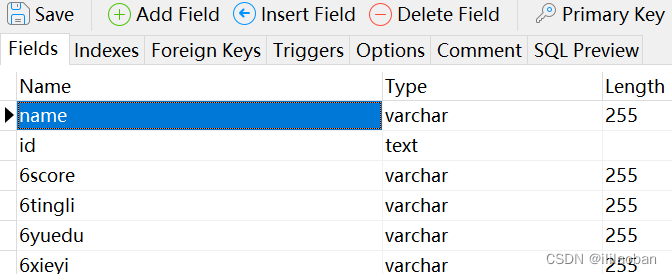
需要注意的是id应当采用text类型,一方面id并非是整数,因为身份证最后一位可能是X;另一方面身份证号较长,text能够满足长度需求。然后就可以导入姓名和身份证号了。
4.写入数据库
接下来就是基本的mysql语句了
def query_write_6():conn = pymysql.connect(host='127.0.0.1',port=3306,user='user',passwd='ps',charset='utf8',db='cet')cursor = conn.cursor() cursor.execute("SELECT name,id FROM my")#获取身份证号和姓名result = cursor.fetchall()score_arry = ()for name,id in result:score_arry=cet_query(2, name,id) #2是cet6,1是cet4if (score_arry != ()):print(score_arry,name)#写入数据库cursor.execute("UPDATE my SET 6score={},6tingli={},6yuedu={},6xieyi={} WHERE id ='{}'".format(*score_arry))conn.commit()上述代码的核心是
cursor.execute("UPDATE my SET 6score={},6tingli={},6yuedu={},6xieyi={} WHERE id ='{}'".format(*score_arry))特别关注 WHERE id = ‘{}’ 有一层单引号,因为id的类型是text,不加单引号mysql会认为是整数类型,在遇到身份证末尾是X时会报错。
总结:
本文实现了CET6的批量查询,cet4同理,留给读者自行实现。
这篇关于大学英语四、六级考试当次成绩批量查询python脚本的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







